




웹사이트 콘텐츠를 LLM(Large Language Model)에 최적화된 마크다운으로 변환하고 싶으신가요? 또는 AI 검색 가능성을 높이기 위해 사이트를 최적화하고 싶으신가요? Mdream은 이러한 요구를 충족시키는 강력한 도구입니다. 이 글에서는 Mdream의 주요 기능과 활용 방법에 대해 자세히 알아보겠습니다.
크롤러를 직접 개발하신 분들이라면, 고려해야 할것들이 매우 많은 영역의 장르라는 것은 잘 아실듯 합니다. 특히 다양한 유형의 웹페이지들을 불필요한 부분을 배제한 알맹이(?) , LLM이 인식하기 좋은 데이터 영역만 예쁘게 식별해서 가져온 다는 것은 매우 고려되어야 할것이 많은 영역입니다.
Mdream은 이러한 고민을 cli명령 한줄로 해결할수 있을 만큼 심플한 사용 명령으로 매우 강력한 크롤링을 하는 도구이기에 포스트로 다뤄 봅니다.

Mdream이란 무엇인가?
Mdream은 웹사이트 콘텐츠를 LLM에 최적화된 마크다운으로 변환하는 도구입니다. 기존의 HTML-to-Markdown 변환기들은 LLM이나 사람을 위해 설계되지 않았습니다. 이들은 대체로 느리고 무거우며, LLM의 토큰 사용이나 가독성 측면에서 최적화되지 않은 결과물을 생성합니다.
반면 Mdream은 HTML을 LLM에 최적화된 마크다운으로 변환하는 고도로 최적화된 도구로, 다음과 같은 특징을 가지고 있습니다:
- LLM을 위해 특별히 설계된 HTML-to-Markdown 변환기 (약 50% 더 적은 토큰 사용)
- 최소한의 GitHub Flavored Markdown 생성: Frontmatter, 중첩 및 HTML 마크업 지원
- 초고속 처리: 1.4MB의 HTML을 약 50ms 만에 마크다운으로 스트리밍
- 경량화: gzip 압축 시 5kB, 제로 의존성 코어
- 어디서나 실행 가능: CLI 크롤러, Docker, GitHub Actions, Vite 등 다양한 환경 지원
- 확장 가능: 기능 커스터마이징 및 확장을 위한 플러그인 시스템
Mdream 패키지 구성
Mdream은 다양한 프로젝트와 사용 사례에 맞게 여러 패키지로 제공됩니다:
- mdream: 기본 HTML-to-Markdown 변환기, CLI 및 패키지 API 제공 (의존성 없음)
- @mdream/crawl: 전체 웹사이트를 크롤링하여 LLM 아티팩트 생성
- Docker: 컨테이너화된 웹사이트 크롤링을 위한 Playwright Chrome이 사전 설치된 Docker 이미지
- @mdream/vite: Vite 사이트에 자동 .md 생성 기능 추가
- @mdream/nuxt: Nuxt 사이트에 자동 .md 및 llms.txt 아티팩트 생성 기능 추가
- @mdream/action: 정적 .html 출력에서 .md 및 llms.txt 아티팩트 생성
Mdream Crawl: 웹사이트 전체 크롤링
@mdream/crawl 패키지는 전체 사이트를 크롤링하여 Mdream을 사용해 마크다운으로 변환된 LLM 아티팩트를 생성합니다. 주요 출력물은 다음과 같습니다:
- llms.txt: LLM 소비에 최적화된 통합 텍스트 파일
- llms-full.txt: 포괄적인 메타데이터와 전체 콘텐츠가 포함된 확장 형식
- 개별 마크다운 파일: 크롤링된 각 페이지가 md/ 디렉토리에 별도의 마크다운 파일로 저장
기본 사용법
Mdream Crawl은 다양한 방식으로 사용할 수 있습니다:
# 대화형 모드 npx @mdream/crawl # 간단한 사용법 npx @mdream/crawl https://harlanzw.com # Glob 패턴 사용 npx @mdream/crawl "https://nuxt.com/docs/getting-started/**" # 도움말 보기 npx @mdream/crawl -h
Claude Code와 함께 사용하기
Mdream은 Claude Code와 원활하게 연동되어 웹사이트를 분석하고 이해하는 데 도움을 줍니다:
# 웹사이트 크롤링 후 Claude로 분석
npx @mdream/crawl harlanzw.com
cat output/llms-full.txt | claude -p "give me a one sentence summary of this website
