




인공지능 시대에 문서 검색과 정보 추출은 비즈니스의 핵심 요소가 되었습니다. 그동안 RAG(Retrieval-Augmented Generation) 시스템은 벡터 데이터베이스를 기반으로 한 유사도 검색에 의존해왔지만, 유사도가 곧 관련성을 의미하지는 않는다는 근본적인 한계가 있었습니다.
여기 이러한 문제를 다른 식으로 해석하여 풀어낸 케이스가 있어 소개합니다. PageIndex는 전통적인 벡터 기반 RAG와는 완전히 다른 접근법을 제시합니다. AlphaGo에서 영감을 받은 이 혁신적인 서비스는 인간 전문가가 문서를 탐색하는 방식을 시뮬레이션하여 추론 기반의 트리 검색을 수행합니다.
기존 RAG의 한계와 PageIndex의 혁신
기존 RAG 시스템의 문제점
1. 유사도 ≠ 관련성
- 벡터 기반 RAG는 의미론적 유사도에 의존하지만, 유사한 언어를 사용하면서도 중요한 세부사항이 다른 전문 분야 문서에서는 정확한 정보를 검색하는 데 실패하는 경우가 많습니다.
2. 인위적인 청킹(Chunking)
- 문서를 임의의 크기로 분할하는 과정에서 자연스러운 문서 구조가 파괴되고, 문맥 정보가 손실됩니다.
3. Top-K 선택의 한계
- 수동적인 매개변수 튜닝과 임의적인 컷오프로 인해 관련성 높은 정보를 놓치거나 불필요한 정보를 포함할 수 있습니다.
PageIndex의 혁신적 접근법
1. 벡터 없는(Vectorless) RAG
- 벡터 데이터베이스의 복잡성과 오버헤드를 제거하고, 가벼운 JSON 객체로 트리 구조를 표현합니다.
- 추론 기반 검색으로 진정한 관련성을 찾아냅니다.
2. 계층적 트리 구조
- 문서의 원본 논리적 흐름과 조직 구조를 보존하는 “목차” 형태의 트리를 생성합니다.
- 자연스러운 문서 구조를 유지하여 더 나은 문맥 정보를 보존합니다.
[
{
"title": "(v)IXXX IXXX 제품 소개서",
"node_id": "0000",
"summary": "This partial document is an introduction and overview of the IXXX product. It includes a table of contents outlining the main sections: CMS overview, introduction to IXXX, IXXX architecture, main features, comparison with other services, customer companies, and representative case studies. The initial sections explain the importance of website solutions, highlighting how traditional website development required multiple roles, whereas IXXX enables efficient website building and management with fewer people. IXXX manages the entire content lifecycle (creation, distribution, modification, deletion) efficiently and supports rapid integration with APIs, SEO, and SNS. The document also notes that since 1999, over 1,000 companies have adopted IXXX, and it has evolved through seven major upgrades to meet diverse industry needs with enhanced features and stability.",
"start_index": 1,
"end_index": 7,
"text": "# (v)IXXX 제품 소개서\n\n## Contents\n\n목차\n\n1 CMS 개요 ..... P. 03\n2 IXXX 소개 ..... P. 05\n3 IXXX Architecture ..... P. 14\n4 IXXX 주요기능 ..... P. 16\n5 타사 서비스와 비교 ..... P. 57\n6 고객사 ..... P. 59\n7 대표 구축 사례 ..... P. 61\n\n## 01. CMS 개요\n\n웹사이트 솔루션 어느 때보다 중요합니다.\n\n기존 웹사이트 구축/운영 방식은 '기획자, 웹디자이너, 퍼블리셔, 개발자' 등 여러 포지션의 다수인력이 투입되어야 했습니다.\n\nIXXX는 소수 인원으로 웹사이트 구축/운영이 가능합니다.\n\n솔루션 내에서 콘텐츠 생산, 배포, 수정, 소멸에 이르는 일련의 라이프 사이클을 효율적으로 관리합니다.\n\nAPI, SEO, SNS 연동 또한 기존방식보다 빠르게 적용합니다.\n\n\n\n기존 방식 웹사이트 구축/운영\n\n\n\nCMS를 통한 구축/운영\n\n## 02. IXXX 소개\n\n## 02 IXXX 소개\n\n\n\n1999년 이후로 1000여 개가 넘는 기업들이 IXXX를 도입해왔고, 지금까지도 활발하게 사용되어지고 있습니다. 지난 20여 년 간, 각 산업계의 다양한 요구를 수렴하여 메이저 업그레이드 7 번을 통해서 더욱 강력해진 기능과 안정성으로 기업의 니즈를 충족해오고 있습니다.\n"
