




문서와 이미지를 구조화된 AI 친화적 데이터로 변환하는 최첨단 솔루션인 PaddleOCR를 소개합니다. 텍스트 추출부터 지능형 문서 이해까지 엔드투엔드 솔루션을 제공하는 이 도구는 개인 개발자부터 대기업까지 전 세계적으로 AI 애플리케이션을 지원하고 있습니다.

PaddleOCR의 핵심 가치
PaddleOCR는 문서와 이미지를 JSON, Markdown과 같은 구조화된 AI 친화적 데이터로 업계 최고의 정확도로 변환합니다. 5만 개 이상의 GitHub 스타를 보유하고 MinerU, RAGFlow, OmniParser와 같은 주요 프로젝트에 깊이 통합되어 있어, AI 시대의 지능형 문서 애플리케이션을 구축하는 개발자들에게 최고의 솔루션으로 자리매김했습니다.
PaddleOCR 3.0의 핵심 기능
1. PaddleOCR-VL – 0.9B VLM을 통한 다국어 문서 파싱
문서 파싱을 위해 특별히 설계된 최첨단 리소스 효율적 모델로, 109개 언어를 지원하며 텍스트, 표, 수식, 차트와 같은 복잡한 요소를 인식하는 데 탁월합니다. 최소한의 리소스 소비를 유지하면서도 뛰어난 성능을 제공합니다.



2. PP-OCRv5 — 범용 장면 텍스트 인식
