




RAG의 복잡성을 해결하는 새로운 접근법
Google이 Gemini API에 완전 관리형 RAG(Retrieval-Augmented Generation) 시스템인 File Search Tool을 출시했습니다. 이 도구는 검색 파이프라인의 복잡성을 추상화하여 개발자가 실제 서비스 구축에만 집중할 수 있도록 설계되었습니다.
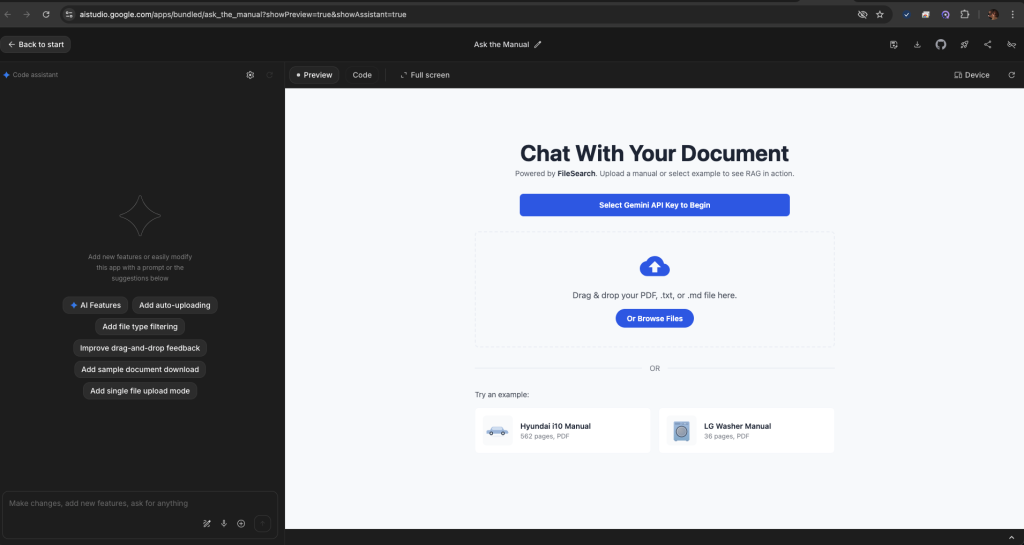
File Search Tool의 핵심 특징
1. 혁신적인 가격 정책
File Search Tool의 가장 주목할 만한 특징은 파격적인 가격 정책입니다:
- 파일 저장소 비용: 무료
- 쿼리 시점 임베딩 생성: 무료
- 초기 파일 인덱싱 비용만 발생: 100만 토큰당 $0.15 (gemini-embedding-001 모델 기준)
이러한 가격 정책은 RAG 시스템 구축과 확장을 매우 경제적으로 만들어 모든 개발자가 쉽게 접근할 수 있게 합니다.
2. 간편한 통합 개발 경험
File Search는 RAG 프로세스 전체를 자동화하여 개발 워크플로우를 크게 단순화합니다:
- 자동 파일 저장 관리: 파일 업로드 및 관리를 자동으로 처리
- 최적화된 청킹 전략: 문서를 효과적으로 분할하는 전략을 자동 적용
- 임베딩 자동 생성: 최신 Gemini Embedding 모델을 활용한 자동 벡터화
- 동적 컨텍스트 주입: 검색된 내용을 프롬프트에 자동으로 삽입
- 기존 API와의 통합:
generateContentAPI 내에서 작동하여 쉽게 적용 가능
3. 강력한 벡터 검색 기능
최신 Gemini Embedding 모델을 기반으로 한 벡터 검색은 단순한 키워드 매칭을 넘어섭니다:
- 사용자 쿼리의 의미와 맥락을 이해
- 정확한 단어가 사용되지 않아도 관련 정보 검색 가능
- 의미론적 유사성을 기반으로 한 정확한 정보 제공
4. 자동 인용 기능
생성된 응답에는 자동으로 인용 정보가 포함됩니다:
- 답변 생성에 사용된 문서의 특정 부분 명시
- 검증 프로세스 간소화
- 정보의 출처 추적 용이
5. 다양한 파일 형식 지원
포괄적인 지식 베이스 구축을 위해 다양한 파일 형식을 지원합니다:
- PDF, DOCX, TXT, JSON
- 다양한 프로그래밍 언어 파일 형식
- 광범위한 문서 타입 지원
실제 활용 사례: Beam의 성공 스토리
Phaser Studio에서 개발한 AI 기반 게임 생성 플랫폼 Beam은 File Search Tool의 얼리 액세스 프로그램에 참여하여 인상적인 결과를 거두었습니다:
- 일일 검색량: 수천 건의 검색 처리
- 성능 개선: 모든 코퍼스에서 병렬 쿼리를 실행하고 2초 이내에 결과 결합
- 생산성 향상: 이전에는 수 시간이 걸리던 수동 교차 참조 작업이 대폭 단축
File Search Tool과 기존 RAG 시스템 비교
기존 자체 관리 RAG 시스템
- 복잡한 인프라 구축 필요
- 벡터 데이터베이스 관리
- 청킹 전략 수동 최적화
- 임베딩 모델 선택 및 관리
- 지속적인 유지보수 부담
File Search Tool
- 완전 관리형 서비스
- 인프라 걱정 없음
- 자동 최적화
- 간단한 API 호출만으로 구현
- 낮은 진입 장벽
활용 가능한 분야
개발자들은 이미 File Search Tool을 다양한 분야에 적용하고 있습니다:
- 인텔리전트 고객 지원 봇: 방대한 제품 문서를 기반으로 한 정확한 답변 제공