},
{
"title": "공공기관 인증받은 신뢰성 높은 CMS솔루션",
"node_id": "0001",
"summary": "This partial document highlights the credibility and achievements of the IXXX solution developed by XXX. It emphasizes that IXXX is the first WCMS/CMS solution developed in Korea, having received ISO9001 certification in 2001 and a patent for template-based page creation/management in 2004. The document also notes that IXXX has obtained 'e-Government Standard Framework Compatibility Certification' from the National Information Society Agency and 'Good Software (GS)' certification from the Telecommunications Technology Association. Internationally, IXXX was listed in Gartner's Web Content Management vendor list in 2014. The section is supported by relevant images.",
"start_index": 7,
"end_index": 8,
"text": "# 공공기관 인증받은 신뢰성 높은 CMS솔루션\n\nIXXX는 국내 최초로 개발된 WCMS/CMS솔루션입니다.\n\n2001년 국내 CMS부문 최초 ISO9001인증과 2004년에는 CMS원천 기술인 템플릿 기반의 페이지 생성/관리의 특허권을 취득했습니다.\n\n그 이후, **한국정보화진흥원에서 '전자정부 표준프레임워크 호환성 인증'**을 획득하고, **한국정보통신기술협회**로부터 **'굿소프트웨어(GS - Good Software)'**를 인증 받았습니다.\n\n국외에서는 2014년 **'가트너(Gartner) WCM(Web Content Management) 벤더리스트'**에 등재되었습니다.\n\n\n\n\n"
},
{
"title": "콘텐츠 생산에서 소멸까지 일련의 라이프 사이클 관리",
"node_id": "0002",
"summary": "This partial document describes the IXXX system, emphasizing its role in managing the entire content lifecycle from creation to disposal within enterprise-level e-Business environments. It highlights how IXXX automates and streamlines repetitive, manual, and distributed tasks, improving efficiency and reducing costs. The document outlines the benefits of implementing IXXX, such as establishing systematic workflows for content planning, production, distribution, sharing, and modification, thereby saving manpower, time, and expenses.IXXX is structured around four managers (Content, Site, Operation, Admin), allowing for clear role separation and authority assignment, enabling small teams to efficiently build and operate websites and produce content. The system supports responsive web design, web standards, and accessibility. Practical applications include official site creation for enterprises and public institutions, easy and rapid editing of web pages without developer assistance, intuitive landing page creation using WYSIWYG editors, and scalable multi-site management (e.g., by brand, region, language) with independent operation and delegated authority for each site or menu.",
