




Retrieval Augmented Generation (RAG) 시스템은 거대 언어 모델(LLM)에 외부 지식이나 최신 정보를 제공하여 성능을 향상시키는 강력한 방법으로 부상했습니다. 하지만 RAG 시스템에도 여전히 해결해야 할 과제가 많습니다. 이번 글에서는 최근 발표된 논문 “SUFFICIENT CONTEXT: A NEW LENS ON RETRIEVAL AUGMENTED GENERATION SYSTEMS”의 핵심 내용을 바탕으로, 기존 RAG 시스템의 문제점과 이를 개선하기 위한 새로운 접근 방식을 설명해 드리겠습니다.
참고 논문 : https://arxiv.org/pdf/2411.06037 , “SUFFICIENT CONTEXT: A NEW LENS ON RETRIEVAL AUGMENTED GENERATION SYSTEMS”
기존 RAG 시스템의 일반적인 문제점
LLM에 추가 맥락(context)을 제공하는 RAG 시스템은 다양한 애플리케이션에서 성능 개선을 가져왔습니다. 특히 오픈 도메인 질의응답(open-domain question answering)의 경우, 검색 모델이 추론 시점에 스니펫 또는 장문 텍스트 형태의 맥락을 제공하면, LLM은 이 맥락과 질의를 종합하여 답변을 생성합니다.
하지만 현재 RAG 기반 LLM은 다음과 같은 여러 바람직하지 않은 특징을 보입니다:
- 검색된 증거를 가지고도 틀린 답변을 자신 있게 예측하는 경향.
- 무관한 정보에 의해 방해받는 경향.
- 긴 텍스트 스니펫에서 답변을 제대로 추출하지 못하는 경향.
- 불완전한 검색 결과에 대한 견고성 부족: 기존 연구들은 종종 “관련성”에 대한 명확한 정의 없이 검색 품질을 평가했으며, 무관한 맥락이 LLM을 잘못된 방향으로 이끌 수 있음을 보여주었습니다.
- RAG 사용 시 환각(Hallucination) 증가: 추가 맥락의 도입은 역설적으로 모델이 답변을 삼가야 할 때(abstain) 삼가는 능력(abstention)을 감소시킵니다. RAG를 사용할 때 모델은 삼가기보다는 환각을 일으키는 경우가 많습니다.
이러한 문제들은 LLM이 검색된 맥락을 제대로 활용하지 못하기 때문인지, 아니면 애초에 제공된 맥락 자체가 질의에 답변하기에 불충분하기 때문에 발생하는 오류인지를 명확히 구분하기 어렵게 만듭니다. 기존 연구들은 무관한 정보의 존재 하에 모델을 평가했지만, ‘관련 정보’의 범위가 넓어 질의에 답변하기에 정보가 충분한지 여부에 대해 직접적으로 다루지 못했습니다.
이 논문에서 제시하는 개선 방안: ‘충분한 맥락’과 선택적 생성
이 논문은 ‘충분한 맥락(sufficient context)‘이라는 새로운 개념을 제시하고, 이를 활용하여 RAG 시스템의 성능을 분석하고 환각을 줄이는 방법을 모색합니다.
1. ‘충분한 맥락’의 정의 및 분류: 이 논문의 첫 번째 기여는 ‘충분한 맥락’의 새로운 개념을 정의하는 것입니다.
- 충분한 맥락: 질의에 대한 타당한 답변(plausible answer)을 구성하는 데 필요한 모든 정보를 맥락이 포함하는 경우입니다. 중요한 것은 이 정의가 정답(ground truth answer)을 미리 알 필요가 없다는 점입니다. 이는 맥락에 잘못된 정보가 포함될 가능성도 허용합니다.
- 불충분한 맥락: 맥락이 질의에 답변하기에 충분하지 않은 경우입니다. 맥락의 정보가 불완전하거나, 불확실하거나, 모순되거나, 혹은 질의가 맥락에 없는 전문 지식을 요구하는 경우 불충분할 수 있습니다.
- 다중 홉(multi-hop) 질의, 모호한 질의, 모호한 맥락의 경우에 대한 충분한 맥락 정의의 특수한 논의도 포함합니다.
