




🔥 Firecrawl MCP Server는 웹 스크래핑 기능을 제공하는 Model Context Protocol(MCP) 서버 입니다. 이 도구는 웹 콘텐츠 수집, 검색, 분석을 위한 다양한 기능을 제공하여 연구자, 개발자, 데이터 분석가들에게 강력한 웹 리서치 도구로 활용될 수 있습니다.
현재 오픈소스 AGPL -3.0 (https://github.com/mendableai/firecrawl/blob/main/LICENSE) 으로 제공된 버전과 Cloud 버전을 제공하고 있습니다.
오픈소스와 차이는 다음과 같습니다.
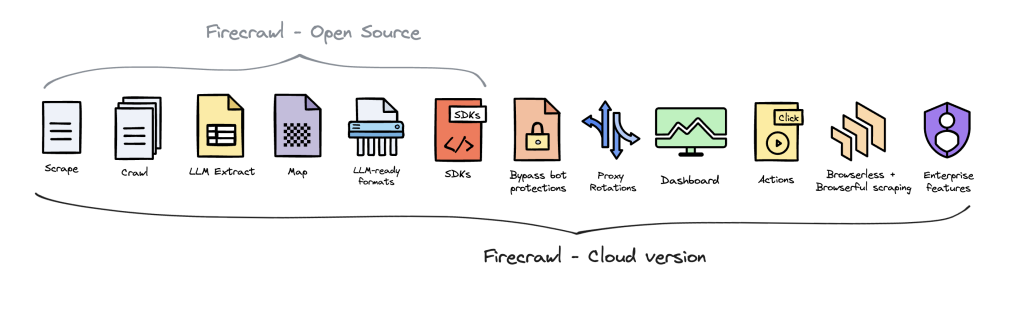
이 글에서는 최근 MCP Server 를 이용한 크롤링에 대한 요구가 많아서, Firecrawl MCP Server의 주요 특징, 설치 방법, 환경설정 옵션, 그리고 리서치 활용 방안에 대해 자세히 알아보겠습니다.

주요 특징
- 웹 스크래핑, 크롤링 및 URL 탐색: 웹사이트의 콘텐츠를 수집하고 구조를 파악
- 검색 및 콘텐츠 추출: 웹에서 특정 정보를 검색하고 관련 콘텐츠 추출
- 심층 리서치 및 배치 스크래핑: 복잡한 주제에 대한 다중 소스 분석 및 대량 데이터 수집
- 자동 재시도 및 속도 제한: 안정적인 데이터 수집을 위한 자동화된 오류 처리
- 클라우드 및 자체 호스팅 지원: 클라우드 API 또는 자체 서버에서 실행 가능
- SSE(Server-Sent Events) 지원: 실시간 데이터 스트리밍 가능
https://www.firecrawl.dev , 회원가입 및 로그인을 통해서 API-Key를 발급받아두세요.
설치 방법
1. npx를 이용한 간편 실행
API 키를 설정하고 npx로 바로 실행할 수 있습니다:
env FIRECRAWL_API_KEY=fc-YOUR_API_KEY npx -y firecrawl-mcp
2. 수동 설치
전역으로 설치하여 사용할 수 있습니다:
npm install -g firecrawl-mcp
3. Remote Hosted URL
발급된 API-Key를 활용하여 MCP서버 URL 자체를 이용할 수도 있습니다.
