




대규모 언어 모델(LLM)을 실제 서비스에 적용하려면 단순히 모델을 불러오는 것 이상의 작업이 필요합니다. 효율적인 추론, 안정적인 서빙, 그리고 최적화된 성능을 위한 인프라 구축이 중요한데요. 오늘은 이러한 요구사항을 충족시키는 Hugging Face의 Text Generation Inference(TGI)에 대해 알아보겠습니다.
TGI란 무엇인가?
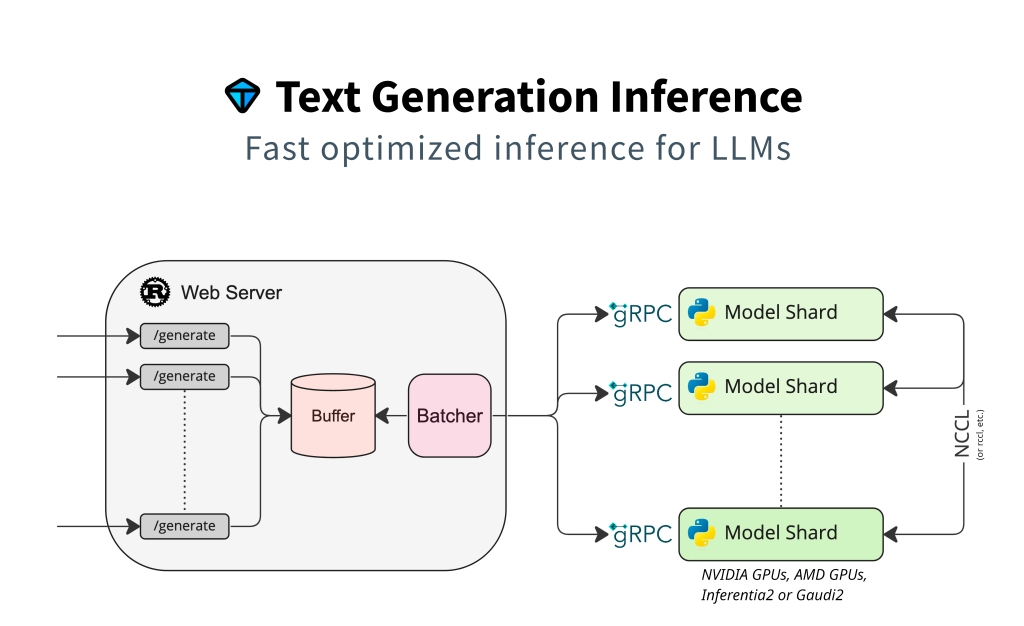
Text Generation Inference(TGI)는 대규모 언어 모델(LLM)을 배포하고 서빙하기 위한 오픈소스 툴킷입니다. 허깅페이스(Hugging Face)가 개발한 TGI는 LLM을 프로덕션 환경에서 효율적으로 배포하고 서빙하는 것을 최우선 목표로 합니다. 대규모 요청을 빠르고 안정적으로 처리하기 위한 다양한 최적화 기술이 집약된, 고성능 추론 서버에 가깝습니다. Llama, Falcon, StarCoder, BLOOM, GPT-NeoX, T5와 같은 인기 있는 오픈소스 LLM을 서빙할 수 있도록 설계되었습니다.
TGI는 단순히 모델을 로드하는 것을 넘어, 프로덕션 환경에서 LLM을 효율적으로 운영하기 위한 다양한 최적화 기능을 제공합니다.
TGI의 주요 특징과 장점
1. 간편한 설정과 프로덕션 레디 기능
- 인기 있는 대부분의 LLM을 위한 간단한 런처 제공
- Open Telemetry를 통한 분산 추적 및 Prometheus 메트릭스 지원
- 프로덕션 환경에 바로 적용 가능한 안정성
2. 성능 최적화 기능
- 여러 GPU에서 더 빠른 추론을 위한 텐서 병렬화(Tensor Parallelism)
- Server-Sent Events(SSE)를 사용한 토큰 스트리밍
- 총 처리량 증가를 위한 연속 배치 처리(Continuous batching)
- Flash Attention과 Paged Attention을 활용한 최적화된 트랜스포머 코드
3. 모델 최적화 및 제어 기능
- bitsandbytes 및 GPT-Q를 사용한 양자화(Quantization)
- Safetensors 가중치 로딩
- 대규모 언어 모델을 위한 워터마킹
- 로짓 워퍼(temperature scaling, top-p, top-k, 반복 패널티)
- 중지 시퀀스 및 로그 확률 지원
4. 고급 기능
- 파인튜닝 지원: 특정 작업에 맞게 미세 조정된 모델 활용
- 가이던스: 사전 정의된 출력 스키마에 따라 구조화된 출력 생성 강제화
- 함수 호출 및 도구 사용 지원
TGI 설치 및 시작하기
TGI는 Docker를 통해 쉽게 설치하고 실행할 수 있습니다. 기본적인 설치 및 실행 방법은 다음과 같습니다:
Docker를 이용한 설치
다음 명령어로 TGI Docker 이미지를 실행할 수 있습니다:
docker run --gpus all -p 8080:80 \
-v $HOME/models:/models \
ghcr.io/huggingface/text-generation-inference:latest \
--model-id /models/your-model
이 명령어는 로컬 모델 디렉토리를 컨테이너에 마운트하고, 8080 포트를 통해 TGI 서버를 노출합니다.
API 호출 예시
TGI 서버가 실행되면 다음과 같이 API를 호출할 수 있습니다:
import requests
response = requests.post(
"http://localhost:8080/generate",
json={
"inputs": "What is Deep Learning?",
"parameters": {
"max_new_tokens": 100,
"temperature": 0.7,
"top_p": 0.95
}
}
)
print(response.json())v0.9+ 서버를 –openai 옵션으로 띄우면 /v1/chat/completions 사용 가능하며, curl·Python·OpenAI SDK·Gradio UI·ChatUI 등 다양한 클라이언트 예제가 공식 튜토리얼에 제공되어 있습니다.
TGI의 경쟁 라인업과 대안
TGI 외에도 LLM 서빙을 위한 다양한 솔루션이 있습니다:
- vLLM: 페이지드 어텐션을 활용한 고성능 LLM 서빙 라이브러리
- FastChat: ChatGPT와 유사한 LLM 서빙을 위한 플랫폼
- LocalAI: 로컬 환경에서 AI 모델을 실행하기 위한 경량 솔루션으로, OpenAI 호환 API를 제공하며 자원 제약이 있는 환경에서도 LLM을 실행할 수 있게 해줍니다.
이러한 대안들은 각각 고유한 장점을 가지고 있으며, 특히 LocalAI는 다음 포스트에서 더 자세히 다룰 예정입니다. 로컬 환경에서 LLM을 실행하고 싶거나 리소스가 제한된 환경에서 작업해야 하는 경우 LocalAI가 좋은 선택이 될 수 있습니다.
마치며
TGI는 LLM을 프로덕션 환경에 배포하고 서빙하기 위한 강력한 도구입니다. 다양한 최적화 기능과 사용 편의성을 제공하여, 개발자가 LLM의 성능을 최대한 활용할 수 있도록 도와줍니다.
다음 포스트에서는 LocalAI를 중심으로 경량화된 LLM 서빙 솔루션에 대해 더 자세히 알아보겠습니다. 로컬 환경에서 LLM을 실행하는 방법과 리소스 제약이 있는 환경에서의 최적화 전략에 대해 다룰 예정이니 많은 관심 부탁드립니다!

답글 남기기