# 특정 문서 섹션 분석
npx @mdream/crawl "https://nuxt.com/docs/getting-started/**"
cat output/llms-full.txt | claude -p "explain the key concepts in this documentation"
# 사이트에서 특정 정보 추출
npx @mdream/crawl example.com/blog
cat output/llms.txt | claude -p "list all the blog post titles and their main topics"
Playwright를 사용한 크롤링
JavaScript가 많이 사용된 동적 웹사이트의 경우 Playwright를 사용하여 크롤링할 수 있습니다:
npx -p playwright -p @mdream/crawl crawl -u example.com --driver playwright
pnpm --package=playwright --package=@mdream/crawl dlx crawl example.com --driver playwright
특정 경로 제외하기
크롤링 시 특정 경로를 제외할 수 있습니다:
npx @mdream/crawl -u example.com --exclude "/admin/*" --exclude "/api/*"
대규모 사이트 크롤링 제한 설정
대규모 사이트를 크롤링할 때는 페이지 수와 깊이를 제한할 수 있습니다:
npx @mdream/crawl -u https://large-site.com \
--max-pages 100 \
--depth 2
Mdream CLI: 유닉스 파이프와 함께 사용하기
Mdream의 기본 CLI는 Mdream Crawl보다 더 미니멀하게 설계되었으며, 유닉스 파이프와 함께 사용하여 다른 도구들과 유연하게 통합할 수 있습니다.
사이트를 마크다운으로 파이프하기
다음 예시는 위키피디아의 Markdown 페이지를 가져와 원본 링크와 이미지를 보존하면서 마크다운으로 변환합니다:
curl -s https://en.wikipedia.org/wiki/Markdown \
| npx mdream --origin https://en.wikipedia.org --preset minimal \
| tee streaming.md
팁: --origin 플래그는 상대적인 이미지 및 링크 경로를 수정합니다.
로컬 파일을 마크다운으로 변환하기
로컬 HTML 파일을 마크다운 파일로 변환하고, tee를 사용하여 출력을 파일에 쓰면서 터미널에 표시할 수 있습니다:
cat index.html \
| npx mdream --preset minimal \
| tee streaming.md
CLI 옵션
--origin <url>: 상대 링크 및 이미지 해결을 위한 기본 URL--preset <preset>: 변환 프리셋 (예: minimal)--help: 도움말 정보 표시--version: 버전 정보 표시
Docker 통합
Mdream은 Playwright Chrome이 사전 설치된 Docker 이미지를 제공하여 컨테이너화된 환경에서 웹사이트 크롤링을 수행할 수 있습니다.
# 빠른 시작
docker run harlanzw/mdream:latest site.com/docs/**
# 대화형 모드
docker run -it harlanzw/mdream:latest
# JavaScript 사이트에 Playwright 사용
docker run harlanzw/mdream:latest spa-site.com --driver playwright
사용 가능한 이미지:
harlanzw/mdream:latest– 최신 안정 릴리스ghcr.io/harlan-zw/mdream:latest– GitHub Container Registry
GitHub Actions 통합
Mdream은 CI/CD 워크플로우에서 glob 패턴을 사용하여 HTML 파일을 처리하고 llms.txt 아티팩트를 생성하는 GitHub Action을 제공합니다. 이는 사전 렌더링된 사이트에 유용하며, 변경할 때마다 LLM 준비된 파일을 아티팩트로 업로드하거나 사이트와 함께 배포할 수 있습니다.
