




RAG(Retrieval-Augmented Generation) 시스템은 외부 문서를 검색하여 LLM의 응답을 향상시키는 핵심 기술로 자리잡았습니다. 이러한 시스템의 성능은 텍스트를 효과적으로 벡터화하는 임베딩 모델의 품질과 효율성에 크게 의존합니다.
지난번 다양한 모델의 임베딩을 지원하기 위한 ONNX를 소개한적이 있는데요. Hugging Face에서 개발한 Text Embeddings Inference(TEI)는 오픈소스 임베딩 모델들을 효율적으로 배포하고 서비스할 수 있는 강력한 툴킷을 소개하려고 합니다. 본 글에서는 RAG 시스템에서 TEI를 활용하는 방법과 추가로 기존의 OpenAI API 및 Ollama와 비교하여 어떤 장점이 있는지 살펴보겠습니다.
Text Embeddings Inference란?
TEI는 FlagEmbedding, Ember, GTE, E5 등 인기 있는 오픈소스 임베딩 모델들의 고성능 추론을 위해 특별히 설계된 도구입니다. 프로덕션 환경에서의 효율적인 배포와 서비스를 목표로 하며, 다양한 최적화 기술을 통해 뛰어난 성능을 제공합니다.
특히 GPU 리소스를 사용한 임베딩은 그 처리 속도면에서 탁월한 효과가 있으므로, 다량의 동시수행의 성능 이슈가 요구될 때 검토하면 좋을 것 같습니다.
TEI의 핵심 특징
1. 간편한 배포
- 모델 그래프 컴파일 단계 불필요
- Docker를 통한 원클릭 배포
- 다양한 하드웨어 아키텍처 지원 (CPU, GPU)
2. 효율적인 리소스 활용
- 작은 크기의 Docker 이미지
- 빠른 부팅 시간으로 서버리스 환경 지원
- 토큰 기반 동적 배칭으로 처리량 최적화
3. 최적화된 추론
- Flash Attention 활용
- Candle과 cuBLASLt를 이용한 최적화된 트랜스포머 코드
- Safetensors를 통한 빠른 가중치 로딩
4. 프로덕션 지원 기능
- Open Telemetry를 통한 분산 추적
- Prometheus 메트릭 내보내기
- 재순위(Re-ranking) 및 시퀀스 분류 모델 지원
RAG 시스템에서의 TEI 활용
1. 기본 설정 및 배포
TEI를 RAG 시스템에 통합하는 가장 간단한 방법은 Docker를 활용하는 것입니다.
# 고성능 임베딩 모델 배포
model=BAAI/bge-large-en-v1.5
volume=$PWD/data
docker run --gpus all -p 8080:80 -v $volume:/data --pull always \
ghcr.io/huggingface/text-embeddings-inference:1.7 --model-id $model
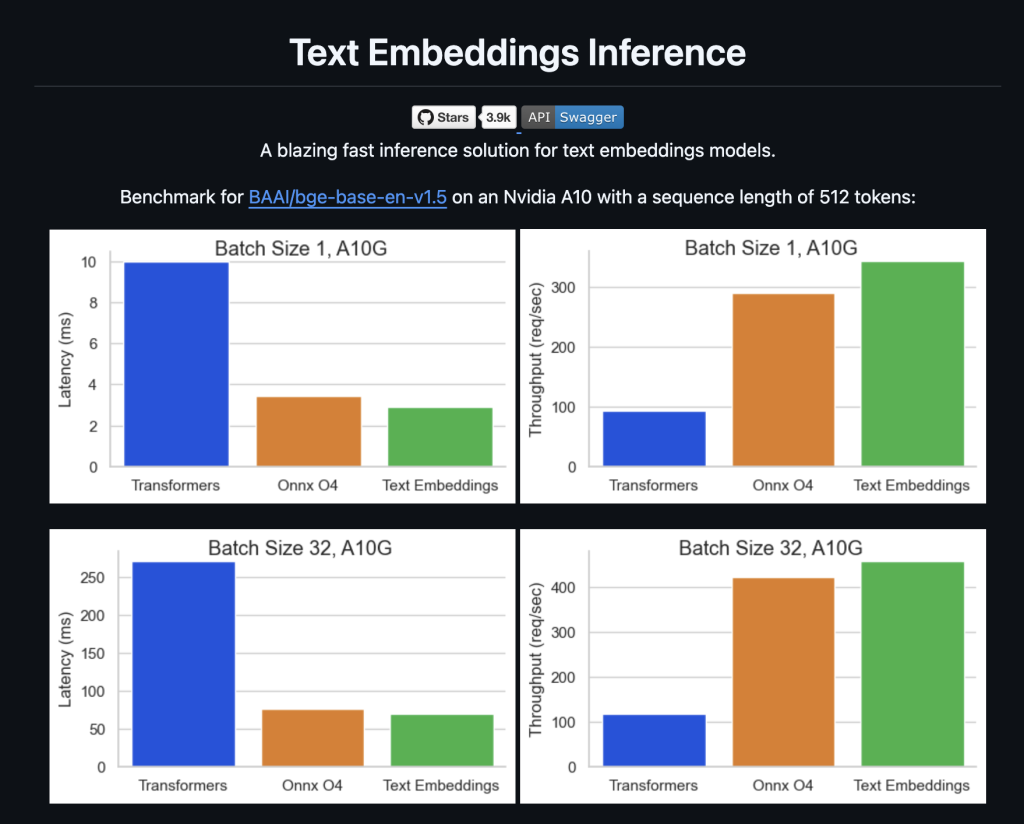
이 명령어로 BGE-large 모델을 GPU에서 서비스할 수 있으며, 벤치마크에 따르면 NVIDIA A10에서 512 토큰 시퀀스 기준으로 우수한 성능을 보여줍니다.
2. RAG 파이프라인 통합
TEI는 여러 방식으로 RAG 시스템에 통합할 수 있습니다:
Python SDK를 통한 통합:
from huggingface_hub import InferenceClient
# TEI 클라이언트 초기화
client = InferenceClient()
# 문서 임베딩 생성
documents = [
"RAG는 검색 증강 생성의 줄임말입니다.",
"임베딩은 텍스트를 벡터로 변환하는 과정입니다.",
"TEI는 효율적인 임베딩 추론을 제공합니다."
]
embeddings = []
for doc in documents:
embedding = client.feature_extraction(doc,
model="http://localhost:8080/embed")
embeddings.append(embedding[0])
배치 처리 지원:
TEI의 동적 배칭 기능을 활용하면 대량의 문서를 효율적으로 처리할 수 있습니다:
curl 127.0.0.1:8080/embed \
-X POST \
-d '{"inputs":["문서 1", "문서 2", "문서 3"]}' \
-H 'Content-Type: application/json'
3. 재순위(Re-ranking) 활용
TEI는 임베딩뿐만 아니라 재순위 모델도 지원합니다. 이는 RAG 시스템의 검색 품질을 크게 향상시킬 수 있습니다:
# 재순위 모델 배포
model=BAAI/bge-reranker-large
docker run --gpus all -p 8081:80 -v $volume:/data --pull always \
ghcr.io/huggingface/text-embeddings-inference:1.7 --model-id $model
# 재순위 수행
curl 127.0.0.1:8081/rerank \
-X POST \
-d '{"query":"딥러닝이란?", "texts": ["머신러닝의 한 분야...", "딥러닝은 신경망..."]}' \
-H 'Content-Type: application/json'
경쟁 솔루션과의 비교
OpenAI API vs TEI
OpenAI API의 장점:
- 즉시 사용 가능, 설정 불필요
- 지속적인 모델 업데이트
- 높은 안정성과 가용성
- text-embedding-3-large 등 고성능 모델
TEI의 장점:
- 비용 효율성: 자체 호스팅으로 API 호출 비용 절감
- 데이터 프라이버시: 외부로 데이터 전송하지 않음
- 커스터마이징: 특정 도메인에 최적화된 모델 선택 가능
- 오프라인 배포: 네트워크 연결 없이도 동작
성능 비교:
# 비용 예시 (가정)
# OpenAI: 1M 토큰당 $0.10
# TEI: GPU 인스턴스 월 $200 (무제한 사용)
# 월 10M 토큰 처리 시
# OpenAI: $1,000
# TEI: $200 (66% 절약)
Ollama vs TEI
Ollama의 장점:
- 통합된 LLM 및 임베딩 모델 관리
- 간단한 CLI 인터페이스
- 로컬 개발에 최적화
TEI의 장점:
- 임베딩에 특화된 최적화
- 프로덕션 환경에 적합한 기능들
- 더 나은 배치 처리 성능
- 상세한 모니터링 및 메트릭
배포 복잡도 비교:
# Ollama ollama pull nomic-embed-text ollama run nomic-embed-text # TEI docker run --gpus all -p 8080:80 \ ghcr.io/huggingface/text-embeddings-inference:1.7 \ --model-id nomic-ai/nomic-embed-text-v1
실제 RAG 시스템 구현 예제
다음은 TEI를 활용한 완전한 RAG 시스템 예제입니다:
import requests
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
class TEI_RAG_System:
def __init__(self, tei_endpoint="http://localhost:8080"):
self.tei_endpoint = tei_endpoint
self.documents = []
self.embeddings = []
def add_documents(self, docs):
"""문서 추가 및 임베딩 생성"""
response = requests.post(
f"{self.tei_endpoint}/embed",
json={"inputs": docs},
headers={"Content-Type": "application/json"}
)
new_embeddings = response.json()
self.documents.extend(docs)
self.embeddings.extend(new_embeddings)
def retrieve(self, query, top_k=3):
"""쿼리에 대한 관련 문서 검색"""
# 쿼리 임베딩 생성
response = requests.post(
