




AI산업에서 문서의 디지털화는 이제 필수 입니다. 특히 OCR영역은 그 정확도를 다투는 매루 치열한 영역이며, 최근 공개된 이 모델도 더 높은 벤치마크 성능을 자랑하며 새롭게 등장한 OCR모델입니다.
오늘은 그 최신 OCR 모델인 Chandra에 대해 자세히 알아보겠습니다. Chandra는 Datalab에서 개발된 AI OCR모델로, 이미지와 PDF를 구조화된 HTML, Markdown, JSON으로 변환하면서 레이아웃 정보까지 완벽하게 보존하는 고정밀 OCR 모델입니다.
Chandra의 주요 특징
Chandra는 기존 OCR 솔루션과 차별화되는 여러 특징을 제공합니다:
- 문서를 Markdown, HTML, JSON으로 변환하면서 상세한 레이아웃 정보 보존
- 우수한 필기체 인식 지원
- 체크박스를 포함한 양식 정확한 재구성
- 표, 수식, 복잡한 레이아웃에 대한 탁월한 지원
- 이미지와 다이어그램 추출 및 캡션과 구조화된 데이터 제공
- 40개 이상의 언어 지원
- 두 가지 추론 모드: 로컬(HuggingFace)과 원격(vLLM 서버)
기존 LLM 기반 OCR과 Chandra의 차이점
최근 LLM(대규모 언어 모델) 기반 OCR 솔루션이 많이 등장했지만, Chandra는 몇 가지 중요한 차별점을 가지고 있습니다:
아래의 비교 자료와 같이, 손글씨, 수식, 표에 매우 뛰어난 결과를 보여주고 있습니다.
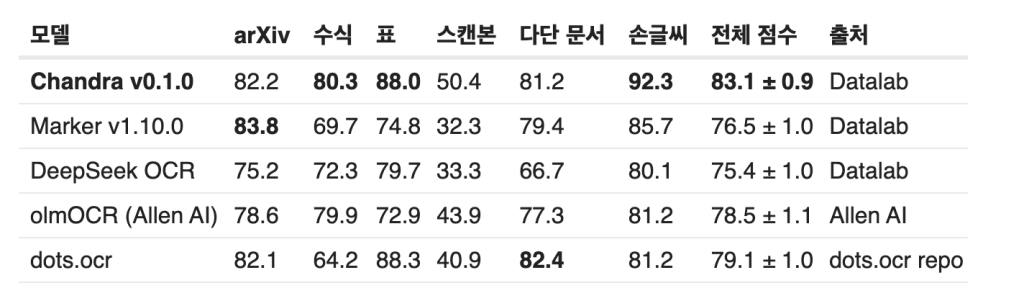
1. 정확도 측면에서의 우수성
Chandra는 olmocr 벤치마크에서 83.1%의 전체 점수를 기록하며 다른 OCR 솔루션들을 크게 앞서고 있습니다. 특히 GPT-4o(69.9%), Gemini Flash 2(63.8%), Qwen 3 VL 8B(64.6%) 등 유명한 LLM 기반 OCR 솔루션보다 훨씬 높은 성능을 보여줍니다.
2. 레이아웃 보존 능력
기존 LLM 기반 OCR은 텍스트 추출에는 강하지만 원본 문서의 레이아웃 정보를 보존하는 데 어려움을 겪습니다. Chandra는 문서의 구조적 정보를 유지하면서 HTML, Markdown, JSON 형식으로 변환할 수 있어 원본 문서의 가독성과 의미를 그대로 유지합니다.
3. 특수 문서 처리 능력
Chandra는 수학 공식(88.0%), 다열 레이아웃(81.2%), 작은 텍스트(92.3%) 등 특수한 문서 형식에서 특히 뛰어난 성능을 보입니다. 이는 GPT-4o나 Gemini Flash 2와 같은 일반적인 LLM이 어려움을 겪는 영역입니다.
4. 로컬 실행 옵션
대부분의 LLM 기반 OCR은 API를 통해서만 접근 가능하지만, Chandra는 HuggingFace 방식을 통해 로컬에서 실행할 수 있는 옵션을 제공합니다. 이는 데이터 프라이버시가 중요한 상황이나 인터넷 연결이 제한된 환경에서 큰 장점이 됩니다.
Chandra 시작하기
설치 방법
Chandra를 시작하는 가장 쉬운 방법은 CLI 도구를 사용하는 것입니다:
패키지 설치:
pip install chandra-ocr
HuggingFace 방식을 사용할 계획이라면 flash attention도 함께 설치하는 것이 좋습니다.