전체 워크플로우 예시
name: Generate LLMs.txt
on:
push:
branches: [main]
pull_request:
branches: [main]
jobs:
generate-llms-txt:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: '20'
- name: Install dependencies
run: npm ci
- name: Build documentation
run: npm run build
- name: Generate llms.txt artifacts
uses: harlan-zw/mdream@main
with:
glob: 'dist/**/*.html'
site-name: My Documentation
description: Comprehensive technical documentation and guides
origin: 'https://mydocs.com'
output: dist
- name: Upload llms.txt artifacts
uses: actions/upload-artifact@v4
with:
name: llms-txt-artifacts
path: |
dist/llms.txt
dist/llms-full.txt
dist/md/
- name: Deploy to GitHub Pages (optional)
if: github.ref == 'refs/heads/main'
uses: peaceiris/actions-gh-pages@v3
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: ./distVite 통합
Mdream은 온디맨드 HTML-to-Markdown 변환을 가능하게 하는 Vite 플러그인을 제공합니다.
- 자동 마크다운: .md 확장자로 모든 경로에 접근 가능 (예: /about.html → /about.md)
- 빌드 타임 생성: HTML 파일과 함께 정적 마크다운 파일 자동 생성
설치
pnpm install @mdream/vite
사용법
import MdreamVite from '@mdream/vite'
// vite.config.ts
import { defineConfig } from 'vite'
export default defineConfig({
plugins: [
MdreamVite()
]
})Nuxt 통합
Mdream Nuxt 모듈의 주요 기능:
- 온디맨드 생성: .md 확장자로 모든 경로에 접근 가능 (예: /about → /about.md)
- LLMs.txt 생성: 사전 렌더링 중 llms.txt 및 llms-full.txt 아티팩트 생성
설치
pnpm add @mdream/nuxt
사용법
nuxt.config.ts에 모듈을 추가하세요:
export default defineNuxtConfig({
modules: [
'@mdream/nuxt'
],
})이제 URL 경로에 .md를 추가하여 마크다운에 접근할 수 있습니다. nuxi generate로 사이트를 정적으로 생성할 때 llms.txt 아티팩트가 생성됩니다.
API 사용법
설치
pnpm add mdream
기본 사용법
Mdream은 HTML 작업을 위한 두 가지 주요 함수를 제공합니다:
htmlToMarkdown: 이미 변환하려는 전체 HTML 페이로드가 있는 경우 유용streamHtmlToMarkdown: 원격에서 가져오거나 로컬 파일에서 읽는 경우 권장
기존 HTML 변환하기
import { htmlToMarkdown } from 'mdream'
// 간단한 변환
const markdown = htmlToMarkdown('<div><h1>Hello World</h1></div>');
console.log(markdown) // # Hello World
Fetch로 변환하기
import { streamHtmlToMarkdown } from 'mdream'
// 스트리밍과 함께 fetch 사용
const response = await fetch('https://example.com')
const htmlStream = response.body
const markdownGenerator = streamHtmlToMarkdown(htmlStream, {
origin: 'https://example.com'
})
// 도착하는 대로 청크 처리
for await (const chunk of markdownGenerator) {
console.log(chunk)
}순수 HTML 파서
마크다운으로 변환하지 않고 HTML을 DOM과 유사한 AST로 파싱하기만 하려면 parseHtml을 사용하세요:
import { parseHtml } from 'mdream'
const html = '<div><h1>Title</h1><p>Content</p></div>';
const { events, remainingHtml } = parseHtml(html)
// 파싱된 이벤트 처리
events.forEach((event) => {
if (event.type === 'enter' && event.node.type === 'element') {
console.log('Entering element:', event.node.tagName)
}
})parseHtml 함수는 다음을 제공합니다:
- 순수 AST 파싱 – 마크다운 생성 오버헤드 없음
- DOM 이벤트 – 각 요소 및 텍스트 노드에 대한 입/출 이벤트
- 플러그인 지원 – 파싱 중 플러그인 적용 가능
- 스트리밍 호환 – 동일한 플러그인 시스템으로 작동
프리셋
프리셋은 일반적인 사용 사례를 위한 플러그인의 사전 구성된 조합입니다.
