




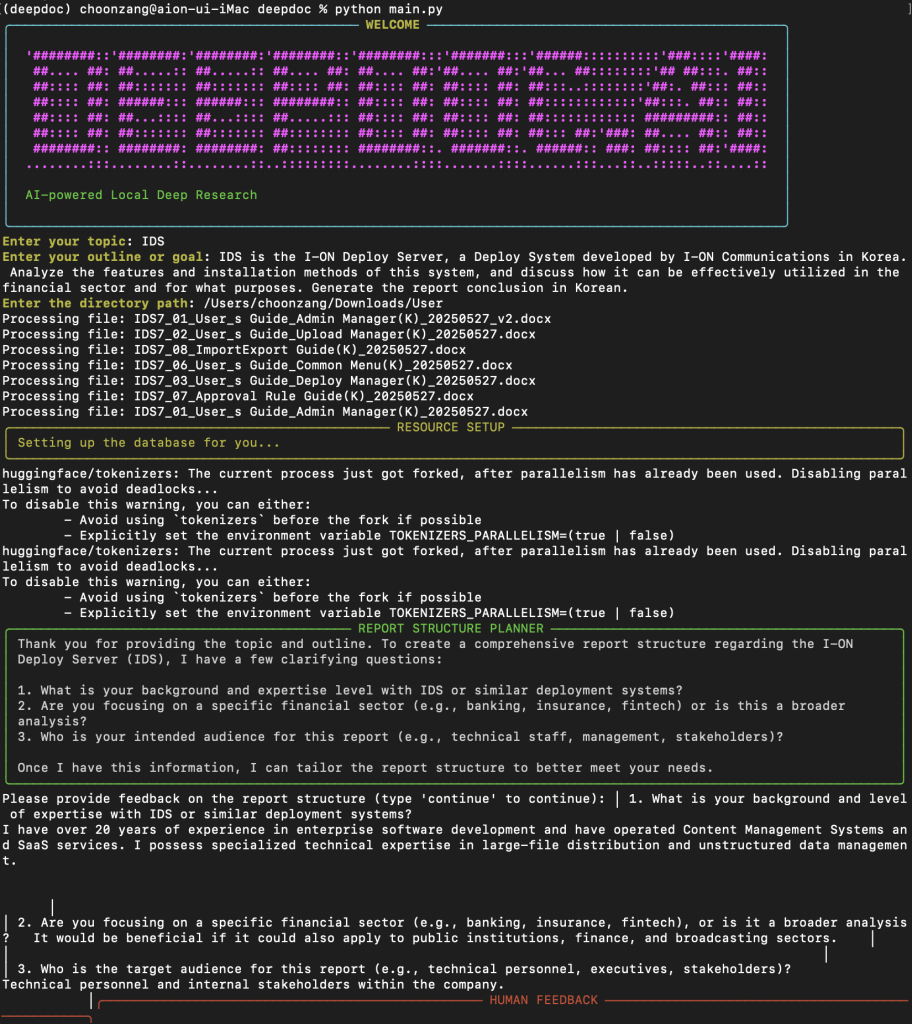
오늘날 정보의 홍수 속에서 자신이 보유한 문서들로부터 인사이트를 도출하는 것은 쉽지 않은 일입니다. 특히 방대한 양의 PDF, 워드 문서, 텍스트 파일 등을 일일이 검토하는 것은 시간과 노력이 많이 소요됩니다. 이런 문제를 해결하기 위해 등장한 DeepDoc은 로컬 문서에 대한 심층 분석을 자동화하는 혁신적인 도구입니다.
DeepDoc이란 무엇인가?
DeepDoc은 인터넷 검색 대신 사용자의 로컬 리소스를 깊이 있게 분석하는 도구입니다. 연구 스타일의 워크플로우를 사용하여 문서를 탐색하고, 발견된 내용을 체계적으로 정리한 후, 명확한 마크다운 보고서를 생성합니다. 이를 통해 사용자는 수동으로 문서를 뒤지지 않고도 자신의 파일에서 빠르게 인사이트를 얻을 수 있습니다.
특히 연구자, 학생, 비즈니스 전문가 등 대량의 문서를 다루는 사람들에게 DeepDoc은 시간을 절약하고 더 나은 결과물을 얻을 수 있는 강력한 도구가 될 것입니다.