이 논문은 질의와 맥락 쌍을 ‘충분’ 또는 ‘불충분’으로 분류하기 위해 LLM 기반의 자동 평가자(autorater)를 개발했습니다. 이 자동 평가자는 인간이 레이블링한 데이터셋에서 93%의 정확도를 달성하여 효과적임이 입증되었습니다. Gemini 1.5 Pro (1-shot) 모델이 가장 좋은 성능을 보였으며, FLAMe는 더 효율적인 대안으로 사용될 수 있습니다.
2. ‘충분한 맥락’ 기반의 RAG 성능 분석: ‘충분한 맥락’ 자동 평가자를 사용하여, 논문은 기존 벤치마크 데이터셋과 LLM 동작에 대한 새로운 통찰력을 발견했습니다.
- 충분한 맥락 상황에서의 환각: 충분한 맥락이 제공된 경우에도, 모델은 질의에 답변하기에 충분한 맥락이 있음에도 불구하고 상당한 비율의 인스턴스에서 잘못된 답변(hallucinate)을 생성하는 것으로 나타났습니다. 즉, 검색만 개선하는 것으로는 오픈 북 질의응답이 완전히 해결되지 않습니다.
- 불충분한 맥락 상황에서의 동작: 불충분한 맥락이 주어졌을 때, 모델은 삼가기(abstain)보다는 환각(hallucinate)을 일으키는 경향이 있습니다. 특히 작은 모델(Gemma 2)에서 이러한 경향이 두드러졌습니다.
- 불충분한 맥락 상황에서의 정답: 놀랍게도, 제공된 맥락이 불충분할 때도 모델이 정답을 생성하는 경우가 많았습니다. 이는 모델이 사전 학습된 지식(parametric memory)을 사용하거나, 맥락이 답변을 직접 제공하지는 않더라도 모델 지식의 간극을 메우거나 질문의 모호성을 해소하는 등 유용하게 활용될 수 있음을 시사합니다. RAG 없이 정답을 맞추는 경우를 제외한 후에도 이러한 경향은 유지되었습니다.
3. 환각 감소를 위한 ‘선택적 생성(Selective Generation)’: 위 분석을 바탕으로, 논문은 환각을 줄이기 위해 ‘충분한 맥락’ 레이블을 사용하는 방법을 모색했습니다. ‘충분한 맥락’ 자동 평가자가 불충분한 맥락을 판단할 때 단순히 답변을 삼가도록 하는 것은 모델이 불충분한 맥락에서도 정답을 맞추는 경우(아래 Table, 논문 Table 2 참고)를 놓치게 되어 전체 성능을 저하시킬 수 있습니다.
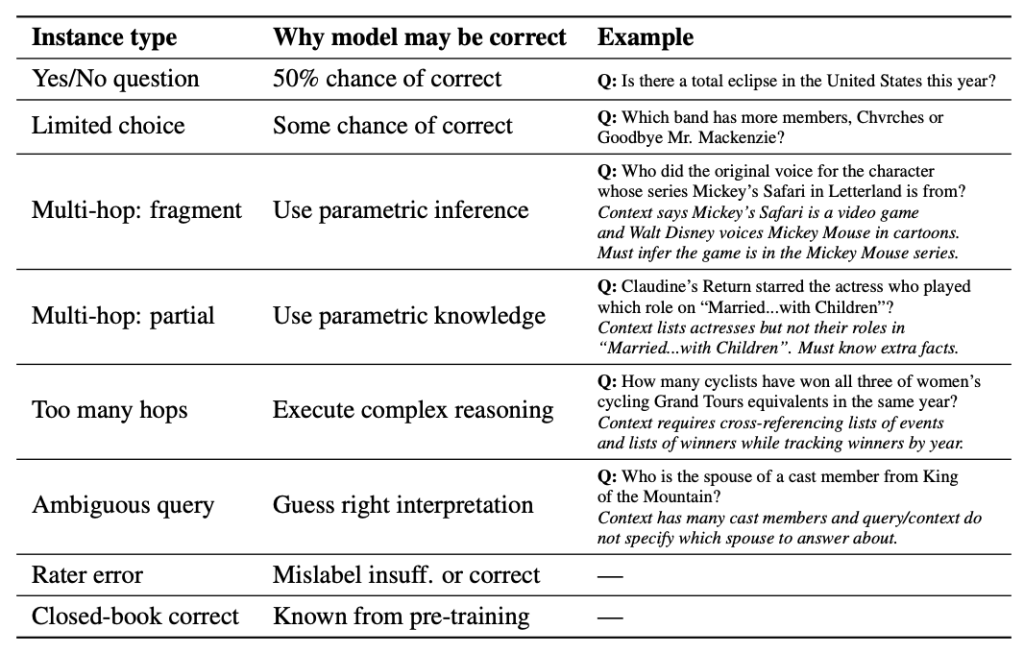
대신, 논문은 ‘충분한 맥락’ 자동 평가자 출력과 모델 자체 평가 신뢰도 점수를 결합하여 선택적 생성 프레임워크를 구축했습니다. 이 방법은 아래와 같은 장점을 가집니다:
- 제어 가능한 정확도-커버리지 트레이드오프: 모델이 답변할 입력의 비율(‘커버리지’)에 따라 정확도를 조절할 수 있습니다.
- 모델 자체 신뢰도와의 결합: P(True), P(Correct)와 같은 자체 평가 신뢰도와 ‘충분한 맥락’ 신호를 결합하여 환각을 예측하는 간단한 선형 모델을 훈련하고, 이를 사용하여 답변 여부를 결정합니다.
- 성능 개선: 이 방법은 모델 자체 신뢰도만 사용하는 것보다 더 나은 선택적 정확도-커버리지 트레이드오프를 가져왔으며, Gemini, GPT, Gemma 모델에서 모델이 답변한 질의 중 정답 비율을 2-10% 향상시켰습니다.
