




AI를 기반으로한 텍스트 인식 OCR은 나날이 발전해가고 있습니다.
최근 중국의 선도적인 AI 연구 기업 Zhipu AI(Z.ai)가 공개한 GLM-OCR은 이러한 문제를 해결하는 혁신적인 모델이 공개되었습니다. 단 0.9B(약 9억) 파라미터만으로 거대 모델에 버금가는 성능을 달성하며, ‘효율적인 AI’의 새로운 기록을 자랑하고 있습니다.
GLM-OCR이란?
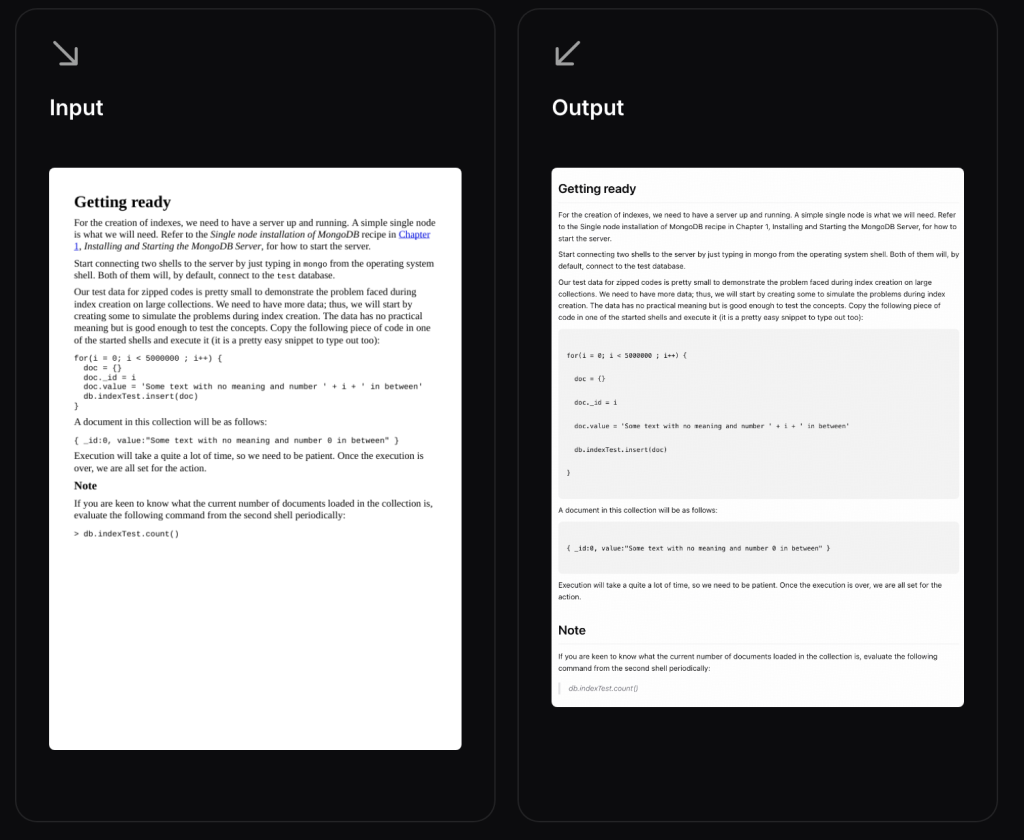
GLM-OCR은 GLM-V 아키텍처를 기반으로 구축된 멀티모달 OCR 모델로, 단순히 이미지 내 텍스트를 추출하는 것을 넘어 문서의 구조를 완벽하게 이해하고 이를 구조화된 데이터로 변환하는 데 특화되어 있습니다.
주요 특징
1. 뛰어난 성능 – SOTA 달성
GLM-OCR은 권위 있는 문서 파싱 벤치마크인 OmniDocBench V1.5에서 94.62점을 기록하며 현재 공개된 오픈소스 모델 중 최고 성능(SOTA)을 보여줍니다.