소스에서 설치:
git clone https://github.com/datalab-to/chandra.git
cd chandra
uv sync
source .venv/bin/activate
빠른 시작 가이드
vLLM 서버를 사용하는 방법:
# vLLM 서버 시작 chandra_vllm # 문서 처리 chandra input.pdf ./output
HuggingFace 방식으로 사용하는 방법:
chandra input.pdf ./output --method hf
대화형 Streamlit 앱 실행:
chandra_app
Chandra의 활용 사례
Chandra는 다양한 유형의 문서를 처리할 수 있어 여러 분야에서 활용될 수 있습니다:
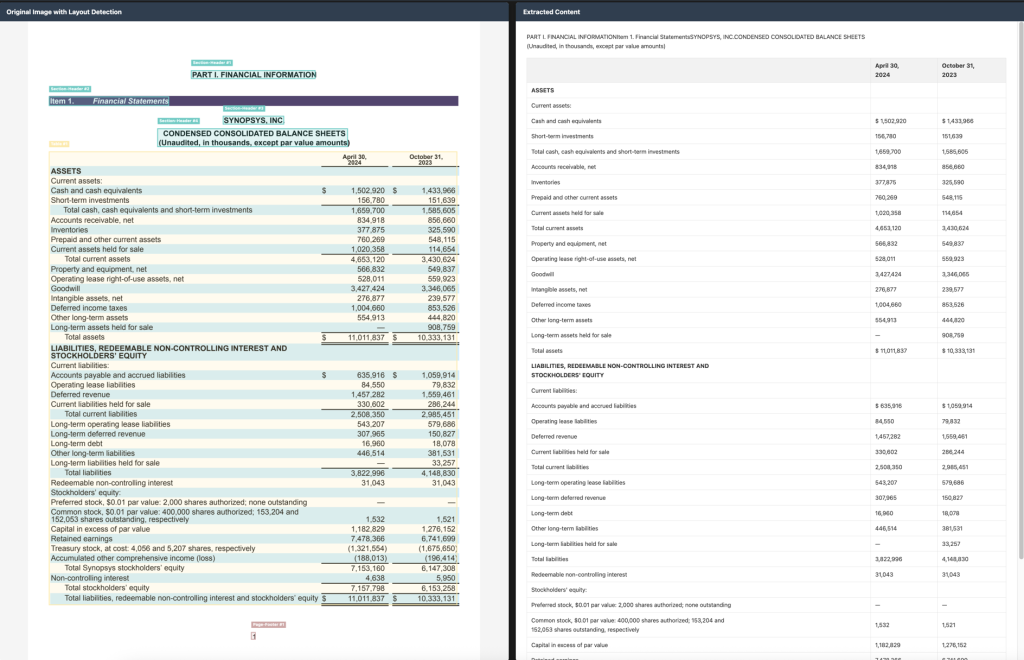
1. 표 및 양식 처리
Chandra는 복잡한 표와 양식을 정확하게 인식하고 구조화된 데이터로 변환합니다. 수해 피해 양식, 10K 파일링, 임대 계약서 등 다양한 비즈니스 문서를 효과적으로 처리할 수 있습니다.