- 미세 조정(fine-tuning)과의 비교: ‘I don’t know’와 같은 답변으로 미세 조정을 시도한 결과, 정확도는 다소 향상될 수 있지만 환각률은 여전히 높고 삼가기 비율이 크게 늘어나지는 않았습니다. 이는 선택적 생성 메커니즘이 더 효과적일 수 있음을 시사합니다.
설명을 위한 예시 코드
import random
# --- 시뮬레이션 설정 ---
# 실제 논문에서는 LLM 기반 평가자 및 모델 자체 신뢰도 추정 모델을 사용합니다.
# 여기서는 개념 설명을 위해 간단한 함수로 결과를 시뮬레이션합니다.
def simulate_sufficient_context_autorater(query: str, context: str) -> bool:
"""
'충분한 맥락' 자동 평가자의 출력을 시뮬레이션합니다.
주어진 맥락이 질문에 답변하기에 충분한 정보를 포함하는지 여부를 반환합니다.
"""
# 실제 평가 로직 대신, 예시별 결과를 미리 정해두거나 간단한 규칙/랜덤성을 추가합니다.
if "지구에서 가장 높은 산은 무엇인가?" in query and "에베레스트" in context:
return True # 충분한 맥락
elif "화성의 대기는 어떤가?" in query and "산소가 거의 없음" in context:
return True # 충분한 맥락
elif "인류 최초로 달에 착륙한 사람은 누구인가?" in query and "닐 암스트롱" in context:
return True # 충분한 맥락
elif "우주여행 비용은?" in query and "비용 정보가 맥락에 없음" in context:
return False # 불충분한 맥락
elif "블랙홀 내부에서는 시간은 어떻게 흐르는가?" in query and "블랙홀 정보는 있으나 내부 시간 흐름 정보는 없음" in context:
return False # 불충분한 맥락 (전문 지식, 맥락에 없음)
elif "Lya L.는 누구와 결혼했는가?" in query: # 논문의 예시 [18, 19]
if "Lya L. married Paul in 2020" in context:
return True # 충분한 맥락
elif "Lya L. married Tom in 2006" in context: # 이전 결혼 정보만 있는 경우
return False # 불충분한 맥락 (현재 질문에 대한 최신 정보 부족)
else:
return False # 맥락이 충분치 않음
else:
# 다른 질문에 대해서는 랜덤으로 시뮬레이션 (실제는 논리 기반)
return random.choice([True, False])
def simulate_llm_response(query: str, context: str) -> tuple[str, float]:
"""
RAG를 사용하는 LLM의 응답과 자체 평가 신뢰도를 시뮬레이션합니다.