- 사내 지식 관리 시스템: 기업 내부 문서를 활용한 지식 검색 및 공유
- 콘텐츠 발견 플랫폼: 창의적인 콘텐츠 추천 및 탐색 지원
- 문서 분석 도구: 대량의 문서에서 인사이트 추출
실전 활용 가이드

1. 파일 업로드 방법
File Search Tool은 두 가지 파일 업로드 방식을 제공합니다:
방법 1: 파일 검색 스토어에 직접 업로드
파일을 업로드하고 동시에 파일 검색 스토어로 가져오는 가장 간단한 방법입니다:
from google import genai
from google.genai import types
import time
client = genai.Client()
# 파일 검색 스토어 생성
file_search_store = client.file_search_stores.create(
config={'display_name': 'your-fileSearchStore-name'}
)
# 파일 업로드 및 가져오기 동시 수행
operation = client.file_search_stores.upload_to_file_search_store(
file='sample.txt',
file_search_store_name=file_search_store.name,
config={
'display_name': 'display-file-name',
}
)
# 가져오기 완료 대기
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
방법 2: 기존 파일 가져오기
Files API를 통해 먼저 파일을 업로드한 후 파일 검색 스토어로 가져오는 방법입니다:
# Files API로 파일 업로드
sample_file = client.files.upload(
file='sample.txt',
config={'name': 'display_file_name'}
)
# 파일 검색 스토어 생성
file_search_store = client.file_search_stores.create(
config={'display_name': 'your-fileSearchStore-name'}
)
# 파일 검색 스토어로 가져오기
operation = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name
)
2. 청크 구성 커스터마이징
파일은 자동으로 청크로 분할되지만, 더 세밀한 제어가 필요한 경우 청크 전략을 직접 설정할 수 있습니다:
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.name,
file_name=sample_file.name,
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200, # 청크당 최대 토큰 수
'max_overlap_tokens': 20 # 중복 토큰 수
}
}
}
)
청크 설정 팁:
max_tokens_per_chunk: 각 청크의 크기 조절 (작을수록 정밀, 클수록 컨텍스트 포함)max_overlap_tokens: 청크 간 중복으로 문맥 연결성 유지
3. 작동 원리: 시맨틱 검색
File Search는 키워드 기반 검색이 아닌 시맨틱 검색을 사용합니다:
- 임베딩 변환: 파일이 업로드되면 텍스트가 의미를 포착하는 숫자 벡터(임베딩)로 변환됩니다.
- 데이터베이스 저장: 생성된 임베딩은 특수 파일 검색 데이터베이스에 저장됩니다.