"start_index": 8,
"end_index": 14,
"text": "# 콘텐츠 생산에서 소멸까지 일련의 라이프 사이클 관리\n\nIXXX는 엔터프라이즈급 e-Business 기업에서 부가가치를 기대할 수 있는 모든 정보의 기본 단위인 콘텐츠를 체계적이고 일관성 있는 단일한 시스템에서 관리하여 효율성과 생산성을 부여하는 시스템입니다.\n\n콘텐츠 생산에서 소멸에 이르는 일련의 라이프 사이클에서 발생하는 반복적, 수동적, 분산적 작업을 자동화, 고속화, 고효율화하여 보다 효율적인 비용으로 체계적인 콘텐츠 관리를 할 수 있도록 지원해 주는 웹 서비스의 필수 기반 솔루션입니다.\n\n\n\n## IXXX도입으로 체계적인 워크플로우 생성\n\n웹사이트에 올라오는 콘텐츠들은 기획, 제작, 배포, 공유, 수정 등 여러 담당자의 작업이 필요합니다. IXXX는 이러한 복잡한 과정을 쉽고 간편한 워크플로우를 구성하여 인력, 시간, 비용을 절약합니다.\n\n\n\n### 4개의 매니저로 콘텐츠 제작에서 서비스 운영까지\n\nIXXX는 다양한 디바이스 환경에 적응하는 반응형 웹(Responsive Web)을 지원하며, 다양한 브라우저에 동일하게 적용되는 웹표준화와 누구나 웹을 사용할 수 있는 웹접근성을 준수합니다.\n\n**콘텐츠 매니저, 사이트 매니저, 운영 매니저, 어드민 매니저**\n\n4개의 매니저로 구성되어 있어 담당자를 구분하고 각 업무에 맞는 권한을 부여합니다. 기존 대비 소규모 인원으로 웹사이트 구축/운영과 콘텐츠 생산이 가능합니다.\n\n또한, IXXX는 서비스 운영에 있어 마케터들이 전략 수립, 실행 등 다양한 활동을 지원합니다.\n\n\n\n*IXXX로 구축된 삼성카드 PC홈페이지, 모바일웹(앱)입니다.\n\n오피셜 사이트 제작\n\n기업용 홈페이지, 금융, 공공기관 등 공식 홈페이지 제작/운영이 가능합니다.\n\n콘텐츠 관리를 체계적이고, 안정적으로 운영이 가능해졌습니다.\n\n개발자 도움 없이 적은 자원으로 상당히 많은 범위의 화면을 빠르고 손쉽게 수정/관리합니다.\n\n\n\n랜딩 페이지 제작\n\n한 장의 페이지로 구성된 랜딩 페이지 구축 시, WYSIWYG Editor방식을 사용하여 사용자가 최종 콘텐츠를 직관적으로 볼 수 있어 빠른 수정 및 배포가 가능합니다.\n\n\n\n다량의 사이트 제작 \n\n브랜드 별 사이트, 지역별 사이트, 학교 학과 사이트, 프로젝트 별 사이트, 다국어 사이트 등 다량의 사이트 구축에 있어서 기존의 작업물을 재활용하여 새로운 사이트를 생성하는 방식이 가능합니다.\n\n더불어 사이트 단위나 메뉴 단위로 지정된 담당자가 권한을 가지고 운영할 수 있으므로, 통합된 IXXX 에서 독립적인 운영을 보장할 수 있습니다.\n\n"
},
{
"title": "03.IXXX Architecture",
"node_id": "0003",
"summary": "# 03. IXXX Architecture\n\n## IXXX Architecture\n\nIXXXWeb Admin, IXXX File System, Index File System, Database, Deploy Client, Dynamic 등 각 요소들이 분산 서비스 플랫폼 기반으로 이용 패턴에 따라 다양한 하드웨어의 구성하여 서비스에 최적화되도록 유연한 환경구성을 갖추었습니다.\n\n별도의 설치 없이 100% 웹브라우저만으로 사용 가능하며, 모든 UI 구현이 웹표준을 기반으로 구성되어 다양한 브라우저와 OS를 지원합니다.\n\n\n",
"start_index": 14,
"end_index": 16,
"text": "# 03. IXXX Architecture\n\n## IXXX Architecture\n\nIXXX Web Admin, IXXX File System, Index File System, Database, Deploy Client, Dynamic 등 각 요소들이 분산 서비스 플랫폼 기반으로 이용 패턴에 따라 다양한 하드웨어의 구성하여 서비스에 최적화되도록 유연한 환경구성을 갖추었습니다.\n\n별도의 설치 없이 100% 웹브라우저만으로 사용 가능하며, 모든 UI 구현이 웹표준을 기반으로 구성되어 다양한 브라우저와 OS를 지원합니다.\n\n\n"
},
{
"title": "04.",
"node_id": "0004",
"summary": "# 04.\n",
"start_index": 16,
"end_index": 16,
"text": "# 04.\n"
},
...
}
]
}
]
}
]
}
]
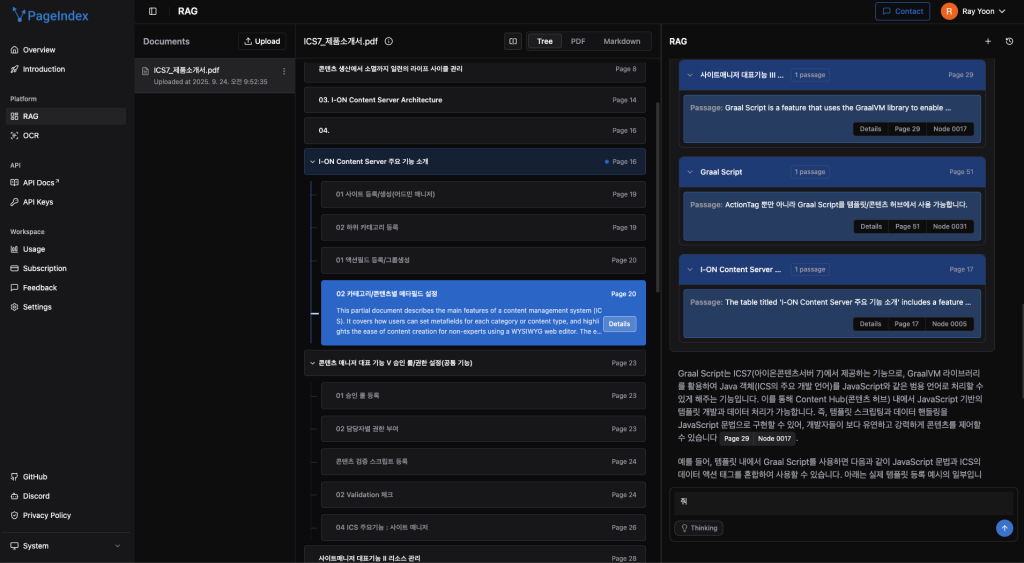
문서를 기준으로 추출된 JSON 파일로 파일 내에 정보를 유사성에 기반한 트리 구조의 인덱스를 생성해 냅니다.
3. 인간과 같은 문서 탐색
- 전문가가 문서를 읽고 탐색하는 방식을 시뮬레이션하여 더 정확한 정보 검색을 수행합니다.