미니멀 프리셋
미니멀 프리셋은 비필수적인 콘텐츠를 제거하여 토큰 감소와 더 깔끔한 출력을 최적화합니다:
import { withMinimalPreset } from 'mdream/preset/minimal'
const options = withMinimalPreset({
origin: 'https://example.com'
})포함된 플러그인:
isolateMainPlugin()– 주요 콘텐츠 영역 추출frontmatterPlugin()– 메타 태그에서 YAML 프론트매터 생성tailwindPlugin()– Tailwind 클래스를 마크다운으로 변환filterPlugin()– 폼, 내비게이션, 버튼, 푸터 등 비콘텐츠 요소 제외
CLI 사용법:
curl -s https://example.com | npx mdream --preset minimal --origin https://example.com
플러그인 시스템
플러그인 시스템을 사용하면 처리 파이프라인에 연결하여 HTML-to-Markdown 변환을 커스터마이징할 수 있습니다. 플러그인은 콘텐츠를 필터링하거나, 데이터를 추출하거나, 노드를 변환하거나, 사용자 정의 동작을 추가할 수 있습니다.
내장 플러그인
Mdream에는 개별적으로 또는 조합하여 사용할 수 있는 여러 내장 플러그인이 포함되어 있습니다:
extractionPlugin: CSS 선택자를 사용하여 데이터 분석을 위한 특정 요소 추출filterPlugin: CSS 선택자 또는 태그 ID를 기반으로 요소 포함 또는 제외frontmatterPlugin: HTML 헤드 요소(제목, 메타 태그)에서 YAML 프론트매터 생성isolateMainPlugin: <main> 요소 또는 헤더-푸터 경계를 사용하여 주요 콘텐츠 분리tailwindPlugin: Tailwind CSS 클래스를 마크다운 서식(굵게, 기울임꼴 등)으로 변환readabilityPlugin: 콘텐츠 점수 매기기 및 추출 (실험적)
import { filterPlugin, frontmatterPlugin, isolateMainPlugin } from 'mdream/plugins'
const markdown = htmlToMarkdown(html, {
plugins: [
isolateMainPlugin(),
frontmatterPlugin(),
filterPlugin({ exclude: ['nav', '.sidebar', '#footer'] })
]
})플러그인 훅
beforeNodeProcess: 노드 처리 전에 호출, 노드 건너뛰기 가능onNodeEnter: 요소 노드 진입 시 호출onNodeExit: 요소 노드 종료 시 호출processTextNode: 각 텍스트 노드에 대해 호출processAttributes: 요소 속성 처리를 위해 호출
플러그인 만들기
타입 안전성을 위해 createPlugin()을 사용하여 플러그인을 만들 수 있습니다:
import type { ElementNode, TextNode } from 'mdream'
import { htmlToMarkdown } from 'mdream'
import { createPlugin } from 'mdream/plugins'
const myPlugin = createPlugin({
onNodeEnter(node: ElementNode) {
if (node.name === 'h1') {
return '🔥 '
}
},
processTextNode(textNode: TextNode) {
// 텍스트 콘텐츠 변환
if (textNode.parent?.attributes?.id === 'highlight') {
return {
content: `**${textNode.value}**`,
skip: false
}
}
}
})
// 플러그인 사용
const html: string = '<div id="highlight">Important text</div>'
const markdown: string = htmlToMarkdown(html, { plugins: [myPlugin] })
예시: 콘텐츠 필터 플러그인
import type { ElementNode, NodeEvent } from 'mdream'
import { ELEMENT_NODE } from 'mdream'
import { createPlugin } from 'mdream/plugins'
const adBlockPlugin = createPlugin({
beforeNodeProcess(event: NodeEvent) {
const { node } = event;
if (node.type === ELEMENT_NODE && node.name === 'div') {
const element = node as ElementNode
// 광고 및 프로모션 콘텐츠 건너뛰기
if (element.attributes?.class?.includes('ad')
|| element.attributes?.id?.includes('promo')) {
return { skip: true }
}
}
}
})추출 플러그인
HTML 처리 중 데이터 분석이나 콘텐츠 발견을 위해 특정 요소와 그 콘텐츠를 추출합니다:
import { extractionPlugin, htmlToMarkdown } from 'mdream'
const html: string = `
<article>
<h2>Getting Started</h2>
<p>This is a tutorial about web scraping.</p>
<figure><img src="/hero.jpg" alt="Hero image"></figure><p> <br>
</p></article>
`
// CSS 선택자를 사용하여 요소 추출
const plugin = extractionPlugin({
'h2': (element: ExtractedElement, state: MdreamRuntimeState) => {
console.log('Heading:', element.textContent) // "Getting Started"
console.log('Depth:', state.depth) // 현재 중첩 깊이
},
'img[alt]': (element: ExtractedElement, state: MdreamRuntimeState) => {
console.log('Image:', element.attributes.src, element.attributes.alt)
// "Image: /hero.jpg Hero image"
console.log('Context:', state.options) // 변환 옵션에 접근
}
})
htmlToMarkdown(html, { plugins: [plugin] })추출 플러그인은 전체 텍스트 콘텐츠와 속성을 가진 메모리 효율적인 요소 추출을 제공하며, SEO 분석, 콘텐츠 발견 및 데이터 마이닝에 적합합니다.