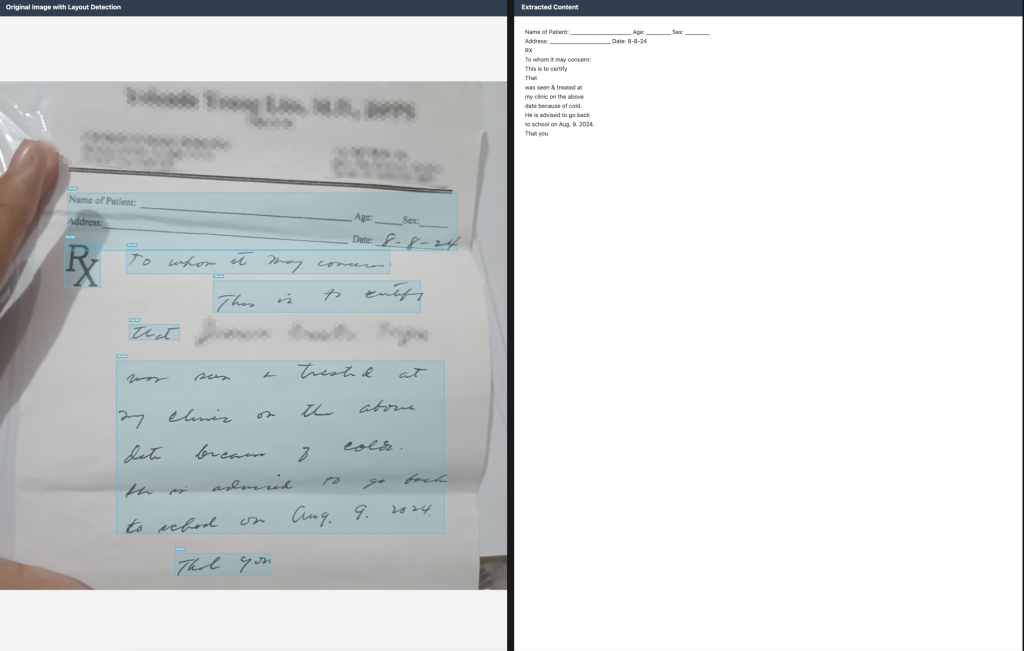
2. 필기체 인식
의사의 처방전이나 수학 숙제와 같은 필기체 문서도 높은 정확도로 인식합니다. 이는 의료 기록 디지털화나 교육 분야에서 특히 유용합니다.
3. 책과 교과서
지리 교과서나 연습 문제집과 같은 책도 레이아웃을 유지하면서 디지털 형식으로 변환할 수 있습니다.

4. 수학 문서
수학 공식과 다이어그램이 포함된 문서도 정확하게 인식합니다. 이는 학술 연구나 교육 자료 디지털화에 큰 도움이 됩니다.

5. 신문 및 다열 문서
뉴욕 타임스나 LA 타임스와 같은 신문 기사도 다열 레이아웃을 유지하면서 처리할 수 있습니다.

Chandra의 성능 벤치마크
Chandra는 olmocr 벤치마크에서 다양한 문서 유형에 대해 우수한 성능을 보여주고 있습니다:
- ArXiv: 82.2%
- 오래된 스캔 문서: 80.3%
- 수학 문서: 88.0%
- 표: 50.4%
- 오래된 스캔 문서의 헤더와 푸터: 90.8%
- 다열 문서: 81.2%
- 작은 텍스트: 92.3%
- 기본 텍스트: 99.9%
- 전체 점수: 83.1% ± 0.9
이는 다른 주요 OCR 솔루션과 비교했을 때 상당히 높은 점수입니다:
- Datalab Marker v1.10.0: 76.5% ± 1.0
- Mistral OCR API: 72.0% ± 1.1
- Deepseek OCR: 75.4% ± 1.0
- GPT-4o (Anchored): 69.9% ± 1.1
- Gemini Flash 2 (Anchored): 63.8% ± 1.2
- Qwen 3 VL 8B: 64.6% ± 1.1
- olmOCR v0.3.0: 78.5% ± 1.1
- dots.ocr: 79.1% ± 1.0
Chandra CLI 사용법 상세 가이드
단일 파일 또는 디렉토리 처리
vLLM 서버를 사용한 단일 파일 처리:
chandra input.pdf ./output --method vllm
로컬 모델을 사용한 디렉토리 내 모든 파일 처리:
chandra ./documents ./output --method hf
CLI 옵션
--method [hf|vllm]: 추론 방식 (기본값: vllm)--page-range TEXT: PDF의 페이지 범위 (예: “1-5,7,9-12”)--max-output-tokens INTEGER: 페이지당 최대 토큰 수--max-workers INTEGER: vLLM용 병렬 워커 수--include-images/--no-images: 이미지 추출 및 저장 여부 (기본값: 포함)--include-headers-footers/--no-headers-footers: 페이지 헤더/푸터 포함 여부 (기본값: 제외)--batch-size INTEGER: 배치당 페이지 수 (기본값: 1)
출력 구조
처리된 각 파일은 다음과 같은 하위 디렉토리를 생성합니다:
<filename>.md– Markdown 출력<filename>.html– HTML 출력<filename>_metadata.json– 메타데이터 (페이지 정보, 토큰 수 등)images/– 문서에서 추출된 이미지
vLLM 서버 설정 (선택 사항)
프로덕션 배포나 배치 처리를 위해 vLLM 서버를 사용할 수 있습니다:
chandra_vllm
이 명령은 최적화된 추론 설정으로 Docker 컨테이너를 실행합니다. 환경 변수를 통해 구성할 수 있습니다:
VLLM_API_BASE: 서버 URL (기본값: http://localhost:8000/v1)VLLM_MODEL_NAME: 서버용 모델 이름 (기본값: chandra)VLLM_GPUS: GPU 장치 ID (기본값: 0)
datalab-to/chandra 모델로 자체 vllm 서버를 시작할 수도 있습니다.
