




RAG 시스템 구축을 하면서 데이터를 벡터 스토어로 저장을 할때, 일정 길이로 청킹을 해서 임베딩후 저장을 하다보니, 검색을 통해서 검출된 문서 자체가 검색과 밀접한 관련이 있는 단어들만 나오게 됩니다. 결국 그 안에서 답변이 이루어 지기 떄문에 단편적인 질문에 따른 결과는 만족스럽더라도, 전체적인 맥락에 대한 이해가 요구되는 질문에는 그렇지 못합니다.
예를 들자면, 신데렐라가 어려서 부모님을 잃고, 자매로 부터 양부모로 부터 부당한 대우를 받고, 파티에 참석하고 싶은데 못가고, 시간에 쫓겨 신발을 잃어 버린 상태로 도망치듯 파티장을 나왔는데… 결국 왕자님을 만나 행복했다라는 이야기가 말미에 나옵니다. 단편적인 이야기로는 전반적으로 신데렐라는 불행한 여자로 보입니다만, 이러한 문제로 부터 행복해진다는 결과을 가지고 있습니다. 전체적인 담론으로 큰 흐름에 대한 이해가 필요합니다. 그것을 해결해 줄 수 있는 자료를 최근 지인으로 부터 소개를 받아서 잠시 내용을 살펴 보았습니다.
대규모 언어 모델(LLM)이 발전함에 따라 긴 문서나 여러 문서를 효과적으로 처리하는 방법에 대한 관심을 대변하듯, 수천 페이지에 달하는 문서나 책, 논문 모음 등을 처리할 때 모델의 컨텍스트 제한은 큰 이슈가됩니다. 이러한 문제를 해결하기 위한 방법 중 하나가 “Recursive Abstractive Processing for Tree-Organized Retrieval” 논문에서 제시된 접근법입니다.
Recursive Abstractive Processing for Tree-Organized Retrieval (RAPTOR)
RAPTOR는 긴 문서를 효율적으로 처리하기 위한 계층적 접근 방식입니다. 간단하게 설명하자면 이 방법은 문서를 작은 청크로 나누고, 각 청크에 대한 요약(추상화)을 생성한 다음, 이러한 요약들을 트리 구조로 조직하여 정보를 효율적으로 검색하고 처리할 수 있게 합니다.
RAPTOR의 주요 단계는 다음과 같습니다:
- 문서를 관리 가능한 크기의 청크로 분할
- 각 청크에 대한 추상적 요약 생성
- 요약들을 계층적 트리 구조로 클러스터링 구성
- 트리 및 레벨 구조를 활용한 효율적인 정보 검색
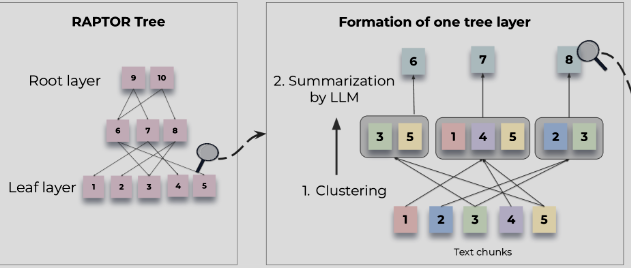
이러한 접근 방식은 전체 문서를 한 번에 처리하는 대신, 필요한 부분만 선택적으로 접근할 수 있게 해줍니다.