응답 (answer)과 신뢰도 (confidence, 0.0 ~ 1.0)를 반환합니다.
LLM은 맥락에 따라 응답하거나, 환각을 일으키거나, 삼가기도 합니다.
RAG 시스템에 맥락이 주어졌을 때 LLM이 생성하는 응답과 그 응답에 대한 LLM 자체의 신뢰도를 시뮬레이션합니다.
실제 LLM은 맥락과 사전 학습된 지식을 바탕으로 응답하겠지만, 여기서는 예시 시나리오에 따라 정답, 환각(오답), 또는 삼가기(모르겠다고 응답) 중
하나를 반환하고 임의의 신뢰도 점수를 부여합니다.
논문에서 지적하듯, 충분한 맥락이 있어도 환각이 발생할 수 있고, 불충분해도 신뢰도가 높거나 정답을 맞출 수도 있습니다.
이 시뮬레이션은 이러한 다양한 가능성을 반영합니다.
"""
# 실제 LLM 추론 및 신뢰도 추정 대신, 예시별 결과를 미리 정해둡니다.
if "지구에서 가장 높은 산은 무엇인가?" in query and "에베레스트" in context:
return "지구에서 가장 높은 산은 에베레스트입니다.", 0.95 # 정답, 높은 신뢰도
elif "화성의 대기는 어떤가?" in query and "산소가 거의 없음" in context:
return "화성 대기는 매우 희박하며, 대부분 이산화탄소로 이루어져 있고 산소가 거의 없습니다.", 0.90 # 정답, 높은 신뢰도
elif "인류 최초로 달에 착륙한 사람은 누구인가?" in query and "닐 암스트롱" in context:
return "인류 최초로 달에 착륙한 사람은 닐 암스트롱입니다.", 0.98 # 정답, 매우 높은 신뢰도
elif "우주여행 비용은?" in query and "비용 정보가 맥락에 없음" in context:
# 맥락이 불충분하지만, LLM이 자체 지식으로 답변을 시도하거나 환각을 일으킬 수 있음
# 이 예시에서는 환각을 시뮬레이션
return "우주여행 비용은 일반적으로 1000만원 정도입니다.", 0.70 # 환각, 중간 신뢰도
elif "블랙홀 내부에서는 시간은 어떻게 흐르는가?" in query and "블랙홀 정보는 있으나 내부 시간 흐름 정보는 없음" in context:
# 맥락이 불충분하고 전문적인 질문, LLM이 삼가거나 환각
# 이 예시에서는 삼가기를 시뮬레이션 (혹은 낮은 신뢰도와 함께 응답)
return "주어진 정보만으로는 블랙홀 내부에서의 시간 흐름을 정확히 알 수 없습니다.", 0.30 # 삼가기/불확실 답변, 낮은 신뢰도
elif "Lya L.는 누구와 결혼했는가?" in query:
if "Lya L. married Paul in 2020" in context:
return "Lya L.는 Paul과 결혼했습니다.", 0.92 # 정답, 높은 신뢰도
elif "Lya L. married Tom in 2006" in context: # 불충분한 맥락이지만 LLM이 답변 시도
return "Lya L.는 Tom과 결혼했습니다.", 0.80 # 환각 (이전 정보 기반), 중간 신뢰도
else: # 맥락이 거의 없는 경우
return "주어진 정보만으로는 알 수 없습니다.", 0.20 # 삼가기, 낮은 신뢰도
else:
# 다른 질문에 대해서는 랜덤 응답 및 신뢰도 시뮬레이션
return f"시뮬레이션된 답변: {random.random() > 0.5}", random.random()
# --- 선택적 생성 로직 (논문의 핵심 아이디어 반영) ---
def apply_selective_generation(
llm_answer: str,
llm_confidence: float,
is_sufficient_context: bool,
confidence_threshold: float = 0.7, # 일반적인 신뢰도 임계값
sufficient_context_bonus: float = 0.2 # 충분한 맥락일 때 추가 신뢰도 부여 (단순화된 로직)
) -> str:
"""
LLM의 응답, 신뢰도, 맥락 충분성 정보를 바탕으로 최종 답변 여부를 결정합니다.
