




오늘 기술 파트너 회사와 미팅이 있었습니다. 문서 추출에 대해서 꽤 기술력이 있는 회사여서 관심있게 제품에 대한 소개를 받았습니다. 문서로 부터 데이터를 추출하고, 정제하여 데이터베이스를 구축하는 제품을 가지고 있었습니다.
논문이나 공공기관의 문서의 경우 일관된 형식을 가지고 있기 때문에 형식에 맞는 패턴을 인식하면, 문서로 부터 텍스트를 추출하더라도 정보의 계층구조를 포함된 정보를 가져올수 있는 매우 획기적인 기술이었습니다. 그것을 위해 몇페이지로 부터 입수된 텍스트인지, 텍스트의 크기는 어떤 의미를 갖는지 대분류의 목차의 유형과 모양이 어떤 특징을 갖는지 2단 또는 3단의 구성의 문서 특성인지 등을 구분하여 패턴화된 구조의 문서로 부터 텍스트를 추출합니다.
오늘 우연하게 이러한 구조에 대응할수 있을만한 다국어 문서를 위한 문서 파싱기술을 모델을 사용하여 처리하는 매우 많이 알려진 솔루션이 있어서 포스팅하게 되었습니다.
dots.ocr이 바로 그 것입니다.

dots.ocr이란?
dots.ocr는 RedNote HiLab에서 개발한 멀티모달 비전-언어 모델(VLM) 기반의 통합 문서 파싱 솔루션입니다. 단일 모델 내에서 레이아웃 감지와 콘텐츠 인식을 동시에 수행하며, 올바른 읽기 순서까지 유지하는 혁신적인 접근 방식을 제공합니다.
핵심 특징
최첨단 성능 (SOTA)
SOTA 란?
SOTA는 ‘State of the Art’의 약어로, 분야별 최고를 의미한다.
- OmniDocBench에서 텍스트, 표, 읽기 순서 부문 최고 성능 달성
- Doubao-1.5, Gemini 2.5-pro 같은 대형 모델과 견줄 만한 수식 인식 능력
- 단 1.7B 파라미터로 이룬 놀라운 성능 효율성
강력한 다국어 지원
- 100개 언어를 포함한 자체 다국어 벤치마크에서 압도적 성능
- 저자원 언어에서도 강건한 파싱 능력 보장
- 레이아웃 감지와 콘텐츠 인식 모두에서 결정적 우위
통합되고 단순한 아키텍처
- 복잡한 다단계 파이프라인 대신 단일 VLM 활용
- 프롬프트 변경만으로 작업 전환 가능
- 전통적인 DocLayout-YOLO 같은 감지 모델과 경쟁 가능한 성능
효율적이고 빠른 처리
- 1.7B 컴팩트 LLM 기반으로 빠른 추론 속도
- 대형 모델 대비 월등한 효율성
성능 벤치마크
OmniDocBench 결과 (영어/중국어)
dots.ocr는 다양한 메트릭에서 기존 파이프라인 도구들과 전문 VLM들을 압도하는 성과를 보였습니다:
- 전체 Edit Distance: 0.125 (EN) / 0.160 (ZH)
- 텍스트 Edit Distance: 0.032 (EN) / 0.066 (ZH)
- 표 TEDS: 88.6 (EN) / 89.0 (ZH)
- 읽기 순서 Edit Distance: 0.040 (EN) / 0.067 (ZH)
이는 GPT-4o, Qwen2.5-VL-72B, Gemini 2.5-Pro 등 주요 대형 모델들을 상당한 차이로 앞선 결과입니다.