Mdream의 실제 활용 사례
Mdream은 다양한 상황에서 유용하게 활용될 수 있습니다. 몇 가지 실제 사례를 살펴보겠습니다:
1. 기술 문서 사이트의 LLM 최적화
대규모 기술 문서 사이트를 운영하는 경우, Mdream을 사용하여 전체 사이트를 크롤링하고 LLM 친화적인 마크다운으로 변환할 수 있습니다. 이렇게 하면 AI 챗봇이나 검색 시스템이 문서 내용을 더 효율적으로 처리할 수 있습니다.
2. 블로그 콘텐츠 분석
마케팅 팀은 Mdream을 사용하여 경쟁사 블로그를 크롤링하고 콘텐츠를 분석할 수 있습니다. 추출 플러그인을 사용하면 주제, 키워드, 콘텐츠 구조 등을 쉽게 파악할 수 있습니다.
3. 레거시 웹사이트 마이그레이션
HTML로 작성된 레거시 웹사이트를 마크다운 기반 시스템(예: Next.js, Nuxt, Gatsby 등)으로 마이그레이션할 때 Mdream을 사용하면 콘텐츠 변환 과정을 자동화할 수 있습니다.
4. AI 학습 데이터 준비
AI 모델 학습을 위한 웹 콘텐츠 데이터셋을 준비할 때 Mdream을 사용하면 HTML 노이즈를 제거하고 고품질 마크다운 형식으로 데이터를 정제할 수 있습니다.
5. 지속적인 문서 업데이트
GitHub Actions와 Mdream을 통합하면 문서가 업데이트될 때마다 자동으로 LLM용 아티팩트를 생성하고, 이를 통해 항상 최신 상태의 AI 친화적 문서를 유지할 수 있습니다.
Mdream과 다른 도구 비교
Mdream은 기존의 HTML-to-Markdown 변환 도구와 어떻게 다를까?
1. AI 친화적 수집
기존의 HTML-to-Markdown 변환기들은 인간이 읽기 위한 용도로 설계되었습니다. 반면 mdream은 LLM이 효율적으로 처리할 수 있도록 설계되었습니다:
# 기존 방식: 복잡하고 토큰 낭비가 심한 마크다운
<nav class="navbar">...</nav>
<div class="sidebar">...</div>
# 불필요한 네비게이션과 사이드바까지 모두 변환
# mdream 방식: 핵심 콘텐츠만 추출한 깔끔한 마크다운
---
title: "페이지 제목"
description: "페이지 설명"
---
# 메인 콘텐츠만 추출된 깔끔한 마크다운2. 혁신적인 성능
전통적인 크롤러들이 무겁고 느린 반면, mdream은 스트리밍 기반으로 동작해 압도적인 성능을 보여줍니다:
- 기존 크롤러: 전체 HTML 로드 → 파싱 → 변환 (수백 ms~수초)
- mdream: 스트리밍으로 실시간 변환 (~50ms)
3. llmx.txt 표준 지원
mdream은 llms.txt 표준을 지원합니다. 이는 AI 모델이 웹사이트를 더 잘 이해할 수 있도록 만들어진 새로운 표준입니다.
# 생성되는 파일들
- llms.txt: LLM 최적화된 압축 버전
- llms-full.txt: 메타데이터 포함 전체 버전
- md/: 개별 페이지별 마크다운 파일들
실행 결과
약 1800여 웹페이지로 구성된 웹사이트를 한줄의 cli 명령어로 수행됩니다.