이 함수가 논문의 핵심 아이디어인 '선택적 생성'을 시뮬레이션합니다. LLM이 생성한 답변과 신뢰도, 그리고 '충분한 맥락' 자동 평가자의 결과를 입력받습니다.
논문에서는 이 신호들을 결합하여 답변할지 말지(abstain)를 결정하는 모델을 학습시키지만, 예시 코드에서는 이해를 돕기 위해 간단하게
'충분한 맥락'이면 신뢰도에 가산점을 부여하고, 이렇게 조정된 신뢰도가 특정 임계값 이상일 때만 LLM의 답변을 최종 출력하도록 합니다.
그 외의 경우에는 "답변하기 어렵다"는 메시지를 출력하여 삼가는 동작을 시뮬레이션합니다.
이는 환각이 발생할 가능성이 높은 경우 답변을 차단함으로써 전체적인 신뢰도를 높이려는 전략입니다
"""
# 논문에서는 신뢰도와 충분성 신호를 선형 모델에 넣어 hallucination을 예측하고,
# 그 예측값에 임계값을 적용하여 답변 여부를 결정합니다 [17, 20].
# 여기서는 이해를 돕기 위해 간단한 규칙 기반으로 시뮬레이션합니다.
# 충분한 맥락일 때 신뢰도에 가산점을 부여하는 방식으로 '충분성' 신호를 활용합니다.
# 논문에서는 이를 결합하여 하나의 스코어를 만듭니다 [20].
adjusted_confidence = llm_confidence
if is_sufficient_context:
adjusted_confidence += sufficient_context_bonus # 충분한 맥락은 긍정적인 신호 [20]
# 조정된 신뢰도가 임계값 이상이면 답변, 아니면 삼가기
# 이는 논문에서 설명하는 "controllable trade-off"를 만드는 Thresholding 과정과 유사합니다 [17, 20].
if adjusted_confidence >= confidence_threshold:
# LLM이 이미 삼가기로 응답한 경우, 신뢰도가 낮더라도 삼가기로 결정해야 자연스러움
if "알 수 없습니다" in llm_answer or "모르겠습니다" in llm_answer or "주어진 정보" in llm_answer:
return f"최종 답변: 주어진 정보만으로는 답변이 어렵습니다. (신뢰도: {llm_confidence:.2f}, 맥락 충분: {is_sufficient_context}, 조정 신뢰도: {adjusted_confidence:.2f} < {confidence_threshold})"
else:
return f"최종 답변: {llm_answer} (신뢰도: {llm_confidence:.2f}, 맥락 충분: {is_sufficient_context}, 조정 신뢰도: {adjusted_confidence:.2f} >= {confidence_threshold})"
else:
# 신뢰도가 낮거나 불충분한 맥락으로 인해 답변을 삼가는 경우
return f"최종 답변: 답변하기에 정보가 불충분하거나 신뢰도가 낮습니다. 위 설정을 기반으로 데모를 실행해봅니다.