다국어 성능
자체 다국어 벤치마크(100개 언어, 1,493개 PDF 이미지)에서:
- 전체 Edit Distance: 0.055
- 표 TEDS: 79.2
- Gemini 2.5-Pro (0.251), Doubao-1.5 (0.291) 대비 압도적 성능
주요 기능 및 활용
1. 통합 문서 파싱
- 레이아웃 감지: 텍스트, 표, 수식, 이미지 등 문서 요소 자동 감지
- 콘텐츠 추출: 각 영역별 정확한 텍스트 추출
- 읽기 순서 유지: 인간의 읽기 흐름을 따르는 논리적 순서
2. 다양한 출력 형식 지원
- JSON: 구조화된 레이아웃 정보 (bbox, 카테고리, 텍스트)
- Markdown: 읽기 쉬운 형태로 변환된 문서
- HTML: 표 형식 데이터의 정확한 구조 보존
- LaTeX: 수식의 정밀한 표현
3. 유연한 프롬프트 시스템
# 전체 파싱 (감지 + 인식)
python3 dots_ocr/parser.py demo/demo_image1.jpg
# 레이아웃 감지만
python3 dots_ocr/parser.py demo/demo_image1.jpg --prompt prompt_layout_only_en
# 특정 영역 OCR
python3 dots_ocr/parser.py demo/demo_image1.jpg --prompt prompt_grounding_ocr --bbox 163 241 1536 705
실제 적용 사례
1. 학술 논문 처리
- ArXiv 논문에서 79.1% 성능으로 복잡한 수식과 표 정확 추출
- 다중 컬럼 레이아웃의 올바른 읽기 순서 유지

2. 업무 문서 자동화
- 재무 보고서, 프레젠테이션, 매거진 등 다양한 비즈니스 문서 처리
- 헤더/푸터 자동 제거로 깔끔한 콘텐츠 추출
3. 다국어 문서 처리
- 100개 언어 지원으로 글로벌 비즈니스 환경에 최적
- 저자원 언어에서도 안정적인 성능 보장
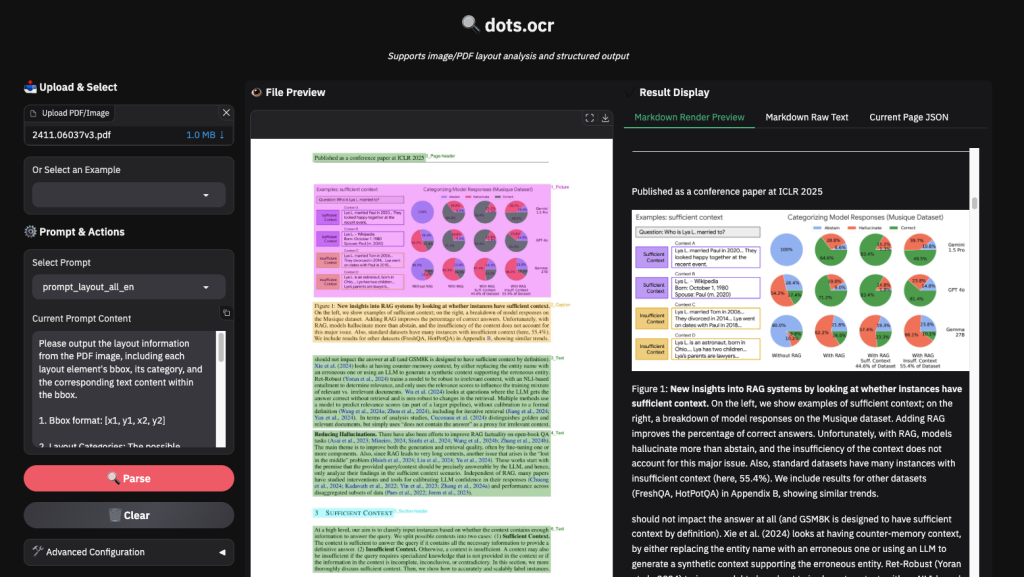
위 링크를 통해서 문서를 업로드 하여 직접 추출해볼수 있습니다. 표, 이미지, 문단 구분, 수식 , 다국어 의 추출이 비교적 높은 수준에서 이루어집니다. 한글 문서의 경우도 꽤 쓸만했습니다.