- 텍스트 인식: 인쇄된 텍스트, 손글씨, 수학 공식을 정확하게 인식
- 표 인식: 복잡한 셀 병합 구조도 HTML 형식으로 완벽 변환
- 정보 추출: 카드, 증명서, 영수증에서 구조화된 JSON 데이터 추출
- 수식 변환: 복잡한 수학 공식을 컴파일 가능한 LaTeX 코드로 변환
Gemini-3-Pro와 같은 거대 모델에 근접한 성능을 보이면서도, 파라미터 수는 훨씬 적어 효율성이 뛰어납니다.
2. 실전 최적화 – 복잡한 현실 시나리오 대응
GLM-OCR은 실제 비즈니스 환경을 고려하여 설계되었습니다:
- 코드 문서: 프로그래밍 코드가 포함된 기술 문서 인식
- 복잡한 표: 다중 병합 셀, 중첩된 표 구조 처리
- 인장/스탬프: 문서에 찍힌 도장 및 인장 인식
- 다국어 혼합: 한글, 영어, 한자가 혼재된 문서 처리
- 손글씨: 필기체 텍스트 인식
3. 초경량 & 고효율
- 0.9B 파라미터: 일반 게이밍 노트북(NVIDIA RTX 3060)에서도 구동 가능
- 낮은 VRAM 요구사항: FP16 정밀도 기준 약 4~6GB VRAM만 필요
- 빠른 처리 속도: PDF 1.86 페이지/초, 이미지 0.67장/초 처리
- 저렴한 비용: API 사용 시 백만 토큰당 $0.03
4. 고해상도 지원
최대 8K 해상도(7680×4320 픽셀)의 이미지를 처리할 수 있어, 대형 설계도면이나 포스터와 같은 복잡한 문서도 선명하게 인식합니다.
5. 다국어 지원
한국어, 영어, 중국어(간체/번체), 일본어, 프랑스어, 스페인어, 러시아어, 독일어 등 8개 언어를 인식합니다.
기술 아키텍처
GLM-OCR은 크게 세 가지 핵심 모듈로 구성됩니다:
1. CogViT Visual Encoder
- 대규모 이미지-텍스트 데이터로 사전 학습된 시각 인코더
- 고해상도 이미지의 특징(Feature)을 추출
- 텍스트 내용뿐만 아니라 폰트 크기, 굵기, 위치 정보 등 시각적 맥락도 학습
2. Cross-Modal Connector
- MLP(Multi-Layer Perceptron) 어댑터를 통해 시각 정보를 언어 토큰으로 변환
- 효율적인 토큰 다운샘플링으로 처리 속도 향상
3. GLM-0.5B Language Decoder
- 변환된 토큰을 해석하고 구조화된 텍스트로 출력
- Multi-Token Prediction(MTP) 손실 함수로 학습 효율성 향상
- 안정적인 강화학습을 통해 일반화 성능 개선
4. PP-DocLayout-V3 통합
- 문서 레이아웃 분석을 위한 2단계 파이프라인
- 레이아웃 분석 후 병렬 인식으로 다양한 문서 구조 처리
벤치마크 성능
OmniDocBench V1.5 비교
| 모델 | 점수 |
|---|---|
| GLM-OCR | 94.62 |
| 기타 오픈소스 모델 | 87-92 범위 |
| Gemini-3-Pro | ~95 |
실전 시나리오 평가
GLM-OCR은 6가지 핵심 실무 시나리오에서 내부 평가를 수행했으며, 다음 영역에서 뛰어난 성능을 보였습니다:



- 코드 문서 인식
- 실제 복잡한 표 처리
- 손글씨 인식
- 다국어 텍스트 처리
- 인장 인식
- 인보이스/영수증 데이터 추출
속도 비교
동일한 하드웨어 환경(단일 복제본, 단일 동시성)에서 테스트한 결과:
- PDF 문서: 1.86 페이지/초
- 이미지: 0.67 이미지/초
이는 유사한 모델 대비 현저히 빠른 처리 속도입니다.