Chandra 설정
환경 변수나 local.env 파일을 통해 설정을 구성할 수 있습니다:
# 모델 설정 MODEL_CHECKPOINT=datalab-to/chandra MAX_OUTPUT_TOKENS=8192 # vLLM 설정 VLLM_API_BASE=http://localhost:8000/v1 VLLM_MODEL_NAME=chandra VLLM_GPUS=0
LLM 기반 OCR의 한계와 Chandra의 해결책
기존 LLM 기반 OCR 솔루션들은 몇 가지 중요한 한계를 가지고 있습니다:
1. 레이아웃 보존의 어려움
GPT-4o나 Gemini Flash 2와 같은 일반 LLM은 이미지에서 텍스트를 추출할 수는 있지만, 원본 문서의 복잡한 레이아웃을 보존하는 데 어려움을 겪습니다. Chandra는 문서의 구조적 정보를 정확히 파악하고 HTML, Markdown, JSON으로 변환하여 원본 레이아웃을 최대한 유지합니다.
2. 특수 문서 형식 처리의 한계
수학 공식, 표, 다열 레이아웃과 같은 특수 문서 형식은 일반 LLM에게 큰 도전입니다. Chandra는 이러한 특수 문서 형식을 위해 특별히 최적화되어 있어 훨씬 높은 정확도를 제공합니다.
3. 리소스 효율성
대규모 LLM은 이미지 처리에 많은 컴퓨팅 리소스를 필요로 합니다. Chandra는 OCR 작업에 최적화되어 있어 더 효율적으로 리소스를 사용합니다.
4. 프라이버시 문제
대부분의 LLM 기반 OCR은 클라우드 API를 통해서만 접근 가능하여 민감한 문서 처리 시 프라이버시 문제가 발생할 수 있습니다. Chandra는 로컬 실행 옵션을 제공하여 이 문제를 해결합니다.
상업적 사용 라이선스
Chandra의 코드는 Apache 2.0 라이선스를 사용하며, 모델 가중치는 수정된 OpenRAIL-M 라이선스를 사용합니다. 이 라이선스는 연구, 개인 사용, 그리고 자금/수익이 $2M 미만인 스타트업에게 무료이지만, Chandra API와 경쟁적으로 사용할 수는 없습니다. OpenRAIL 라이선스 요구 사항을 제거하거나 더 넓은 상업적 라이선스를 원하시면 공식 가격 페이지를 방문하세요.
커뮤니티 및 지원
Chandra의 미래 개발에 대한 논의는 Discord에서 이루어집니다. 개발자 커뮤니티에 참여하여 최신 업데이트와 기능에 대한 정보를 얻을 수 있습니다.
결론
Chandra는 기존 LLM 기반 OCR 솔루션의 한계를 뛰어넘는 고정밀 OCR 모델입니다. 복잡한 레이아웃, 표, 수학 공식, 필기체 등 다양한 문서 형식을 정확하게 처리하면서도 원본 레이아웃을 보존하는 능력은 문서 디지털화 작업에 혁신을 가져옵니다.
벤치마크 결과에서 볼 수 있듯이, Chandra는 GPT-4o, Gemini Flash 2, Qwen 3 VL 등 유명한 LLM 기반 OCR 솔루션보다 훨씬 높은 성능을 보여주고 있습니다. 특히 수학 문서(88.0%), 다열 레이아웃(81.2%), 작은 텍스트(92.3%) 등 특수한 문서 형식에서 두각을 나타냅니다.
로컬 실행 옵션을 제공하여 데이터 프라이버시 문제를 해결하고, CLI 도구와 Streamlit 앱을 통해 사용자 친화적인 인터페이스를 제공하는 점도 Chandra의 큰 장점입니다.
문서 디지털화와 정보 추출이 중요한 기업, 연구 기관, 교육 기관 등 다양한 분야에서 Chandra는 강력한 OCR 솔루션으로 자리매김할 것으로 기대됩니다.
참고 URL :
Datalab : https://www.datalab.to/
답글 남기기