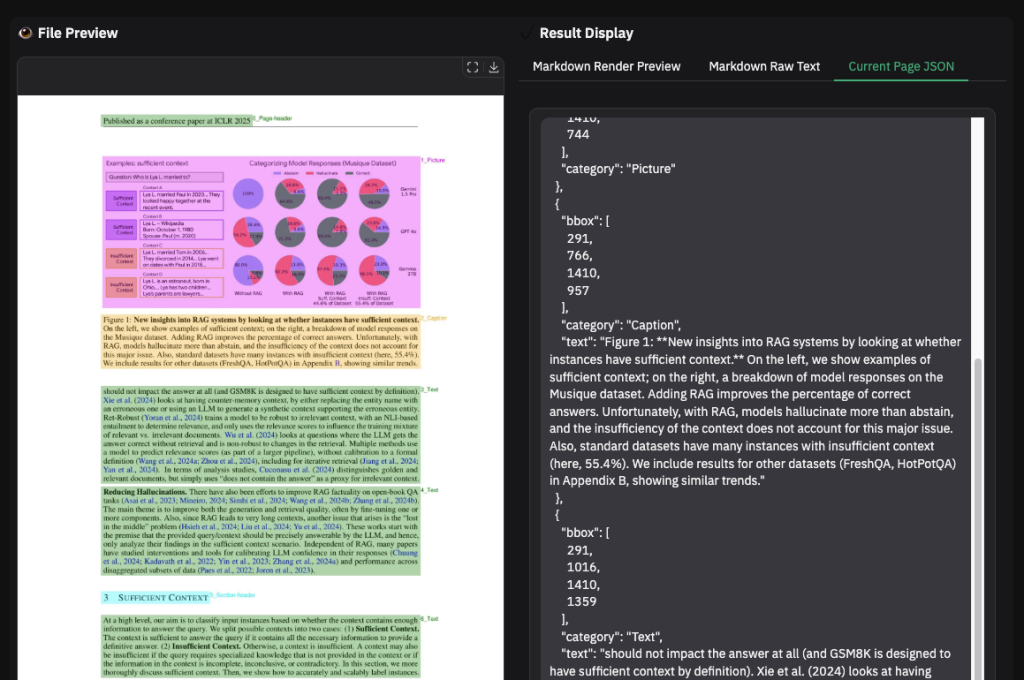
마크다운 추출 이외에도 JSON의 구조화된 데이터 추출도 가능합니다.
설치 및 사용법
환경 설정
conda create -n dots_ocr python=3.12 conda activate dots_ocr git clone https://github.com/rednote-hilab/dots.ocr.git cd dots.ocr # PyTorch 설치 pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu128 pip install -e .
모델 다운로드
python3 tools/download_model.py
vLLM 서버 구동
export hf_model_path=./weights/DotsOCR
export PYTHONPATH=$(dirname "$hf_model_path"):$PYTHONPATH
CUDA_VISIBLE_DEVICES=0 vllm serve ${hf_model_path} \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.95 \
--chat-template-content-format string \
--served-model-name model \
--trust-remote-code
데모 실행
# Gradio 웹 데모
python demo/demo_gradio.py
# 명령줄 파싱
python3 dots_ocr/parser.py demo/demo_image1.jpg
제한사항 및 개선 방향
현재 제한사항
- 복잡한 표와 수식: 고난이도 표와 수식 추출에서 완벽하지 않음
- 이미지 파싱: 문서 내 이미지 콘텐츠는 현재 파싱하지 않음
- 특수 문자: 연속된 특수 문자(…)로 인한 무한 반복 출력 가능성
- 처리량: 대용량 PDF 처리에서 최적화 필요
향후 계획
- 더 정확한 표와 수식 파싱 능력 향상
- 문서 내 이미지 콘텐츠 파싱 기능 추가
- 범용 인식 모델로의 확장 (일반 감지, 이미지 캡셔닝, OCR 통합)
- 고처리량 환경을 위한 성능 최적화
마무리
dots.ocr는 문서 인텔리전스 분야에서 새로운 패러다임을 제시하는 혁신적인 솔루션입니다. 단일 모델로 복잡한 다국어 문서 처리가 가능하며, 1.7B라는 비교적 작은 모델 크기로도 최첨단 성능을 달성했다는 점이 특히 인상적입니다.
특히 한국 기업들이 글로벌 비즈니스를 확장하면서 마주치는 다국어 문서 처리 과제에 dots.ocr가 실질적인 해답이 될 수 있을 것으로 기대됩니다.
문서의 텍스트 추출 및 자동화를 고민 중인 개발자나 연구자라면, GitHub 저장소를 방문해 직접 체험해보시기 바랍니다. 라이브 데모에서도 실시간으로 성능을 확인할 수 있습니다
관련된 라이브 데모는 아래의 링크를 참고해주세요.
https://dotsocr.xiaohongshu.com/
답글 남기기