설치 및 환경 요구사항
시스템 요구사항
- 가성비 구성: NVIDIA RTX 3060 (12GB) 또는 T4 (16GB) 가장 저렴한 비용으로 쾌적하게 서빙할 수 있는 구성입니다.
시스템 RAM: 8GB 이상, Disk: 10GB 이상의 여유 공간 (모델 가중치 파일 약 2~3GB) - 고성능 구성: NVIDIA RTX 4090 (24GB) 높은 처리량이 필요할 때 가장 추천하며, 모델이 작아 하나의 GPU에 여러 인스턴스를 띄우거나 아주 큰 배치 사이즈로 처리할 수 있습니다.
시스템 RAM: 16GB ~ 32GB, CPU: 최신 8코어 이상 (데이터 전처리 및 이미지 디코딩 부하 고려)
요약하자면, VRAM 4GB 이상의 엔비디아 GPU만 있다면 어디서든 실행 가능하며, 본격적인 서비스를 위해서는 16GB 이상의 VRAM을 가진 GPU를 추천합니다.
SDK 설치
GLM-OCR SDK를 설치하는 방법은 매우 간단합니다:
# pip를 통한 설치 pip install glmocr # 또는 소스에서 설치 git clone https://github.com/zai-org/glm-ocr.git cd glm-ocr && pip install -e . # transformers 최신 버전 설치 pip install git+https://github.com/huggingface/transformers.git
모델 배포 방법
GLM-OCR을 사용하는 두 가지 방법이 있습니다:
옵션 1: Zhipu MaaS API 사용 (권장)
GPU 없이 호스팅된 API를 사용하는 방법:
- open.bigmodel.cn에서 API 키 발급
config.yaml설정:
pipeline:
ocr_api:
api_host: open.bigmodel.cn
api_port: 443
api_scheme: https
api_key: your-api-key
옵션 2: 자체 호스팅 (vLLM / SGLang)
vLLM 사용
# vLLM 설치 pip install -U vllm --extra-index-url https://wheels.vllm.ai/nightly # 서비스 실행 vllm serve zai-org/GLM-OCR --allowed-local-media-path / --port 8080
SGLang 사용
# Docker 사용 docker pull lmsysorg/sglang:dev # 서비스 실행 python -m sglang.launch_server --model zai-org/GLM-OCR --port 8080
설정 업데이트:
pipeline:
ocr_api:
api_host: localhost
api_port: 8080
사용 예제
CLI 사용
# 단일 이미지 파싱 glmocr parse examples/source/code.png # 디렉토리 내 모든 이미지 파싱 glmocr parse examples/source/ # 출력 경로 지정 glmocr parse examples/source/code.png --output ./results/ # 커스텀 설정 사용 glmocr parse examples/source/code.png --config my_config.yaml # 디버그 모드로 프로파일링 활성화 glmocr parse examples/source/code.png --log-level DEBUG
Python API 사용
from glmocr import GlmOcr, parse
# 간단한 함수 호출
result = parse("image.png")
result = parse(["img1.png", "img2.jpg"])
result = parse("https://example.com/image.png")
result.save(output_dir="./results")
# 클래스 기반 API
with GlmOcr() as parser:
result = parser.parse("image.png")
print(result.json_result)
result.save()
OpenAI 호환 API 사용
import openai
client = openai.Client(
base_url="http://localhost:8080/v1",
api_key="EMPTY"
)
response = client.chat.completions.create(
model="zai-org/GLM-OCR",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "이미지의 표를 마크다운으로 변환해줘."},
{"type": "image_url", "image_url": {"url": "https://example.com/doc.jpg"}}
]
}]
)
print(response.choices[0].message.content)
Flask 서비스
# 서비스 시작 python -m glmocr.server # 디버그 로깅 활성화 python -m glmocr.server --log-level DEBUG
# API 호출
curl -X POST http://localhost:5002/glmocr/parse \
-H "Content-Type: application/json" \
-d '{"images": ["./example/source/code.png"]}'
출력 형식
GLM-OCR은 두 가지 출력 형식을 지원합니다:
1. JSON 형식
[
[{
"index": 0,
"label": "text",
"content": "...",
"bbox_2d": null
}]
]
2. Markdown 형식
# Document Title Body... | Table | Content | | ----- | ------- | | ... | ... |
출력 결과 구조 (입력당 하나의 폴더):
result.json– 구조화된 OCR 결과result.md– Markdown 결과imgs/– 레이아웃 모드 활성화 시 잘라낸 이미지 영역
주요 활용 사례
1. 텍스트 인식
사진, 스크린샷, 문서, 스캔본에서 텍스트 내용을 인식합니다. 인쇄된 텍스트, 손글씨, 수학 공식을 지원하며 교육, 연구, 사무 업무 등 다양한 시나리오에 적용 가능합니다.