단일 모델로 간체 중국어, 번체 중국어, 영어, 일본어, 병음 등 5가지 텍스트 유형을 지원하며 이전 버전보다 13% 정확도가 향상되었습니다. 다국어가 혼합된 문서 인식 문제를 효과적으로 해결합니다.


3. PP-StructureV3 — 복잡한 문서 파싱
복잡한 PDF와 문서 이미지를 원래 구조를 보존하는 Markdown 및 JSON 파일로 지능적으로 변환합니다. 공개 벤치마크에서 수많은 상용 솔루션보다 뛰어난 성능을 발휘하며, 문서 레이아웃과 계층적 구조를 완벽하게 유지합니다.

4. PP-ChatOCRv4 — 지능형 정보 추출
ERNIE 4.5를 네이티브로 통합하여 대량의 문서에서 핵심 정보를 정확하게 추출하며, 이전 세대보다 15% 정확도가 향상되었습니다. 문서가 질문을 “이해”하고 정확한 답변을 제공할 수 있게 합니다.
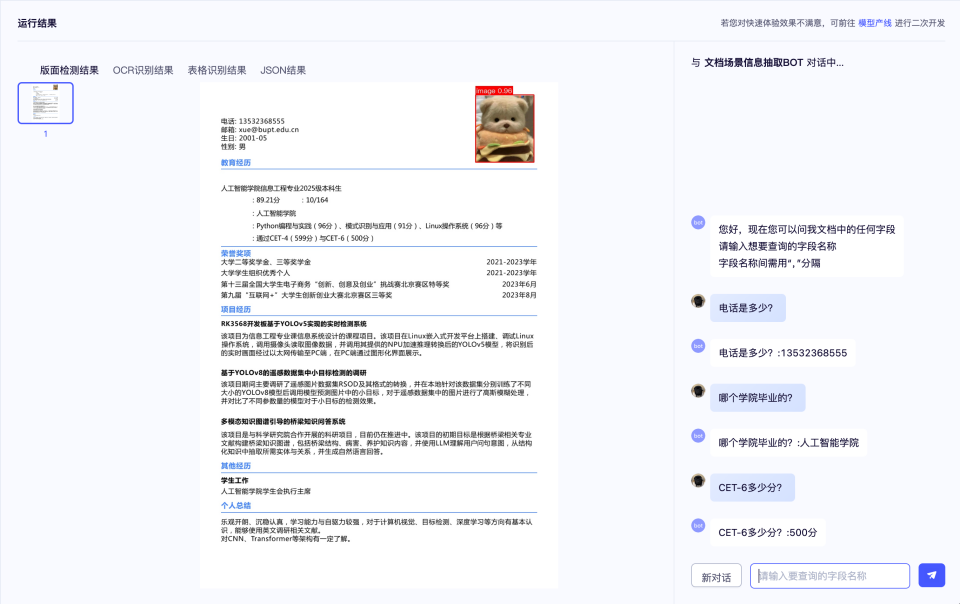
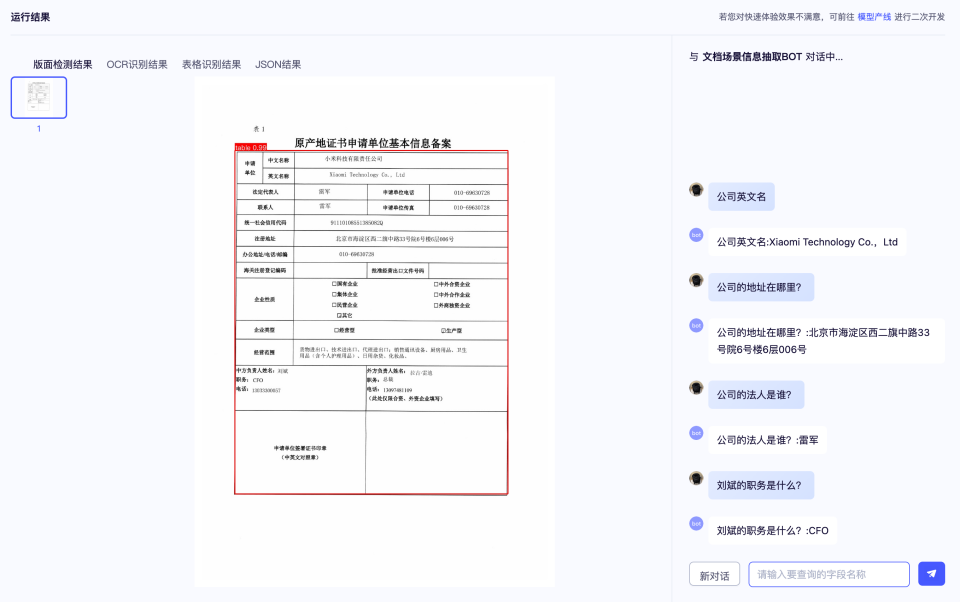
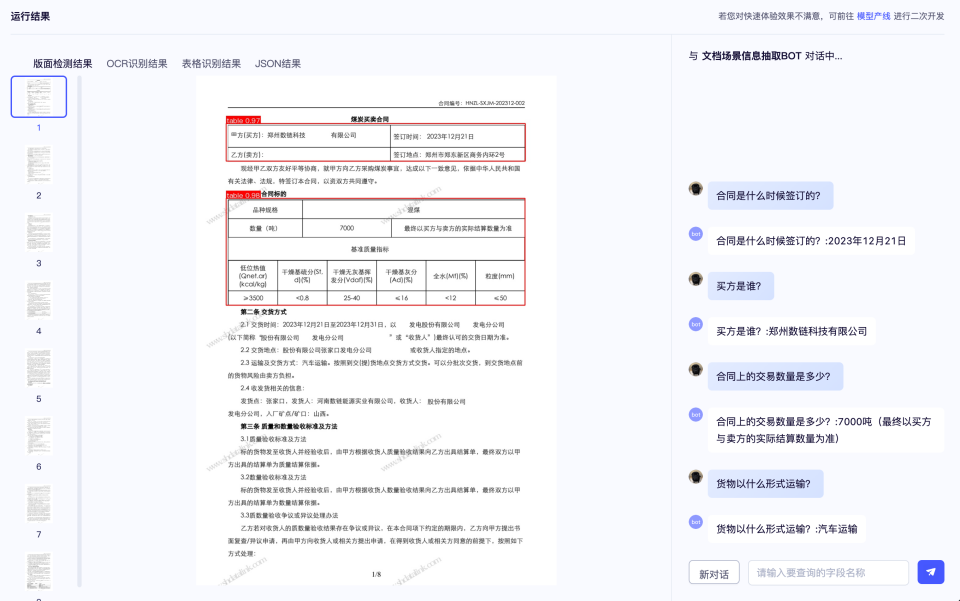
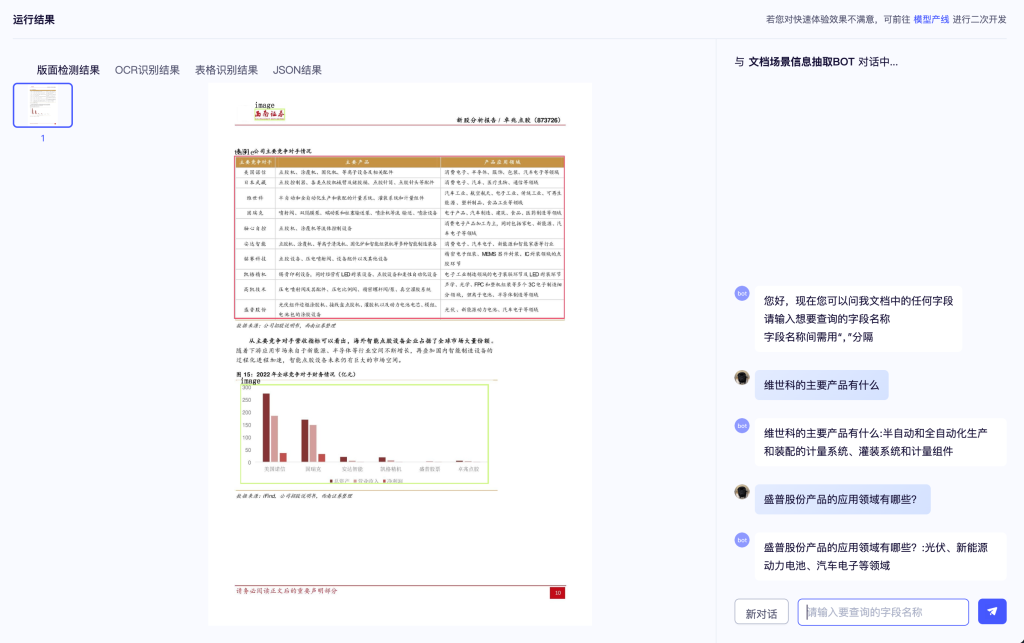
PaddleOCR 3.0은 뛰어난 모델 라이브러리를 제공할 뿐만 아니라 모델 훈련, 추론, 서비스 배포를 포괄하는 사용자 친화적인 도구도 제공하여 개발자가 AI 애플리케이션을 신속하게 프로덕션에 적용할 수 있도록 지원합니다.
