




비구조화된 텍스트에서 구조화된 정보를 추출하는 것은 오랫동안 자연어 처리의 핵심 과제 중 하나였습니다. 의료 기록, 법적 문서, 고객 피드백 등에 숨겨진 가치 있는 정보들을 정확하고 추적 가능한 형태로 추출하는 것은 여전히 기술적으로나 실무적으로 큰 도전이었습니다. 구글이 최근 공개한 LangExtract는 이러한 문제를 해결하기 위한 혁신적인 오픈소스 Python 라이브러리입니다.
LangExtract란 무엇인가?
LangExtract는 Gemini와 같은 대규모 언어 모델(LLM)을 활용하여 비구조화된 텍스트 문서에서 구조화된 정보를 추출하는 Python 라이브러리입니다. 사용자가 정의한 지시사항과 few-shot 예제만으로도 임상 기록, 보고서 등의 복잡한 문서에서 핵심 정보를 식별하고 구조화할 수 있습니다.
주요 특징
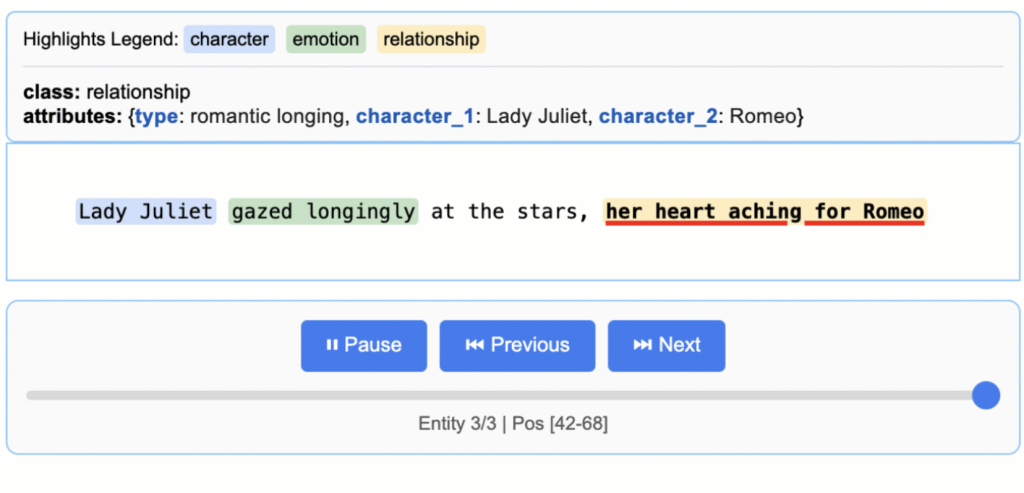
1. 정확한 출처 추적 (Precise Source Grounding) 추출된 모든 정보를 원본 텍스트의 정확한 위치에 매핑하여, 시각적 하이라이팅을 통한 추적 가능성과 검증 기능을 제공합니다.
2. 일관된 구조화된 출력 few-shot 예제를 기반으로 한 일관된 출력 스키마를 적용하여, Gemini와 같은 모델의 제어된 생성 기능을 활용해 안정적인 구조화된 결과를 보장합니다.
3. 긴 문서 최적화 대용량 문서에서 정보를 찾는 “needle-in-a-haystack” 문제를 해결하기 위해 최적화된 텍스트 청킹, 병렬 처리, 다중 패스 전략을 사용합니다.
4. 인터랙티브 시각화 수천 개의 추출된 엔티티를 원래 맥락에서 시각화하고 검토할 수 있는 독립적인 HTML 파일을 즉시 생성합니다.
5. 유연한 LLM 지원 Google Gemini 계열과 같은 클라우드 기반 LLM부터 내장된 Ollama 인터페이스를 통한 로컬 오픈소스 모델까지 다양한 모델을 지원합니다.
실제 사용 예제
LangExtract의 강력함은 간단한 코드로 복잡한 작업을 수행할 수 있다는 점입니다:
import langextract as lx
import textwrap
# 1. Define the prompt and extraction rules
prompt = textwrap.dedent("""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.""")
# 2. Provide a high-quality example to guide the model
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"}
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling": "gentle awe"}
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type": "metaphor"}
),
]
)
]
https://github.com/google/langextract/blob/main/docs/examples/longer_text_example.md
다양한 응용 케이스
1. 의료 분야
임상 기록 구조화: 의사의 진료 노트에서 증상, 진단, 처방 정보를 자동으로 추출하고 구조화합니다.
- 처방전에서 약물명, 용량, 복용법 추출
- 환자 기록에서 증상과 진단명 식별
- 검사 결과에서 수치와 해석 분리
방사선학 보고서 처리: RadExtract 데모에서 볼 수 있듯이, 방사선 보고서에서 소견과 결론을 자동으로 구조화할 수 있습니다.