- 쿼리 처리: 사용자 쿼리도 임베딩으로 변환됩니다.
- 유사도 검색: 쿼리 임베딩과 가장 유사한 문서 청크를 찾습니다.
- 컨텍스트 제공: 검색된 청크가 모델에 컨텍스트로 제공되어 정확한 답변을 생성합니다.
4. 파일 검색 실행
파일 검색 스토어를 생성한 후 generateContent 메서드에서 도구로 사용합니다:
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="Can you tell me about Robert Graves",
config=types.GenerateContentConfig(
tools=[
file_search=(
file_search_store_names=[file_search_store.name]
)
]
)
)
print(response.text)
5. 메타데이터 관리
파일에 커스텀 메타데이터를 추가하여 검색을 더욱 정교하게 만들 수 있습니다:
# 메타데이터와 함께 파일 가져오기
op = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name,
custom_metadata=[
{"key": "author", "string_value": "Robert Graves"},
{"key": "year", "numeric_value": 1934}
]
)
# 메타데이터 필터를 사용한 검색
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="Tell me about the book 'I, Claudius'",
config=types.GenerateContentConfig(
tools=[
types.Tool(
file_search=types.FileSearch(
file_search_store_names=[file_search_store.name],
metadata_filter='author=Robert Graves',
)
)
]
)
)
메타데이터 활용 사례:
- 저자, 출판연도, 문서 타입 등으로 필터링
- 특정 부서나 프로젝트 문서만 검색
- 버전 관리 및 시간대별 문서 구분
6. 파일 검색 스토어 관리
여러 파일 검색 스토어를 생성하여 문서를 체계적으로 관리할 수 있습니다:
# 파일 검색 스토어 생성
file_search_store = client.file_search_stores.create(
config={'display_name': 'my-file_search-store-123'}
)
# 모든 파일 검색 스토어 나열
for store in client.file_search_stores.list():
print(store)
# 특정 파일 검색 스토어 가져오기
my_store = client.file_search_stores.get(
name='fileSearchStores/my-file_search-store-123'
)
# 파일 검색 스토어 삭제
client.file_search_stores.delete(
name='fileSearchStores/my-file_search-store-123',
config={'force': True}
)
중요 사항:
- Files API로 업로드한 원본 파일은 48시간 후 자동 삭제
- 파일 검색 스토어에 가져온 데이터는 수동으로 삭제할 때까지 무기한 보관
- 파일 검색 스토어 이름은 전역 범위에서 고유해야 함
7. 인용 정보 활용
File Search는 답변에 자동으로 인용 정보를 포함합니다:
# 인용 정보 확인
print(response.candidates[0].grounding_metadata)
인용 정보를 통해:
- 답변의 출처를 명확히 확인
- 사실 검증 및 검토 용이
- 사용자에게 투명성 제공
8. 지원되는 파일 형식
File Search는 광범위한 파일 형식을 지원합니다:
문서 형식:
- PDF, DOCX, DOC, PPTX, XLSX, XLS
- ODT (OpenDocument Text)
- TXT, RTF, Markdown
프로그래밍 언어:
- Python, JavaScript, TypeScript, Java, C/C++, C#
- Go, Rust, Kotlin, Swift, PHP, Ruby, Perl
- Shell scripts (bash, zsh, powershell)
- SQL, HTML, CSS, XML, JSON
기타:
- LaTeX, Jupyter Notebook
- CSV, TSV
- 다양한 텍스트 기반 형식
9. 비율 제한 및 용량
파일 크기 제한:
- 문서당 최대 100MB
프로젝트별 총 용량 (사용자 등급 기준):
- 무료: 1GB
- Tier 1: 10GB
- Tier 2: 100GB
- Tier 3: 1TB
성능 권장사항:
- 최적의 검색 지연 시간을 위해 각 파일 검색 스토어는 20GB 미만 유지 권장
- 대량의 문서는 여러 파일 검색 스토어로 분산
10. 가격 정책 상세
과금 항목:
- 색인 생성 시 임베딩: 100만 토큰당 $0.15 (gemini-embedding-001 기준)
- 저장소: 무료
- 쿼리 시 임베딩: 무료
- 검색된 문서 토큰: 일반 컨텍스트 토큰으로 과금
비용 최적화 팁:
- 초기 색인 생성 시에만 비용 발생
- 반복적인 쿼리는 추가 임베딩 비용 없음
- 문서를 효율적으로 구조화하여 토큰 사용 최소화
시작하기
File Search Tool은 현재 사용 가능하며, 다음 방법으로 시작할 수 있습니다:
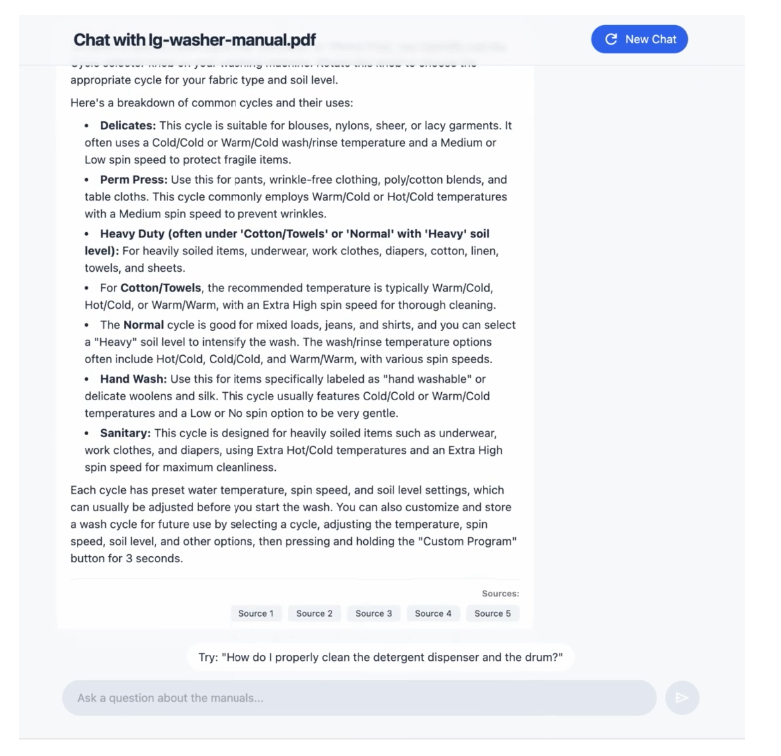
- 공식 문서: File Search 문서에서 상세한 가이드 확인
- 데모 앱 체험: Google AI Studio (https://aistudio.google.com/apps/bundled/ask_the_manual)에서 “Ask the Manual” 데모 앱 실행 (유료 API 키 필요)
- 리믹스 및 커스터마이징: 데모 앱을 자신의 용도에 맞게 수정 가능
지원 모델
현재 File Search를 지원하는 Gemini 모델:
- Gemini 2.5 Flash
- Gemini 2.0 Flash
- 기타 최신 Gemini 모델
결론
Google의 File Search Tool은 RAG 기술을 더 많은 개발자가 쉽게 활용할 수 있도록 만드는 중요한 진전입니다. 복잡한 인프라 관리 없이도 강력한 문서 기반 AI 애플리케이션을 구축할 수 있게 되었으며, 경제적인 가격 정책은 스타트업과 개인 개발자에게도 기회를 열어줍니다.
완전 관리형 RAG 시스템의 등장은 AI 애플리케이션 개발의 패러다임을 바꾸고 있습니다. 개발자들은 청크 분할, 임베딩 생성, 벡터 데이터베이스 관리 등의 복잡한 작업에서 벗어나 사용자에게 실질적인 가치를 제공하는 서비스 개발에만 집중할 수 있습니다.
특히 메타데이터 필터링, 커스텀 청크 구성, 자동 인용 기능 등 세밀한 제어가 가능하면서도 간단한 API로 접근할 수 있다는 점은 File Search Tool의 가장 큰 강점입니다. 이제 몇 줄의 코드만으로 엔터프라이즈급 문서 검색 시스템을 구축할 수 있는 시대가 열렸습니다.
답글 남기기