f"{self.tei_endpoint}/embed",
json={"inputs": [query]},
headers={"Content-Type": "application/json"}
)
query_embedding = response.json()[0]
# 유사도 계산
similarities = cosine_similarity(
[query_embedding],
self.embeddings
)[0]
# Top-k 문서 반환
top_indices = np.argsort(similarities)[-top_k:][::-1]
return [
(self.documents[i], similarities[i])
for i in top_indices
]
성능 최적화 팁
1. 하드웨어 선택
TEI는 다양한 GPU 아키텍처를 지원하며, 각각에 최적화된 Docker 이미지를 제공합니다:
- A100/A30:
ghcr.io/huggingface/text-embeddings-inference:1.8 - A10/A40:
ghcr.io/huggingface/text-embeddings-inference:86-1.8 - RTX 4000 시리즈:
ghcr.io/huggingface/text-embeddings-inference:89-1.8 - CPU:
ghcr.io/huggingface/text-embeddings-inference:cpu-1.8
2. 배치 크기 최적화
대량의 문서를 처리할 때는 배치 처리를 활용하여 처리량을 극대화할 수 있습니다:
# 비효율적: 개별 처리
for doc in documents:
embedding = get_embedding(doc)
# 효율적: 배치 처리
batch_size = 32
for i in range(0, len(documents), batch_size):
batch = documents[i:i+batch_size]
embeddings = get_embeddings_batch(batch)
3. 모델 선택
MTEB 리더보드를 참고하여 용도에 맞는 모델을 선택하세요:
- 다국어 지원:
intfloat/multilingual-e5-large-instruct - 영어 특화:
BAAI/bge-large-en-v1.5 - 코드 임베딩:
jinaai/jina-embeddings-v2-base-code - 경량화:
Qwen/Qwen3-Embedding-0.6B
모니터링 및 운영
TEI는 프로덕션 환경에서 필요한 다양한 모니터링 기능을 제공합니다:
# Prometheus 메트릭 확인
curl http://localhost:8080/metrics
# 헬스체크
curl http://localhost:8080/health
주요 모니터링 지표:
- 처리량 (requests per second)
- 지연시간 (latency)
- GPU/CPU 사용률
- 메모리 사용량
- 오류율
결론
Text Embeddings Inference는 RAG 시스템에서 임베딩 처리를 위한 강력하고 효율적인 솔루션입니다. OpenAI API와 비교했을 때 비용 효율성과 데이터 프라이버시 측면에서, Ollama와 비교했을 때 프로덕션 환경에 특화된 기능들에서 명확한 장점을 보여줍니다.
특히 다음과 같은 경우에 TEI 도입을 적극 권장합니다:
- 대량의 임베딩 처리가 필요한 경우
- 비용 최적화가 중요한 프로젝트
- 데이터 보안이 핵심 요구사항인 환경
- 커스텀 모델 활용이 필요한 상황
- 오프라인 배포가 요구되는 환경
TEI를 통해 더욱 효율적이고 비용 효과적인 RAG 시스템을 구축하시기 바랍니다. 지속적인 발전을 이루고 있는 오픈소스 생태계의 장점을 최대한 활용하여, 더 나은 AI 애플리케이션을 개발할 수 있을 것입니다.
참고 링크 : https://huggingface.co/docs/text-embeddings-inference/index
답글 남기기