DeepDoc의 작동 방식
DeepDoc은 복잡한 문서 분석 과정을 자동화하기 위해 다음과 같은 단계로 작동합니다:
1. 문서 업로드 및 처리
- PDF, DOCX, JPG, TXT 등 다양한 형식의 로컬 리소스를 업로드합니다.
- 시스템이 텍스트를 추출하고 페이지 단위로 청크(chunks)로 분할합니다.
- 이 청크들은 의미적 유사성 검색을 위해 벡터 데이터베이스에 저장됩니다.
2. 콘텐츠 구조화
- 사용자의 지시 쿼리를 기반으로 콘텐츠 구조가 생성됩니다.
- 사용자는 이 구조에 대한 피드백을 제공하여 정제할 수 있습니다.
- 도구는 보고서 섹션과 섹션 주제를 생성합니다.
3. 리서치 에이전트 작업
각 섹션에 대해 리서치 에이전트가 다음 작업을 수행합니다:
- 섹션에 대한 지식 생성
- 연구 쿼리 생성
- 청크화된 로컬 데이터에 대한 검색 에이전트 실행
- 결과를 정제하기 위한 리플렉션 에이전트 사용
- 최종 섹션 콘텐츠 생성
4. 최종 보고서 작성
- 섹션별 콘텐츠가 컴파일되어 최종 보고서 작성자에게 전달됩니다.
- 출력물은 마크다운 형식의 완전하고 구조화된 보고서입니다.
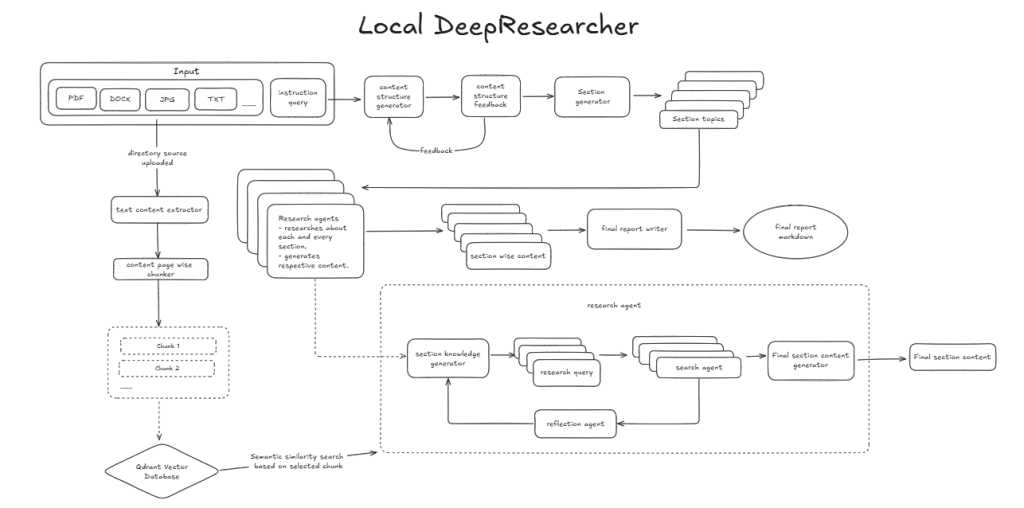
이 다이어그램은 Local DeepResearcher가 로컬 리소스와 지시사항을 받아 콘텐츠를 처리 및 분석하고 구조화된 보고서로 변환하는 방법을 보여줍니다.
DeepDoc 시작하기
DeepDoc을 로컬에서 설정하고 실행하는 방법을 단계별로 알아보겠습니다.
사전 요구사항: uv 설치
가상 환경과 종속성을 관리하기 위해 uv가 필요합니다. 공식 uv GitHub 저장소에서 다운로드할 수 있으며, 플랫폼별 설치 지침이 포함되어 있습니다.
1. 저장소 복제
먼저 GitHub에서 DeepDoc 저장소를 복제합니다:
git clone https://github.com/Datalore-ai/deepdoc.git
cd deepdoc
2. 가상 환경 생성
uv를 사용하여 가상 환경을 생성합니다: python -m 보다는 uv를 권장합니다.
uv venv
3. 가상 환경 활성화
운영 체제에 따라 환경을 활성화합니다:
Windows:
.venv\Scripts\activate
macOS/Linux:
source .venv/bin/activate
4. 환경 변수 설정
예제 .env 파일을 복사하고 API 키를 추가합니다:
cp .env.example .env
텍스트 편집기에서 .env 파일을 열고 필요한 필드를 채웁니다:
MISTRAL_API_KEY=
TAVILY_API_KEY=
OPENAI_API_KEY=
#Default
QDRANT_URL=http://localhost:6333
COLLECTION_NAME=knowledge_base
EMBEDDING_MODEL=BAAI/bge-small-en-v1.5
QDRANT_DISABLE_THREADING=true # Don't change this
이러한 키는 애플리케이션이 올바르게 작동하는 데 필수적입니다.