https://mcp.firecrawl.dev/{FIRECRAWL_API_KEY}/sse
3. Cursor 에디터에서 설정 (v0.48.6)
- Cursor 설정 열기
- Features > MCP Servers로 이동
- “+ Add new global MCP server” 클릭
- 다음 코드 입력:
{
"mcpServers": {
"firecrawl-mcp": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR-API-KEY"
}
}
}
}4. VS Code에서 설치
VS Code의 사용자 설정(JSON)에 다음 블록을 추가합니다:
{
"mcp": {
"inputs": [
{
"type": "promptString",
"id": "apiKey",
"description": "Firecrawl API Key",
"password": true
}
],
"servers": {
"firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "${input:apiKey}"
}
}
}
}
}5. Claude Desktop 에서 설치 (옵션 추가)
{
"mcpServers": {
"mcp-server-firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR_API_KEY_HERE",
"FIRECRAWL_RETRY_MAX_ATTEMPTS": "5",
"FIRECRAWL_RETRY_INITIAL_DELAY": "2000",
"FIRECRAWL_RETRY_MAX_DELAY": "30000",
"FIRECRAWL_RETRY_BACKOFF_FACTOR": "3",
"FIRECRAWL_CREDIT_WARNING_THRESHOLD": "2000",
"FIRECRAWL_CREDIT_CRITICAL_THRESHOLD": "500"
}
}
}
}환경설정 옵션
필수 환경 변수
- FIRECRAWL_API_KEY: Firecrawl API 키 (클라우드 API 사용 시 필수)
- FIRECRAWL_API_URL: 자체 호스팅 인스턴스의 API 엔드포인트 (선택사항)
선택적 환경 변수
재시도 설정
- FIRECRAWL_RETRY_MAX_ATTEMPTS: 최대 재시도 횟수 (기본값: 3)
- FIRECRAWL_RETRY_INITIAL_DELAY: 첫 재시도 전 지연 시간(ms) (기본값: 1000)
- FIRECRAWL_RETRY_MAX_DELAY: 재시도 간 최대 지연 시간(ms) (기본값: 10000)
- FIRECRAWL_RETRY_BACKOFF_FACTOR: 지수 백오프 승수 (기본값: 2)
크레딧 사용량 모니터링
- FIRECRAWL_CREDIT_WARNING_THRESHOLD: 크레딧 사용량 경고 임계값 (기본값: 1000)
- FIRECRAWL_CREDIT_CRITICAL_THRESHOLD: 크레딧 사용량 위험 임계값 (기본값: 100)
설정 예시 (클라우드 API)
# 클라우드 API 필수 설정
export FIRECRAWL_API_KEY=your-api-key
# 선택적 재시도 설정
export FIRECRAWL_RETRY_MAX_ATTEMPTS=5
export FIRECRAWL_RETRY_INITIAL_DELAY=2000
export FIRECRAWL_RETRY_MAX_DELAY=30000
export FIRECRAWL_RETRY_BACKOFF_FACTOR=3
# 선택적 크레딧 모니터링
export FIRECRAWL_CREDIT_WARNING_THRESHOLD=2000
export FIRECRAWL_CREDIT_CRITICAL_THRESHOLD=500
설정 예시 (자체 호스팅)
# 자체 호스팅 필수 설정
export FIRECRAWL_API_URL=https://firecrawl.your-domain.com
# 자체 호스팅 인증 (필요한 경우)
export FIRECRAWL_API_KEY=your-api-key
# 커스텀 재시도 설정
export FIRECRAWL_RETRY_MAX_ATTEMPTS=10
export FIRECRAWL_RETRY_INITIAL_DELAY=500
사용 가능한 도구
Firecrawl MCP Server는 다양한 웹 스크래핑 및 리서치 도구를 제공합니다:
1. Scrape Tool (firecrawl_scrape)
단일 URL에서 콘텐츠를 스크래핑하는 도구입니다. 정확히 어떤 페이지에 정보가 있는지 알 때 유용합니다.
{
"name": "firecrawl_scrape",
"arguments": {
"url": "https://example.com",
"formats": ["markdown"],
"onlyMainContent": true,
"waitFor": 1000,
"timeout": 30000,
"mobile": false,
"includeTags": ["article", "main"],
"excludeTags": ["nav", "footer"],
"skipTlsVerification": false
}
}2. Batch Scrape Tool (firecrawl_batch_scrape)
여러 URL을 효율적으로 스크래핑하는 도구로, 내장된 속도 제한과 병렬 처리 기능을 제공합니다.
{
"name": "firecrawl_batch_scrape",
"arguments": {
"urls": ["https://example1.com", "https://example2.com"],
"options": {
"formats": ["markdown"],
"onlyMainContent": true
}
}
}3. Map Tool (firecrawl_map)
웹사이트의 모든 인덱싱된 URL을 발견하는 도구입니다. 스크래핑 전에 웹사이트의 구조를 파악할 때 유용합니다.
4. Search Tool (firecrawl_search)
웹을 검색하고 선택적으로 검색 결과에서 콘텐츠를 추출하는 도구입니다.