주요 업데이트 소식
PaddleOCR는 지속적인 발전을 이어가고 있으며, 최근 주요 업데이트는 다음과 같습니다:
2025.10.16: PaddleOCR 3.3.0 출시
- PaddleOCR-VL 출시: 문서 파싱을 위한 최첨단 리소스 효율적 모델
- PP-OCRv5 다국어 인식 모델 출시: 라틴 스크립트 인식의 정확도와 범위 개선
PaddleOCR-VL은 문서 파싱을 위해 특별히 설계된 최첨단 리소스 효율적 모델입니다. 핵심 구성 요소는 PaddleOCR-VL-0.9B로, NaViT 스타일의 동적 해상도 시각 인코더와 ERNIE-4.5-0.3B 언어 모델을 통합한 컴팩트하면서도 강력한 비전-언어 모델(VLM)입니다. 이 혁신적인 모델은 109개 언어를 효율적으로 지원하고 텍스트, 표, 수식, 차트와 같은 복잡한 요소를 인식하는 데 탁월하면서도 최소한의 리소스 소비를 유지합니다.
PaddleOCR-VL의 핵심 특징:
- 컴팩트하면서도 강력한 VLM 아키텍처: 리소스 효율적인 추론을 위해 특별히 설계된 비전-언어 모델로, 요소 인식에서 뛰어난 성능을 발휘합니다.
- 문서 파싱에서의 최고 성능: 페이지 수준 문서 파싱과 요소 수준 인식 모두에서 최첨단 성능을 달성합니다.