변환 예시:
- 손으로 쓴 메모 → 편집 가능한 텍스트
- 수학 문제집 → LaTeX 코드
- 명함 → 연락처 정보
2. 표 인식
표 구조와 내용을 식별하여 HTML 형식으로 변환합니다. 표 데이터 입력, 변환, 편집이 필요한 시나리오에 적합합니다.
변환 예시:
- 복잡한 재무제표 → Markdown/HTML 테이블
- 실험 데이터 표 → 구조화된 JSON
- 병합된 셀이 있는 보고서 → 정확한 표 구조
3. 정보 구조화
각종 카드, 증명서, 영수증, 양식에서 핵심 정보를 추출하여 구조화된 JSON 데이터로 출력합니다. 은행, 보험, 정부 서비스, 법률, 물류 등 다양한 산업에 적용 가능합니다.
변환 예시:
- 신분증 → {이름, 주민등록번호, 주소, …}
- 영수증 → {날짜, 금액, 항목, 상점명, …}
- 계약서 → 핵심 조항 추출
4. RAG (검색 증강 생성) 파이프라인
대량의 문서를 높은 정확도로 인식 및 파싱하고 표준화된 출력 형식을 제공하여 RAG 시스템의 견고한 기반을 제공합니다.
장점:
- 구조화된 Markdown으로 변환하여 벡터 데이터베이스에 저장
- LLM의 문맥 파악 정확도 향상
- 전체 AI 서비스 품질 개선
기존 OCR 솔루션과의 차별성
vs. 전통적인 OCR (Tesseract 등)
| 특징 | 전통적 OCR | GLM-OCR |
|---|---|---|
| 문서 구조 이해 | 텍스트만 추출 | 레이아웃, 표, 수식 구조 파악 |
| 복잡한 표 처리 | 순서 뒤섞임 | 셀 병합 구조 완벽 재현 |
| 수식 변환 | 이미지로만 인식 | LaTeX 코드로 변환 |
| 출력 형식 | 일반 텍스트 | Markdown, JSON, HTML |
vs. 거대 멀티모달 모델 (GPT-4o, Gemini 1.5 Pro)
| 특징 | 거대 모델 | GLM-OCR |
|---|---|---|
| 파라미터 수 | 수백억~수천억 | 0.9B |
| VRAM 요구량 | 80GB+ | 4-6GB |
| 처리 속도 | 느림 | 빠름 (1.86 페이지/초) |
| 비용 | 높음 | 저렴 ($0.03/M tokens) |
| 온프레미스 배포 | 어려움 | 용이함 |
| 문서 처리 최적화 | 범용적 | 특화됨 |
핵심 차별점
- 효율성: 10억 개 미만의 파라미터로 특정 도메인(문서 처리)에서 거대 모델 수준의 성능
- 접근성: 일반 소비자용 그래픽 카드에서도 구동 가능
- 비용: 클라우드 API 비용이 낮고, 자체 호스팅 시 서버 비용 절감
- 보안: 온프레미스 배포로 기밀 문서 처리 시 데이터 유출 위험 없음
- 속도: 동일 하드웨어에서 더 많은 문서를 더 빠르게 처리
모듈형 아키텍처 – 커스터마이징 가능
GLM-OCR은 조합 가능한 모듈 구조로 설계되어 쉽게 커스터마이징할 수 있습니다:
| 컴포넌트 | 설명 |
|---|---|
PageLoader | 전처리 및 이미지 인코딩 |
OCRClient | GLM-OCR 모델 서비스 호출 |
PPDocLayoutDetector | PP-DocLayout 레이아웃 감지 |
ResultFormatter | 후처리, JSON/Markdown 출력 |