# --- 데모 실행 ---
# 예시 시나리오
scenarios = [
{
"query": "지구에서 가장 높은 산은 무엇인가?",
"context": "지구에서 가장 높은 산은 해발 8,848.86 미터의 에베레스트 산입니다.",
"description": "충분한 맥락, LLM 정답 및 높은 신뢰도 시뮬레이션"
},
{
"query": "우주여행 비용은?",
"context": "최근 스페이스X와 블루오리진이 민간 우주여행 상품을 개발 중이며 안전성 테스트를 진행하고 있습니다.",
"description": "불충분한 맥락 (비용 정보 없음), LLM 환각 및 중간 신뢰도 시뮬레이션"
},
{
"query": "블랙홀 내부에서는 시간은 어떻게 흐르는가?",
"context": "블랙홀은 엄청난 중력으로 빛조차 탈출할 수 없는 시공간 영역입니다. 특이점에서는 알려진 물리 법칙이 무너집니다.",
"description": "불충분한 맥락 (전문 지식 필요), LLM 삼가기 및 낮은 신뢰도 시뮬레이션"
},
{
"query": "Lya L.는 누구와 결혼했는가?",
"context": "Lya L. married Tom in 2006 and they divorced in 2014.", # 논문 예시 - 불충분 [18]
"description": "불충분한 맥락 (이전 결혼 정보만), LLM 환각 (오래된 정보 기반) 및 중간 신뢰도 시뮬레이션"
},
{
"query": "Lya L.는 누구와 결혼했는가?",
"context": "Lya L. married Paul in 2020. They looked happy together at the recent event.", # 논문 예시 - 충분 [18]
"description": "충분한 맥락 (현재 정보), LLM 정답 및 높은 신뢰도 시뮬레이션"
},
{
"query": "달 표면의 주요 구성 물질은?",
"context": "달 표면은 주로 현무암으로 이루어져 있으며, 레골리스라는 미세한 먼지 층으로 덮여 있습니다.",
"description": "충분한 맥락, LLM 정답 및 높은 신뢰도 시뮬레이션 (새로운 예시)"
},
{
"query": "최신 스마트폰의 배터리 지속 시간은?",
"context": "최신 스마트폰 모델들은 더 빠른 프로세서와 향상된 카메라 성능을 특징으로 합니다. 배터리 기술도 발전하여...", # 배터리 기술 발전 언급만 있음
"description": "불충분한 맥락 (구체적인 지속 시간 없음), LLM 환각 (추측성 답변) 및 중간 신뢰도 시뮬레이션"
},
]
print("--- RAG 시스템 선택적 생성 시뮬레이션 ---")
print("논문의 '충분한 맥락' 및 '모델 신뢰도'를 활용한 답변 결정 과정 예시")
print("-" * 40)
for i, scenario in enumerate(scenarios):
query = scenario["query"]
context = scenario["context"]
description = scenario["description"]
print(f"\n--- 시나리오 {i+1}: {description} ---")
print(f"질문: {query}")
print(f"제공된 맥락: {context}")
# 1. '충분한 맥락' 자동 평가자 시뮬레이션 [6]
is_sufficient = simulate_sufficient_context_autorater(query, context)
print(f"-> 시뮬레이션된 '충분한 맥락' 평가 결과: {is_sufficient}")
# 2. RAG LLM 응답 및 신뢰도 시뮬레이션 [13]
llm_answer, llm_confidence = simulate_llm_response(query, context)
print(f"-> 시뮬레이션된 LLM 응답: '{llm_answer}'")
print(f"-> 시뮬레이션된 LLM 신뢰도: {llm_confidence:.2f}")
# 3. 선택적 생성 로직 적용 (답변 결정) [16, 17]
final_output = apply_selective_generation(llm_answer, llm_confidence, is_sufficient)
print(final_output)
print("-" * 40)
print("--- 시뮬레이션 종료 ---")
print("이 코드는 논문의 아이디어를 설명하기 위한 예시이며, 실제 LLM 모델 및 평가 모델의 구현은 포함하지 않습니다.")
결론
이 논문은 ‘충분한 맥락’이라는 새로운 개념을 통해 RAG 시스템의 LLM 응답을 분석하는 신선한 시각을 제공했습니다. ‘충분한 맥락’ 자동 평가자를 통해 분석한 결과, LLM은 충분한 맥락이 있어도 환각을 자주 일으키며, 불충분한 맥락에서도 놀랍게도 정답을 맞추는 경우가 많다는 것을 발견했습니다. 이러한 분석을 바탕으로, ‘충분한 맥락’ 정보를 모델 자체 신뢰도와 결합한 선택적 생성 방법이 환각을 줄이고 RAG 시스템의 신뢰도를 향상시키는 효과적인 전략임을 말합니다. 이는 향후 RAG 시스템 연구 및 개발에 중요한 통찰을 제공합니다.
답글 남기기