- 다국어 지원: 109개 언어를 지원하여 중국어, 영어, 일본어, 라틴어, 한국어를 포함한 주요 글로벌 언어와 러시아어(키릴 문자), 아랍어, 힌디어(데바나가리 문자), 태국어와 같은 다양한 스크립트와 구조를 가진 언어를 지원합니다.
PaddleOCR 시작하기
1. 설치 방법
PaddleOCR를 사용하기 위해서는 먼저 PaddlePaddle을 설치한 후 PaddleOCR 툴킷을 설치해야 합니다.
기본 텍스트 인식 기능만 사용하려면 다음 명령어를 실행하세요:
python -m pip install paddleocr
문서 파싱, 문서 이해, 문서 번역, 핵심 정보 추출 등 모든 기능을 사용하려면 다음 명령어를 실행하세요:
python -m pip install "paddleocr[all]"
버전 3.2.0부터 PaddleOCR는 위에 표시된 all 종속성 그룹 외에도 다른 종속성 그룹을 지정하여 부분적인 선택적 기능을 설치할 수 있습니다:
- doc-parser: 문서 파싱 – 표, 수식, 도장, 이미지 등과 같은 레이아웃 요소를 문서에서 추출하는 데 사용할 수 있습니다.
- ie: 정보 추출 – 이름, 날짜, 주소, 금액 등과 같은 핵심 정보를 문서에서 추출하는 데 사용할 수 있습니다.
- trans: 문서 번역 – 문서를 한 언어에서 다른 언어로 번역하는 데 사용할 수 있습니다.
- all: 완전한 기능
2. CLI를 통한 추론 실행
PP-OCRv5 추론 실행:
paddleocr ocr -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --use_doc_orientation_classify False --use_doc_unwarping False --use_textline_orientation False
PP-StructureV3 추론 실행:
paddleocr pp_structurev3 -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_structure_v3_demo.png --use_doc_orientation_classify False --use_doc_unwarping False
PP-ChatOCRv4 추론 실행(먼저 Qianfan API 키 필요):
paddleocr pp_chatocrv4_doc -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_certificate-1.png -k 驾驶室准乘人数 --qianfan_api_key your_api_key --use_doc_orientation_classify False --use_doc_unwarping False
PaddleOCR-VL 추론 실행:
paddleocr doc_parser -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png
3. API를 통한 추론 실행
3.1 PP-OCRv5 예제
# PaddleOCR 인스턴스 초기화
from paddleocr import PaddleOCR
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False)
# 샘플 이미지에서 OCR 추론 실행
result = ocr.predict(
input="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png")
# 결과 시각화 및 JSON 결과 저장
for res in result:
res.print()
res.save_to_img("output")
res.save_to_json("output")
PaddleOCR의 고급 기능
1. 모델을 ONNX 형식으로 변환
PaddleOCR 모델을 ONNX 형식으로 변환하여 다양한 플랫폼에서 활용할 수 있습니다. 이를 통해 OpenVINO, ONNX Runtime, TensorRT와 같은 엔진을 사용하여 추론을 가속화할 수 있습니다.
2. 다중 GPU 및 다중 프로세스를 사용한 추론 가속화
대량의 문서를 처리할 때 다중 GPU 및 다중 프로세스를 활용하여 파이프라인 추론을 병렬화하고 처리 속도를 크게 향상시킬 수 있습니다.
3. 다양한 프로그래밍 언어 통합
PaddleOCR를 C++, C#, Java 등으로 작성된 애플리케이션에 통합하여 다양한 환경에서 OCR 기능을 활용할 수 있습니다.
PaddleOCR를 활용한 멋진 프로젝트들
PaddleOCR는 활발한 커뮤니티의 지원 없이는 오늘날의 위치에 도달할 수 없었습니다. 오랜 파트너, 새로운 협력자, 그리고 PaddleOCR에 열정을 쏟은 모든 분들께 감사드립니다.