커스텀 파이프라인 생성 예시:
from glmocr.dataloader import PageLoader
from glmocr.ocr_client import OCRClient
from glmocr.postprocess import ResultFormatter
class MyPipeline:
def __init__(self, config):
self.page_loader = PageLoader(config)
self.ocr_client = OCRClient(config)
self.formatter = ResultFormatter(config)
def process(self, request_data):
# 자신만의 처리 로직 구현
pass
라이선스
GLM-OCR 프로젝트는 구성 요소별로 다른 라이선스가 적용됩니다:
- GLM-OCR 모델 가중치: MIT License (상업적 이용 가능)
- 레이아웃 분석 코드 (PP-DocLayout-V3) 및 리포지토리 코드: Apache License 2.0
프로젝트 활용 시 두 가지 라이선스 정책을 모두 준수해야 합니다.
실전 적용 분야
GLM-OCR은 다양한 산업 분야에서 활용될 수 있습니다:
금융 & 보험
- 계약서, 증명서 자동 데이터 추출
- 청구서, 영수증 처리
- 신용평가를 위한 문서 분석
법률
- 법률 문서 디지털화
- 계약서 핵심 조항 자동 추출
- 판례 검색을 위한 문서 구조화
연구 & 교육
- 논문 PDF를 편집 가능한 형식으로 변환
- 수학 공식 LaTeX 변환
- 교재 디지털화
헬스케어
- 의료 기록 디지털화
- 처방전 자동 읽기
- 진단서 정보 구조화
물류 & 유통
- 운송장 자동 처리
- 재고 관리 문서화
- 송장 정보 추출
마치며
GLM-OCR은 단순히 작은 모델이 아닙니다. 효율성과 성능을 동시에 달성하며, 실무에서 즉시 활용 가능한 수준의 완성도를 갖춘 프로덕션 레디 솔루션입니다.
GLM-OCR의 핵심 가치
- 민주화된 AI: 고가의 GPU 없이도 고성능 OCR 서비스 구축 가능
- 프라이버시 보호: 온프레미스 배포로 기밀 문서 안전하게 처리
- 비용 효율성: 클라우드 API 비용 절감 및 자체 인프라 비용 최소화
- 즉시 사용 가능: 상세한 SDK와 문서, 다양한 배포 옵션 제공
특히 기밀 문서를 다루는 금융, 법률, 연구 분야에서 큰 파급력을 가질 것으로 예상되며, RAG 시스템의 전처리 도구로서도 매우 높은 가치를 제공합니다.
참고 자료
- 공식 문서: https://docs.z.ai/guides/vlm/glm-ocr
- GitHub 저장소: https://github.com/zai-org/GLM-OCR
- Hugging Face 모델: https://huggingface.co/zai-org/GLM-OCR
- ModelScope: https://modelscope.cn/models/ZhipuAI/GLM-OCR
- PyTorch 한국 사용자 모임: https://discuss.pytorch.kr/t/glm-ocr-0-9b-sota-ocr-feat-z-ai/8956
답글 남기기