




웹서핑을 하다보면 데이터 수집을 직접 해야 하는경우들이 종종 있는데, 데이터 양이 많지 않은 경우에 크롤링 도구를 직접 제작하는 것이 번거롭다는 생각이 들었습니다. 물론 요즘은 크롤링 도구도 프롬프트 몇줄이면 금방 파이썬 코드를 제공해주기 때문에 별것 아닌것 같더라도, 실제 사이트와 싱크를 맞춰서 완벽한 툴을 만드는 것은 여간 귀찮은 일은 아닙니다.
때문에 브라우저에서 확장 프로그램을 이용해서 간단하게 데이터를 수집하여 csv파일로 생성해주는 도구를 만들어보기로 하였습니다. 직접 코드를 만드는데 있어서는 배움 및 오류의 시간을 지나야 하기 때문에 Gemini의 도움을 받아 만들었습니다.
만들 프로그램은 웹데이터 수집기 (Scraper) 입니다.
브라우저에서 보여지는 데이터들을 수집하는 도구 입니다. 물론 Copy & Paste를 하면 되지만, 유형을 정해 놓고, 페이지를 이동하면서 미리 정해둔 영역의 이미지 경로, 링크, 타이틀, 메타데이터 등을 수집하여 최종 CSV파일로 내려 받을수 있도록 하는 것입니다.
이름 K-Scraper 입니다. -_-; K는 Korea 의 K 아닙니다.
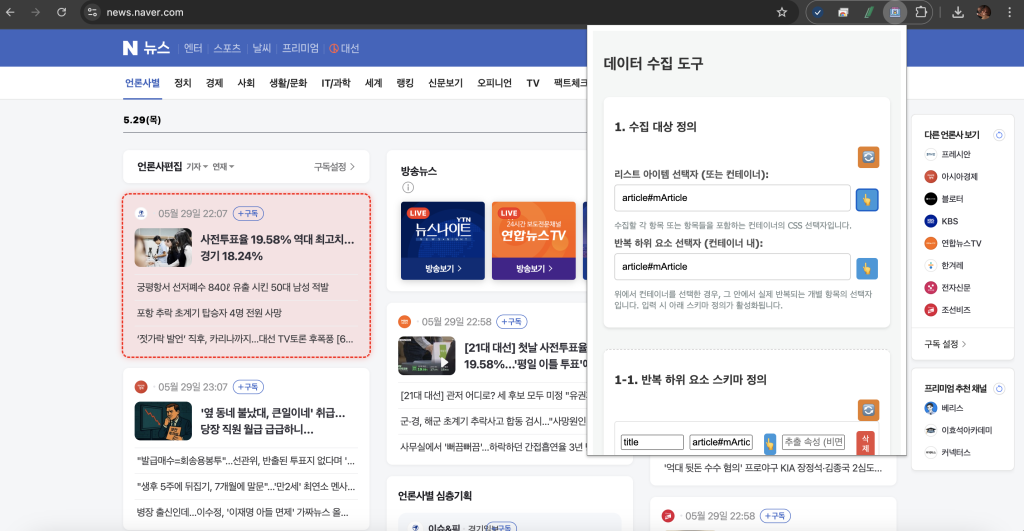
방식은 간단합니다. 데이터를 수집할 페이지에 접속하고, 크롬 확장 프로그램을 띄워서, 수집할 영역, 반복될 영역, 세부 영역을 지정하고, 수집하면 됩니다.
목표시스템
웹스크랩을 해주는 구글 크롬 익스텐션 프로그램 만들기
주요 기능
브라우저에서 보여지는 화면에서 지정한 영역의 웹 데이터를 CSV 파일로 추출해내기
기대 동작방식
- 브라우저를 열어 웹서핑을 함
- 웹페이지 중에 데이터 스크랩이 필요한 영역을 브라우저에서 직접 선택
- 선택된 그 안에서 반복적으로 가져올 요소를 선택
- 반복요소를 HTML 자체로 다운로드 받을수도 있지만, 반복요소에서 타이틀, 이미지, 링크… 등 지정된 스키마로 정의해서 CSV로 만들고 싶다면, 반복요소를 지정하기
- 페이지 구조의 패턴으로 1페이지에서 100 페이지를 가져오는 주소 기반의 패턴일지, 특정 버튼(ex:다음 버튼) 을 클릭해서 이동 후 동일한 HTML영역의 데이터를 가져오기
- 수집된 HTML을 CSV데이터 구조로 다운로드 하기
이러한 기능의 도구는 Listly. 등 이미 많은 도구들이 있습니다만, 페이징이 안되거나, 유료서비스 이거나 등의 프로그램을 사용하는데 제약이 있어서 만들어 두면 언제든 사용할 일이 있을것 같습니다.