- RAGFlow: 깊은 문서 이해를 기반으로 한 RAG 엔진
- MinerU: 다양한 유형의 문서를 Markdown으로 변환하는 도구
- Umi-OCR: 무료, 오픈소스, 배치 오프라인 OCR 소프트웨어
- OmniParser: 순수 비전 기반 GUI 에이전트를 위한 화면 파싱 도구
- QAnything: 모든 것에 기반한 질문과 답변
- PDF-Extract-Kit: 복잡하고 다양한 PDF 문서에서 고품질 콘텐츠를 효율적으로 추출하도록 설계된 강력한 오픈소스 툴킷
- Dango-Translator: 화면의 텍스트를 인식하고 번역한 후 실시간으로 번역 결과를 표시
PaddleOCR의 특별 주의사항
PaddleOCR 3.x는 여러 중요한 인터페이스 변경을 도입했습니다. PaddleOCR 2.x를 기반으로 작성된 이전 코드는 PaddleOCR 3.x와 호환되지 않을 가능성이 높습니다. 사용 중인 PaddleOCR 버전과 일치하는 문서를 참조하시기 바랍니다.
PaddleOCR 3.0의 주요 개선 사항
1. 다국어 지원 강화
PP-OCRv5 다국어 인식 모델은 라틴 스크립트 인식의 정확도와 범위를 개선했으며, 키릴 문자, 아랍어, 데바나가리, 텔루구어, 타밀어 등 다양한 언어 시스템 지원을 추가하여 총 109개 언어의 인식을 지원합니다. 모델은 단 2M 매개변수만 가지고 있으며, 일부 모델의 정확도는 이전 세대에 비해 40% 이상 향상되었습니다.
2. 리소스 효율성 개선
PaddleOCR-VL은 문서 파싱을 위해 특별히 설계된 비전-언어 모델로, 리소스 효율적인 추론을 위해 특별히 설계되었습니다. NaViT 스타일의 동적 고해상도 시각 인코더와 경량 ERNIE-4.5-0.3B 언어 모델을 통합하여 모델의 인식 기능과 디코딩 효율성을 크게 향상시켰습니다. 이 통합은 계산 요구 사항을 줄이면서도 높은 정확도를 유지하여 효율적이고 실용적인 문서 처리 애플리케이션에 적합합니다.
3. 문서 파싱 성능 향상
PaddleOCR-VL은 페이지 수준 문서 파싱과 요소 수준 인식 모두에서 최첨단 성능을 달성합니다. 기존의 파이프라인 기반 솔루션보다 크게 성능이 우수하며 문서 파싱에서 최고의 비전-언어 모델(VLM)과 강한 경쟁력을 보여줍니다. 또한 텍스트, 표, 수식, 차트와 같은 복잡한 문서 요소를 인식하는 데 탁월하여 손글씨 텍스트와 역사적 문서를 포함한 다양한 도전적인 콘텐츠 유형에 적합합니다.
PaddleOCR 사용 시 팁
- PaddleOCR는 이제 Claude Desktop과 같은 Agent 애플리케이션과의 통합을 지원하는 MCP 서버를 제공합니다.
- PaddleOCR 3.0 기술 보고서와 PaddleOCR-VL 기술 보고서를 참조하여 더 자세한 기술적 정보를 얻을 수 있습니다.
- 중국 이종 AI 가속기(화웨이 Ascend, KUNLUNXIN)와의 호환성도 지원됩니다.
결론
PaddleOCR는 텍스트 추출부터 지능형 문서 이해까지 엔드투엔드 솔루션을 제공하는 산업 선도적인 OCR 및 문서 AI 엔진입니다. 109개 언어 지원, 복잡한 문서 요소 인식, 정보 추출 등 다양한 기능을 갖춘 이 도구는 개인 개발자부터 대기업까지 AI 시대의 문서 처리 요구 사항을 충족시키는 최고의 솔루션입니다.
PaddleOCR 저장소에 스타를 눌러 흥미로운 업데이트와 새로운 릴리스를 계속 확인하세요. 강력한 OCR 및 문서 파싱 기능이 포함되어 있습니다!
이 프로젝트는 Apache 2.0 라이선스로 제공됩니다.
답글 남기기