5. 종속성 설치
다음을 사용하여 필요한 패키지를 설치합니다:
uv pip install -r requirements.txt
6. Qdrant vectorDB용 Docker 설정
Docker와 Docker Compose가 설치되어 있는지 확인하세요. 그런 다음 다음을 사용하여 필요한 서비스(예: Qdrant)를 시작합니다:
docker-compose up --build
이렇게 하면 필요한 서비스가 백그라운드에서 시작됩니다.
7. 애플리케이션 실행
환경과 서비스가 준비되면 애플리케이션을 시작합니다:
python main.py
이제 모든 준비가 완료되었습니다! 애플리케이션이 데이터셋 생성 프로세스를 단계별로 안내하고 최종 데이터셋은 output_files 디렉토리에 저장됩니다.
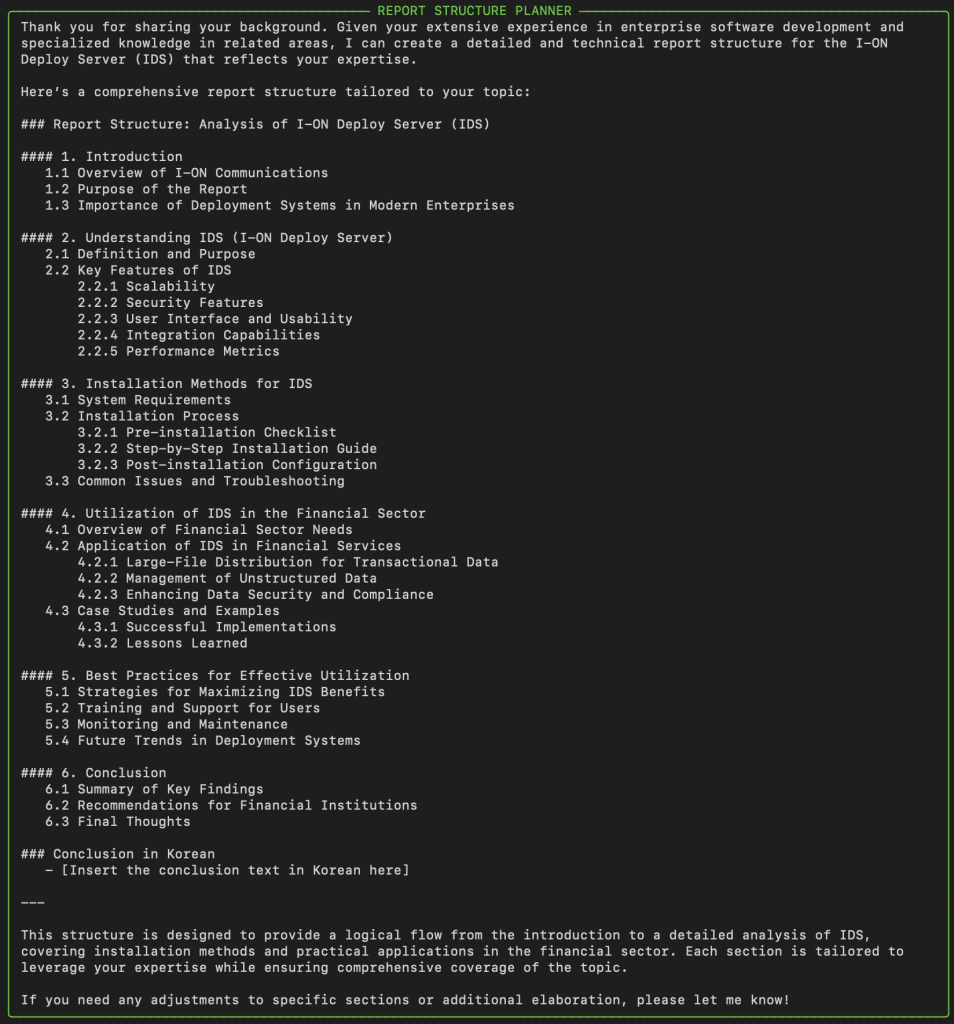
[DeepDoc 애플리케이션 실행 화면 이미지]
DeepDoc 커스터마이징
configuration.py 파일 사용하기
configuration.py 파일을 사용하여 도구의 동작을 사용자 정의할 수 있습니다. 이 파일을 통해 애플리케이션의 두 가지 매개변수를 조정할 수 있습니다:
import uuid
LLM_CONFIG = {
"provider": "openai",
"model": "gpt-4o-mini",
"temperature": 0.5,
}
THREAD_CONFIG = {
"configurable": {
"thread_id": str(uuid.uuid4()),
"max_queries": 3,
"search_depth": 2,
"num_reflections": 2,
"n_points": 1,
}
}LLM_CONFIG에서는 사용할 AI 모델 제공자, 모델 유형, 온도(창의성 수준) 등을 설정할 수 있습니다. THREAD_CONFIG에서는 검색 깊이, 최대 쿼리 수, 리플렉션 횟수 등 검색 프로세스의 세부 사항을 조정할 수 있습니다.