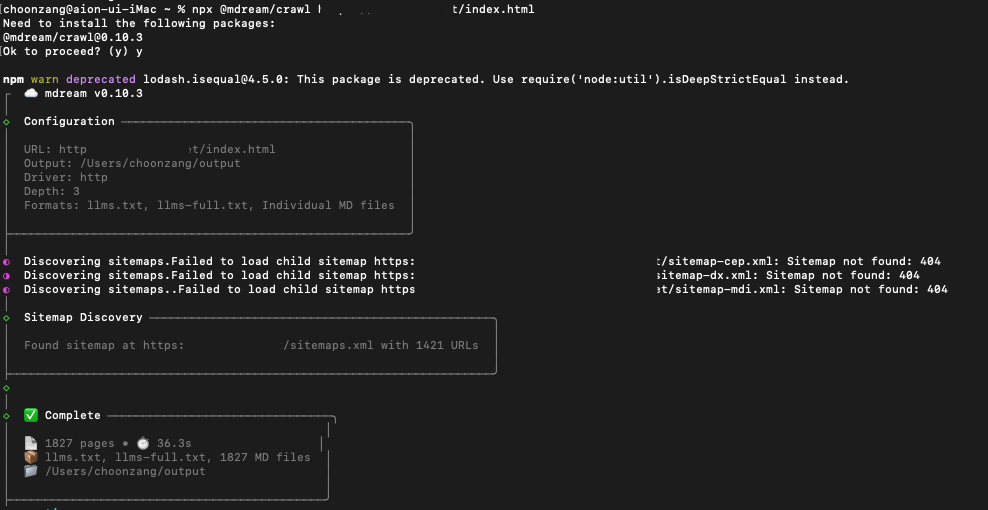
1827 pages, 36.3s
일반적인 헤드리스 브라우저 방식의 스크랩하고는 비교도 안되는 성능 차이입니다.
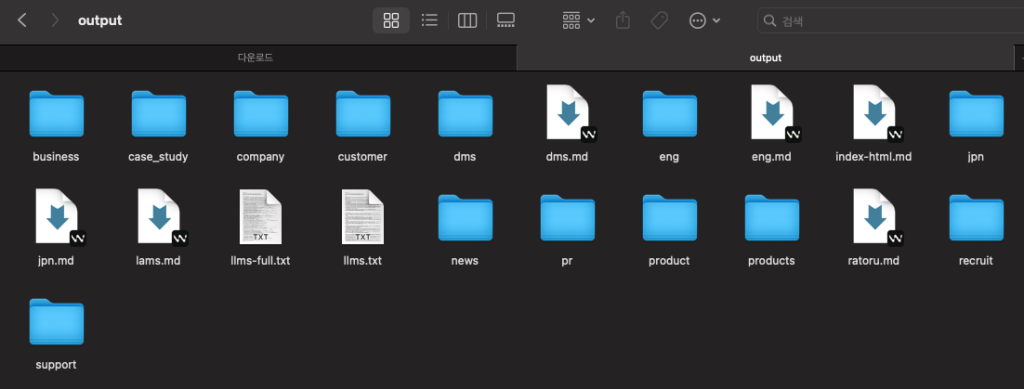
llms.txt 파일 및 markdown 파일들이 수집되어있습니다. 공통 nav및 footer영역은 제외된 본문 구성만 포함되어있습니다.
마무리
최근 RAG 시스템에 튜토리얼을 밀어넣고, RAG시스템으로 불러서 필요한 정보를 얻으면 좋겠다고 생각했습니다. 그래서 헤드리스 브라우저 기반으로 크롤러를 간단하게 만들어봤었는데, 생각보다 복잡하고 고려할것들이 많았습니다. 이러한 고민들이 한줄 의 명령어 안에서 해결되는 것을 보고는 매우 충격을 받았습니다. 또한 RAG 시스템을 위한 매우 효율적인 구조로 파일이 생성되므로, 어떻게 잘 담을지만 고민하면 될 정보로 많은 것들을 한번에 처리는 하는 도구 였습니다.
다양한 서비스 또는 어플리케이션으로 연결하여 사용될수 있어 앞으로도 주의깊게 볼 만한 결과물이라 생각됩니다.
답글 남기기