{
"name": "firecrawl_search",
"arguments": {
"query": "your search query",
"limit": 5,
"lang": "en",
"country": "us",
"scrapeOptions": {
"formats": ["markdown"],
"onlyMainContent": true
}
}
}5. Crawl Tool (firecrawl_crawl)
웹사이트에서 비동기 크롤링 작업을 시작하고 모든 페이지에서 콘텐츠를 추출하는 도구입니다.
{
"name": "firecrawl_crawl",
"arguments": {
"url": "https://example.com",
"maxDepth": 2,
"limit": 100,
"allowExternalLinks": false,
"deduplicateSimilarURLs": true
}
}6. Extract Tool (firecrawl_extract)
LLM 기능을 사용하여 웹 페이지에서 구조화된 정보를 추출하는 도구입니다.
{
"name": "firecrawl_extract",
"arguments": {
"urls": ["https://example.com/page1", "https://example.com/page2"],
"prompt": "Extract product information including name, price, and description",
"systemPrompt": "You are a helpful assistant that extracts product information",
"schema": {
"type": "object",
"properties": {
"name": { "type": "string" },
"price": { "type": "number" },
"description": { "type": "string" }
},
"required": ["name", "price"]
},
"allowExternalLinks": false,
"enableWebSearch": false,
"includeSubdomains": false
}
}7. Deep Research Tool (firecrawl_deep_research)
지능형 크롤링, 검색, LLM 분석을 사용하여 심층 웹 리서치를 수행하는 도구입니다.
{
"name": "firecrawl_deep_research",
"arguments": {
"query": "how does carbon capture technology work?",
"maxDepth": 3,
"timeLimit": 120,
"maxUrls": 50
}
}8. Generate LLMs.txt Tool (firecrawl_generate_llmstxt)
특정 도메인에 대한 표준화된 llms.txt 파일을 생성하는 도구입니다.
{
"name": "firecrawl_generate_llmstxt",
"arguments": {
"url": "https://example.com",
"maxUrls": 20,
"showFullText": true
}
}실제 활용 시나리오
시나리오 1: 특정 기술 트렌드 심층 분석
인공지능 윤리에 관한 최신 연구 동향을 파악하기 위해 Deep Research Tool을 활용할 수 있습니다:
{
"name": "firecrawl_deep_research",
"arguments": {
"query": "최신 인공지능 윤리 연구 동향과 규제 프레임워크",
"maxDepth": 3,
"timeLimit": 180,
"maxUrls": 50
}
}이 요청은 관련 학술 사이트, 연구 기관, 뉴스 매체 등에서 정보를 수집하고, 종합적인 분석 결과와 출처 목록을 제공합니다.
시나리오 2: 경쟁사 제품 분석
경쟁사 웹사이트에서 제품 정보를 구조화된 형태로 추출하기 위해 Extract Tool을 활용할 수 있습니다:
{
"name": "firecrawl_extract",
"arguments": {
"urls": ["https://competitor.com/products/product1", "https://competitor.com/products/product2"],
"prompt": "제품 이름, 가격, 주요 기능, 기술 사양을 추출하세요",
"schema": {
"type": "object",
"properties": {
"name": { "type": "string" },
"price": { "type": "number" },
"features": {
"type": "array",
"items": {
"type": "string"
}
},
"specifications": { "type": "object" }
}
}
}
}이 요청은 경쟁사 제품 페이지에서 구조화된 데이터를 추출하여 체계적인 비교 분석이 가능하게 합니다.
결론
Firecrawl MCP Server는 웹 스크래핑, 크롤링, 검색 및 분석을 위한 강력한 도구 모음을 제공합니다. 학술 연구, 시장 조사, 데이터 수집, 콘텐츠 생성 등 다양한 리서치 활동에 활용할 수 있으며, 자동화된 오류 처리와 속도 제한 기능을 통해 안정적인 데이터 수집을 보장합니다.
API 키만 있으면 쉽게 설치하고 사용할 수 있으며, 다양한 환경 변수를 통해 세부적인 설정이 가능합니다. 특히 Deep Research Tool과 Extract Tool은 복잡한 리서치 작업을 자동화하고 구조화된 데이터를 추출하는 데 탁월한 성능을 보여, 연구자와 데이터 분석가에게 큰 도움이 될 것으로 기대 됩니다.
웹 기반 정보 수집과 분석이 필요한 모든 분야에서 Firecrawl MCP Server는 효율성과 생산성을 크게 향상시킬 수 있는 필수 도구라 할 수 있습니다.
답글 남기기