DeepDoc의 활용 사례
학술 연구
연구자들은 DeepDoc을 사용하여 수많은 논문과 연구 자료에서 관련 정보를 추출하고 체계적인 문헌 검토 보고서를 생성할 수 있습니다. 이는 연구 시간을 크게 단축시키고 더 포괄적인 분석을 가능하게 합니다.
비즈니스 인텔리전스
기업은 내부 문서, 보고서, 이메일 등에서 중요한 비즈니스 인사이트를 추출하여 의사 결정에 활용할 수 있습니다. 예를 들어, 고객 피드백 문서를 분석하여 제품 개선 방향을 도출할 수 있습니다.
법률 문서 분석
변호사와 법률 전문가는 방대한 양의 법률 문서, 판례, 계약서 등에서 관련 정보를 신속하게 찾아 법적 분석 보고서를 작성할 수 있습니다.
교육 자료 개발
교육자들은 다양한 교육 자료에서 정보를 추출하여 학생들을 위한 맞춤형 학습 자료와 요약본을 만들 수 있습니다.
DeepDoc의 기술적 특징
벡터 데이터베이스 활용
DeepDoc은 Qdrant 벡터 데이터베이스를 사용하여 문서 청크를 저장하고 의미적 유사성 검색을 수행합니다. 이를 통해 단순한 키워드 매칭을 넘어 문맥을 이해하는 검색이 가능합니다.
다중 에이전트 아키텍처
지식 생성, 연구 쿼리 생성, 검색, 리플렉션 등 다양한 역할을 수행하는 여러 에이전트가 협력하여 작업합니다. 이러한 다중 에이전트 접근 방식은 더 정확하고 포괄적인 결과를 제공합니다.
다양한 파일 형식 지원
PDF, DOCX, JPG, TXT 등 다양한 파일 형식에서 텍스트를 추출하고 분석할 수 있습니다. 이는 사용자가 여러 형식의 문서를 함께 분석할 수 있게 해줍니다.
사용자 피드백 통합
생성된 콘텐츠 구조에 대해 사용자가 피드백을 제공하고 이를 반영하여 결과를 개선할 수 있습니다. 이는 사용자의 요구에 더 잘 맞는 보고서를 생성하는 데 도움이 됩니다.
DeepDoc과 유사 도구 비교
DeepDoc은 로컬 문서에 초점을 맞춘 심층 분석 도구로, 다른 문서 분석 도구와 몇 가지 중요한 차이점이 있습니다:
- DeepDoc은 사용자의 로컬 문서에 집중합니다. 이는 비공개 또는 내부 문서를 다룰 때 특히 유용합니다. 그리고, 의미적 유사성 검색과 AI 기반 분석을 통해 더 깊은 인사이트를 제공하며, 여러 문서에서 정보를 통합하고 구조화된 보고서를 생성합니다.
향후 개발 방향
DeepDoc은 현재도 강력한 도구이지만, 다음과 같은 영역에서 더 발전할 가능성이 있습니다:
- 멀티모달 분석: 텍스트뿐만 아니라 이미지, 차트, 그래프 등의 시각적 요소도 분석하여 더 포괄적인 인사이트 제공
- 실시간 협업: 여러 사용자가 동시에 같은 문서 세트에 대해 작업하고 결과를 공유할 수 있는 기능
- 더 많은 언어 지원: 현재 영어 중심에서 다양한 언어로 확장 (한글 지원은 아직 불가…)
- 사용자 인터페이스 개선: 더 직관적이고 사용하기 쉬운 웹 인터페이스 개발
개발자 정보 및 기여 방법
개발자
DeepDoc은 Swaraj Biswal과 Swadhin Biswal에 의해 개발되었습니다. 이들의 전문성과 노력 덕분에 이 강력한 도구가 탄생했습니다.