Python으로 RAPTOR 구현하기
아래는 RAPTOR을 Python으로 구현한 예제 코드입니다:
import openai
import textwrap
from typing import List, Dict, Any, Optional
import numpy as np
# OpenAI API 설정
openai.api_key = "your-api-key"
class RAPNode:
def __init__(self, content: str, level: int, parent=None):
self.content = content
self.summary = None
self.level = level
self.parent = parent
self.children = []
self.embedding = None
def add_child(self, child):
self.children.append(child)
child.parent = self
def generate_summary(self):
if not self.children: # 리프 노드인 경우
self.summary = self._summarize_content(self.content)
else: # 내부 노드인 경우
child_summaries = [child.summary for child in self.children]
combined_summary = "\n".join(child_summaries)
self.summary = self._summarize_content(combined_summary)
return self.summary
def _summarize_content(self, text: str) -> str:
"""OpenAI API를 사용하여 텍스트 요약"""
try:
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "다음 텍스트의 핵심 내용을 200단어 이내로 요약해주세요."},
{"role": "user", "content": text}
],
max_tokens=300,
temperature=0.3
)
return response.choices[0].message.content.strip()
except Exception as e:
print(f"요약 생성 중 오류 발생: {e}")
return "요약 생성 실패"
def generate_embedding(self):
"""텍스트에 대한 임베딩 생성"""
if self.summary:
try:
response = openai.Embedding.create(
model="text-embedding-ada-002",
input=self.summary
)
self.embedding = response['data'][0]['embedding']
except Exception as e:
print(f"임베딩 생성 중 오류 발생: {e}")
self.embedding = None
return self.embedding
class RAP:
def __init__(self, max_chunk_size: int = 2000):
self.max_chunk_size = max_chunk_size
self.root = None
def process_document(self, document: str):
"""문서를 처리하여 RAP 트리 구조 생성"""
# 문서를 청크로 분할
chunks = self._split_into_chunks(document)
# 리프 노드 생성
leaf_nodes = [RAPNode(chunk, level=0) for chunk in chunks]
# 트리 구조 구축
self.root = self._build_tree(leaf_nodes)
# 요약 생성 (상향식)
self._generate_summaries(self.root)
# 임베딩 생성
self._generate_embeddings(self.root)
return self.root
def _split_into_chunks(self, document: str) -> List[str]:
"""문서를 관리 가능한 크기의 청크로 분할"""
return textwrap.wrap(document, self.max_chunk_size, break_long_words=False, replace_whitespace=False)
def _build_tree(self, nodes: List[RAPNode], level: int = 0, max_children: int = 4) -> RAPNode:
"""노드 리스트로부터 계층적 트리 구조 구축"""
if len(nodes) <= max_children:
# 상위 노드 생성
parent = RAPNode("", level + 1)
for node in nodes:
parent.add_child(node)
return parent
# 노드를 그룹으로 분할
groups = [nodes[i:i+max_children] for i in range(0, len(nodes), max_children)]
# 각 그룹에 대한 부모 노드 생성
parent_nodes = []
for group in groups:
parent = RAPNode("", level + 1)
for node in group:
parent.add_child(node)
parent_nodes.append(parent)
# 재귀적으로 트리 구축 계속
return self._build_tree(parent_nodes, level + 1, max_children)
def _generate_summaries(self, node: RAPNode):
"""트리의 모든 노드에 대한 요약 생성 (상향식)"""
for child in node.children:
self._generate_summaries(child)
node.generate_summary()
def _generate_embeddings(self, node: RAPNode):
"""트리의 모든 노드에 대한 임베딩 생성"""
node.generate_embedding()
for child in node.children:
self._generate_embeddings(child)
def query(self, query_text: str, top_k: int = 3) -> List[str]:
"""쿼리와 가장 관련성 높은 청크 검색"""
# 쿼리 임베딩 생성
try:
response = openai.Embedding.create(
model="text-embedding-ada-002",
input=query_text
)
query_embedding = response['data'][0]['embedding']
except Exception as e:
print(f"쿼리 임베딩 생성 중 오류 발생: {e}")
return []
# 트리를 순회하며 관련 노드 찾기
relevant_chunks = self._search_tree(self.root, query_embedding, top_k)
return [node.content for node in relevant_chunks]
def _search_tree(self, node: RAPNode, query_embedding: List[float], top_k: int) -> List[RAPNode]:
"""트리를 순회하며 쿼리와 가장 관련성 높은 노드 검색"""
if not node.children: # 리프 노드인 경우
return [node]
# 자식 노드들과 쿼리 간의 유사도 계산
similarities = []
for child in node.children:
if child.embedding:
similarity = self._calculate_similarity(query_embedding, child.embedding)
similarities.append((child, similarity))
# 유사도에 따라 정렬
similarities.sort(key=lambda x: x[1], reverse=True)
# 상위 k개의 관련 자식 노드 선택
top_children = [item[0] for item in similarities[:top_k]]
# 선택된 자식 노드들에 대해 재귀적으로 검색
results = []
for child in top_children:
results.extend(self._search_tree(child, query_embedding, top_k))
return results[:top_k]
def _calculate_similarity(self, embedding1: List[float], embedding2: List[float]) -> float:
"""두 임베딩 간의 코사인 유사도 계산"""
embedding1 = np.array(embedding1)
embedding2 = np.array(embedding2)
return np.dot(embedding1, embedding2) / (np.linalg.norm(embedding1) * np.linalg.norm(embedding2))
# 사용 예시
def main():
# 예시 문서
document = """
[여기에 긴 문서 내용이 들어갑니다...]