PageIndex의 핵심 구성 요소
PageIndex는 세 가지 주요 컴포넌트로 구성되어 있습니다:
PageIndex OCR
기존 OCR 시스템이 각 페이지를 독립적으로 처리하는 것과 달리, PageIndex OCR은 대형 비전-언어 모델의 컨텍스트 창을 활용하여 전체 문서를 하나의 일관된 구조체로 처리합니다.
주요 특징:
- 정확한 페이지별 마크다운 콘텐츠: 각 페이지를 LLM이 사용할 수 있는 마크다운 텍스트로 변환
- 다중 페이지 구조 보존: 페이지 경계를 넘나드는 계층적 구조를 보존
- 빠른 처리 속도: 긴 문서를 효율적으로 처리하며 속도 저하 없이 확장 가능
PageIndex 트리 생성
문서의 원본 논리적 흐름과 조직 구조를 유지하는 계층적 “목차” 트리를 생성합니다. 이 LLM 최적화된 구조는 정확한 탐색을 가능하게 하고 추론 기반 RAG에 최적화되어 있습니다.
핵심 장점:
- 벡터 DB 불필요: JSON 객체로 가벼운 표현
- 청킹 불필요: 자연스러운 문서 구조 보존
- 정확한 페이지 참조: 각 노드에 정확한 페이지 인덱스 포함
- 긴 문서 최적화: 재무 보고서, 법률 문서, 기술 매뉴얼 등 LLM 컨텍스트 한계를 초과하는 문서에 최적화
PageIndex 검색
문서가 계층적 트리 구조로 변환되면, PageIndex 검색 모듈이 이러한 트리에서 관련 컨텍스트를 추출합니다. LLM 기반 트리 검색과 값 기반 트리 검색을 모두 활용하여 효율적이고 정확한 검색을 수행합니다.
검색 프로세스의 특징:
- Top-K 선택 불필요: 트리 검색이 자동으로 모든 관련 노드를 식별
- 투명한 노드 경로: 트리 구조를 통한 완전한 검색 경로 제공
- 정확한 페이지 참조: 검색된 모든 노드에 원본 문서의 정확한 페이지 번호와 위치 포함
- LLM 준비 완료 출력: 관련 단락과 검색 경로가 포함된 구조화된 데이터 출력
PageIndex의 실제 활용 분야
PageIndex는 특히 다음과 같은 분야에서 뛰어난 성능을 발휘합니다:
- 재무 보고서: 복잡한 재무 데이터와 규제 정보의 정확한 검색
- 규제 서류: 법적 요구사항과 규정의 정밀한 탐색
- 학술 교과서: 체계적인 학습 내용의 구조화된 접근
- 법률 및 기술 매뉴얼: 전문적이고 상세한 정보의 효율적 검색
왜 PageIndex인가?
전통적인 RAG 시스템이 “이 내용과 유사한 것은 무엇인가?”라는 질문에 답한다면, PageIndex는 “이 질문에 대한 정확한 답은 무엇인가?”라는 질문에 답합니다.
PageIndex의 핵심 가치:
- 정확성: 유사도가 아닌 실제 관련성 기반 검색
- 투명성: 검색 과정과 결과의 완전한 추적 가능성
- 효율성: 벡터 데이터베이스 없이도 뛰어난 성능
- 확장성: 복잡하고 긴 문서에 대한 최적화된 처리
마무리
PageIndex는 단순히 새로운 RAG 도구가 아닙니다. 이는 문서 검색과 정보 추출의 패러다임을 바꾸는 혁신적인 접근법입니다. 벡터의 한계를 벗어나 인간의 사고 방식을 모방한 추론 기반 검색으로, 더 정확하고 신뢰할 수 있는 정보 검색 경험을 제공합니다.
몇가지 특징을 정리:
- 서비스 모델의 RAG, OCR
- 첨부된 문서로 부터 문서 구조를 분석하여 계층 구조의 인덱스를 생성.
- 각 인덱스로 부터 요약 및 텍스트를 정리
- RAG로 부터 질의를 받을 경우, 인덱스 json(요약 및 노드아이디를 포함된) 정보를 기반으로 질문에 필요한 인덱스의 노드를 검색(추론 기반의 검색의 의미가…여기서 부합), 필요한 노드의 정보를 취하고 그것을 기반으로 응답
- 인덱스를 생성하는 방식이 매우 인상적
- 다만, 문서의 양이 클 경우, 인덱스 생성에 대한 제한 뿐 아니라, LLM 을 통해 질의할떄 Context Window를 초과할 가능성
- 다량의 문서를 기반으로 조회가 필요할 때는 구조적 제한성을 가질듯…
PageIndex에 대한 더 자세한 정보는
https://docs.pageindex.ai
https://github.com/VectifyAI/PageIndex
를 참고하세요.
답글 남기기