기여하기
DeepDoc은 오픈 소스 프로젝트로, 커뮤니티의 기여를 환영합니다. 개선할 점이 있다면 GitHub 저장소에서 이슈를 열거나 풀 리퀘스트를 제출할 수 있습니다.
결론
DeepDoc은 로컬 문서에서 심층적인 인사이트를 추출하는 강력한 도구입니다. 연구 스타일의 워크플로우와 다중 에이전트 아키텍처를 통해 사용자는 방대한 양의 문서에서 빠르게 가치 있는 정보를 발견하고 구조화된 보고서를 생성할 수 있습니다.
학술 연구, 비즈니스 인텔리전스, 법률 문서 분석 등 다양한 분야에서 DeepDoc은 시간을 절약하고 더 나은 결과를 얻는 데 도움이 될 것입니다. 오픈 소스 프로젝트로서 커뮤니티의 기여를 통해 계속 발전할 것으로 기대됩니다.
참고 링크: https://github.com/Datalore-ai/deepdoc
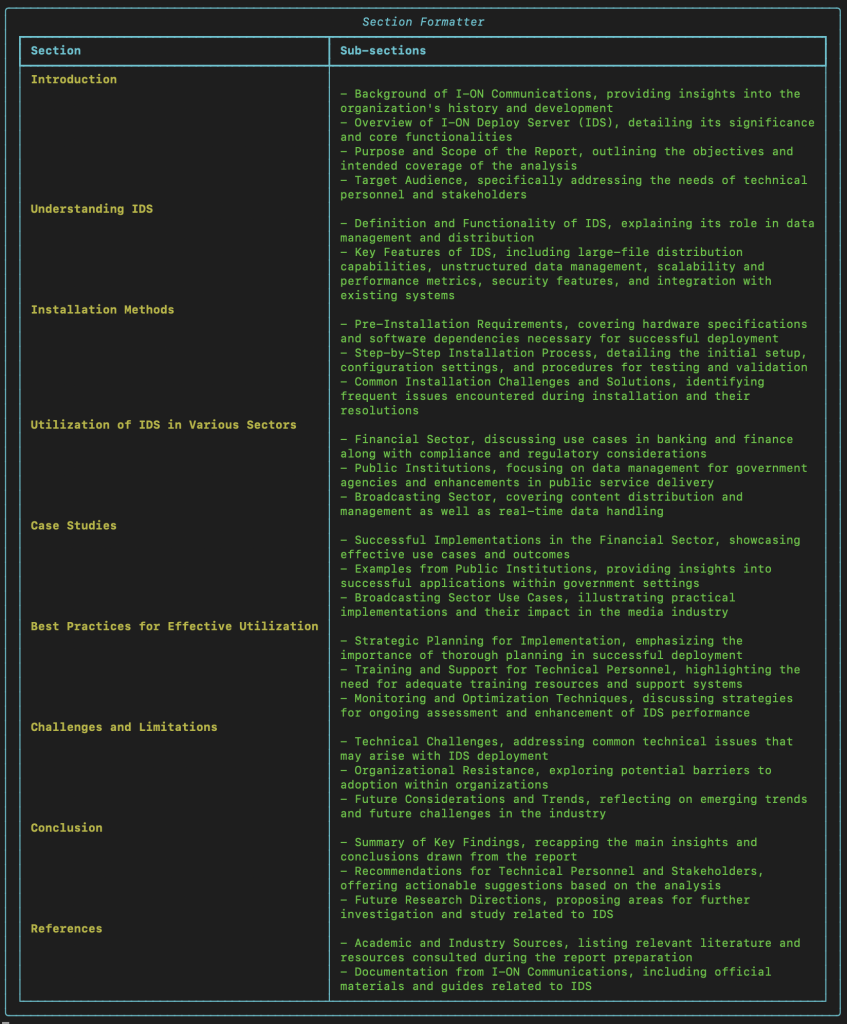
[특정 제품에 대한 문서를 기반으로 분석 문서 생성을 요청했으며, 그에 따른 결론 페이지 입니다. 최종 output폴더에 마크다운 파일로 생성됩니다.]
답글 남기기