"""
# RAP 인스턴스 생성 및 문서 처리
rap = RAP(max_chunk_size=1500)
rap.process_document(document)
# 쿼리 실행
query = "인공지능의 윤리적 문제는 무엇인가요?"
relevant_chunks = rap.query(query, top_k=2)
print("관련 청크:")
for i, chunk in enumerate(relevant_chunks):
print(f"청크 {i+1}:\n{chunk}\n")
if __name__ == "__main__":
main()
위 코드의 경우, RAPTOR의 동작 절차에 따라 구현된 코드로 리프노드로 부터 상위 레벨을 구현하는데 있어 매우 단순한 로직을 사용하고 있습니다.
max_children의 갯수를 지정하여, 리프 노드의 최대갯수로 제한하고, 이것들 순차적으로 끊어서 요약을 합니다.
예를 들면, 리프 노드가 10개의 청크로 이루어졌고, max_children이 3이라면, [“1″,”2″,”3″,”4″,”5″,”6″,”7″,”8″,”9″,”10”]와 같이 10개의 노드는 [[“1″,”2″,”3” => “1-1”],[“4″,”5″,”6” => “1-2”],[“7″,”8″,”9” => “1-3″],”10”] 로 4개의 노드, 이것은 다시 [[“2-1″],”10”] 2개의 노드, 입니다.
사실 관련성이 없이 순서에 따라 추상화라는 명목으로 요약을 해서 “1-1” ~ “2-1” 처럼 새로운 노드를 트리 구조로 생성하는데, 이 방식은 원래 취지와는 다소 동떨어진 구성입니다. 만약, 1과 9가 관련성이 높은 노드라고 하면, 이를 알아내는 과정이 중요합니다.
이러한 문제를 뒷받침하기 위해, 트리 구축에서 가우시안 혼합 모델(GMM), UMAP (Uniform Manifold Approximation and Projection) 또는 지역 및 전역 클러스터링, 임계값 설정 등의 다른 방식 중에서 제일 효율적인 방식을 선정하여 노드를 기반으로 트리 구축하는 방법에 대한 있어, 링크를 공유합니다.
트리 구축 방법 예시: https://wikidocs.net/234017
RAPTOR의 작동 원리 설명
위 코드는 다음과 같은 단계로 작동합니다:
- 문서 분할: 긴 문서를 관리 가능한 크기의 청크로 나눕니다.
- 트리 구조 구축: 청크들을 리프 노드로 하는 계층적 트리를 구축합니다.
- 요약 생성: 리프 노드부터 시작하여 상향식으로 각 노드의 요약을 생성합니다.
- 임베딩 생성: 각 노드의 요약에 대한 벡터 임베딩을 생성합니다.
- 쿼리 처리: 사용자 쿼리를 임베딩하고, 트리를 순회하며 가장 관련성 높은 청크를 찾습니다.
이 방식은 전체 문서를 한 번에 처리하는 대신, 계층적 구조를 활용하여 필요한 정보만 효율적으로 접근할 수 있게 해줍니다.
RAPTOR의 장점
- 효율성: 전체 문서를 처리하지 않고 관련 부분만 검색하여 처리 효율성 향상
- 확장성: 매우 긴 문서나 여러 문서를 처리할 수 있는 확장성 제공
- 정보 보존: 계층적 요약을 통해 중요 정보 보존
- 컨텍스트 제한 극복: LLM의 컨텍스트 제한을 효과적으로 우회
RAPTOR의 단점
- 트리 구성에 대한 리프 노드간의 관련성이 있는 항목을 찾아내어 상위 레벨의 노드를 구성하는 것에 대해서는 추가적인 고민이 필요. (이유없이 갯수로 제한하는 것에 대해서는 효율성 및 정확성에 대한 문제점 야기)
- 임베딩 모델링과 요약을 위한 이유로 AI를 이용한 트래픽이 실제 로직 처리에 소요되는 자원과 시간이 많음
결론
RAPTOR은 대규모 문서를 효율적으로 처리하고 검색하는 강력한 방법입니다. 계층적 요약과 트리 구조를 활용함으로써, LLM의 컨텍스트 제한을 우회하고 방대한 정보를 효과적으로 처리할 수 있습니다. 법률, 학술 연구, 기업 문서 관리 등 다양한 분야에서 RAP의 적용 가능성은 무궁무진합니다.
이 기술은 단순히 정보 검색을 넘어, 대규모 문서에서 의미 있는 인사이트를 추출하고 복잡한 질문에 정확한 답변을 제공하는 차세대 지식 처리 시스템의 기반이 될 것입니다.
답글 남기기