파일 구조
파일 구조는 구글 크롬 익스텐션에 요구되는 기준에 맞춰 만들어졌습니다.
manifest V3 기반으로, 비동기, 이벤트 기능을 주로 활용하였습니다.
참고 : https://developer.chrome.com/docs/extensions/get-started?hl=ko
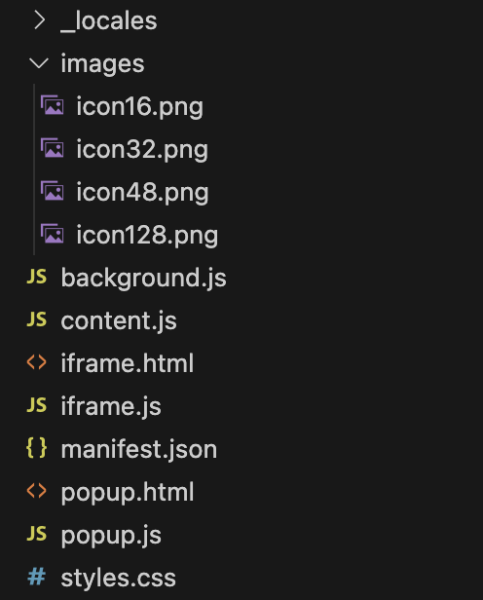
manifest.json : 확장 프로그램에 대한 정보를 기본적으로 담고 있으며, V3 기준입니다.
background.js : 데이터 수집 프로세스 관리, 페이지 이동, 데이터 저장 등 핵심 로직을 처리하는 엔진 역할을 합니다.
content.js : 실제 웹 페이지에 삽입되어 페이지의 DOM과 상호작용합니다. 설정 UI(iframe)를 페이지에 삽입하고, 요소 선택(Picker) 기능을 담당하며, 백그라운드 스크립트의 지시를 받아 스크래핑을 실행합니다.
iframe.js, iframe.html : 사용자가 데이터 수집 규칙(CSS 선택자, 스키마, 페이지네이션)을 설정하는 메인 인터페이스입니다. content.js 의해 페이지 내에 삽입됩니다.
popup.js, popup.html : 사용자가 확장 프로그램 아이콘을 클릭했을 때 나타나는 작은 창으로, 설정 UI를 열고 닫는 역할만 합니다.
/_locales/{code}/messages.json : UI에 표시되는 모든 텍스트를 관리하며, i18n을 사용한 다국어 관리 환경을 가졌으며, 현재 한국어 외 9개국어 지원합니다.
styles.css : 설정 UI와 요소 선택 시의 하이라이트 등 확장 프로그램의 모든 시각적 요소를 정의합니다.
웹브라우저를 통해서 선택된 데이터를 로컬 스토리지에 저장을 하다보니 저장한계에 다다르기도 합니다. 최신 브라우저 기반에서 10MB까지( 구버전은 5MB)이므로, 아무리 텍스트라도 최대 수집에 대한 제한이 불가피합니다. 이 부분은 이 툴의 제한 사항입니다.
간단한 사용방법
이 방식 이외에도, 서핑을 하면서 레이어팝업이 항상 따라다니므로, 뉴스기사 스크랩핑을 위해 반복유형을 사전에 정의해두었다면, 뉴스 사이트 내에서 이동하면서 기사 상세페이지를 열어 놓고, 기사 데이터를 append 하면서 스크랩을 하시면 좀더 쉽게 원하는 데이터만 수집할 수 있습니다.
결론
혹시 누군가에게도 필요할수 있으므로 테스트를 좀 더 해보고 크롬 익스텐션 플랫폼에 올려 보려고 합니다.
업데이트가 되는데로 링크 공유하겠습니다.
업데이트 (2025.6.12) : 마켓에 등록이 완료되어 링크공유 합니다.
https://chromewebstore.google.com/detail/abbegbpklgikodalooeldjjnblgjnjjj
시간이 허락하는데로 업데이트 해서 좀 더 쓸만하게 만들어가도록 하겠습니다. 많은 관심 부탁드리며, 의견 있으시면 무엇이든 보내주세요.
https://blog.choonzang.com/contact/
답글 남기기