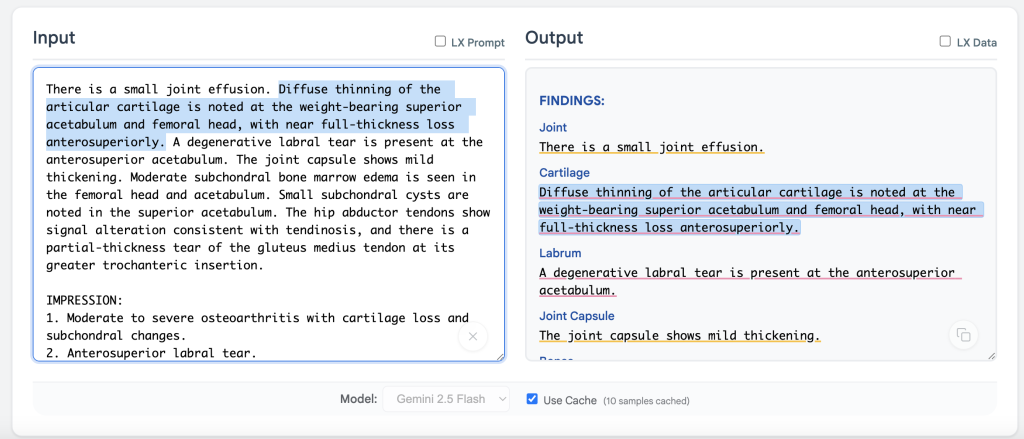
2. 법률 분야
계약서 분석: 복잡한 법적 문서에서 핵심 조항, 날짜, 당사자 정보를 추출합니다.
- 계약 기간, 갱신 조건, 해지 조건 식별
- 책임 범위와 면책 조항 분석
- 재정적 조건과 지급 조건 구조화
3. 금융 서비스
리서치 보고서 분석: 애널리스트 보고서에서 투자 의견, 목표가, 위험 요소를 체계적으로 추출합니다.
- 재무제표에서 핵심 지표 자동 추출
- 신용 평가 보고서에서 위험 요소 식별
- 시장 분석 문서에서 트렌드와 예측 구조화
4. 고객 서비스
피드백 분석: 고객 리뷰나 지원 티켓에서 감정, 이슈 유형, 제품 언급을 자동으로 분류합니다.
- 제품별 만족도와 불만사항 추출
- 서비스 개선 요청사항 구조화
- 고객 여정에서 문제점 식별
5. 학술 연구
문헌 리뷰: 연구 논문에서 방법론, 결과, 결론을 체계적으로 추출하여 메타분석을 지원합니다.
- 연구 방법과 표본 크기 자동 추출
- 통계적 결과와 유의성 식별
- 연구 제한사항과 향후 연구 방향 구조화
6. 미디어와 콘텐츠
뉴스 분석: 뉴스 기사에서 주요 인물, 사건, 날짜, 장소를 자동으로 추출하여 정보 데이터베이스를 구축합니다.
- 기업 실적 발표에서 핵심 수치 추출
- 정치 뉴스에서 정책과 입장 분석
- 스포츠 기사에서 경기 결과와 통계 구조화
7. 교육 분야
학습 자료 구조화: 교재나 강의 노트에서 핵심 개념, 정의, 예제를 자동으로 추출하여 학습 도구를 만듭니다.
- 교과서에서 중요 개념과 공식 추출
- 시험 문제에서 출제 유형과 난이도 분석
- 학생 과제에서 핵심 아이디어와 평가 포인트 식별
기술적 장점
성능 최적화
LangExtract는 대용량 문서 처리를 위해 여러 최적화 기법을 제공합니다:
- 병렬 처리:
max_workers매개변수로 처리 속도 향상 - 다중 패스:
extraction_passes로 추출 정확도 개선 - 청킹 최적화:
max_char_buffer로 컨텍스트 크기 조정
모델 선택의 유연성
- gemini-2.5-flash: 속도, 비용, 품질의 균형이 뛰어난 기본 모델
- gemini-2.5-pro: 복잡한 추론이 필요한 작업에 적합
- 로컬 모델: Ollama를 통한 온프레미스 배포 가능
실전 구현 가이드
설치와 설정
pip install langextract
API 키 설정
export LANGEXTRACT_API_KEY="your-api-key-here"
대용량 문서 처리
# 프로젝트 구텐베르그에서 로미오와 줄리엣 전체 텍스트 처리
result = lx.extract(
text_or_documents="https://www.gutenberg.org/files/1513/1513-0.txt",
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
extraction_passes=3, # 다중 패스로 정확도 향상
max_workers=20, # 병렬 처리로 속도 향상
max_char_buffer=1000 # 더 나은 정확도를 위한 작은 컨텍스트
)미래 전망과 한계점
장점
- Zero-shot 학습: 모델 파인튜닝 없이 바로 사용 가능
- 도메인 적응성: 몇 가지 예제만으로 다양한 도메인에 적용
- 시각화 지원: 결과 검증이 용이한 인터랙티브 HTML 생성
고려사항
- API 비용: 클라우드 모델 사용 시 비용 발생
- 데이터 프라이버시: 민감한 정보 처리 시 로컬 모델 권장
- 모델 의존성: LLM의 성능과 한계에 따라 결과 품질이 결정됨
결론
LangExtract는 정보 추출 작업을 혁신적으로 단순화하는 강력한 도구입니다. 정확한 출처 추적, 유연한 모델 지원, 직관적인 시각화 기능을 통해 개발자들이 복잡한 NLP 작업을 쉽게 구현할 수 있게 해줍니다. 의료, 법률, 금융, 교육 등 다양한 분야에서 비구조화된 데이터를 구조화된 정보로 변환하는 강력한 솔루션을 제공합니다.
특히 few-shot 학습과 제어된 생성 기능을 통해 높은 정확도와 일관성을 보장하면서도, 모델 훈련 없이 즉시 사용할 수 있다는 점이 가장 큰 장점입니다. 구글의 지속적인 개발과 커뮤니티의 기여를 통해 더욱 발전할 것으로 기대됩니다.
LangExtract는 Apache 2.0 라이선스 하에 공개된 오픈소스 프로젝트입니다. 의료 관련 애플리케이션 사용 시에는 Health AI Developer Foundations Terms of Use를 준수해야 합니다.
답글 남기기