




2025년 8월, OpenAI는 GPT-2 이후 6년 만에 다시 오픈 웨이트 모델을 공개했습니다. GPT-OSS-20B와 GPT-OSS-120B 모델은 단순히 크기만 큰 것이 아니라, 지난 몇 년간 축적된 트랜스포머 아키텍처의 혁신들을 집약한 결과물입니다. 이번 글에서는 GPT-2부터 GPT-OSS까지의 아키텍처 변화 과정을 살펴보고, 특히 현재 최고 성능을 자랑하는 오픈 웨이트 모델 중 하나인 Qwen3와의 비교하여 어떤 차이가 있는지에 대해서 잘 정리된 해외 자료가 있어서 그것을 기반으로 다시 정리해보았습니다. 출처: https://magazine.sebastianraschka.com/p/from-gpt-2-to-gpt-oss-analyzing-the
GPT-2에서 GPT-OSS까지의 진화
1. 드롭아웃(Dropout)의 제거
GPT-2에서는 과적합 방지를 위해 드롭아웃을 사용했지만, GPT-OSS를 포함한 최신 모델들은 이를 제거했습니다. 이는 LLM이 거대한 데이터셋을 단일 에포크로만 학습하는 특성상, 각 토큰을 한 번씩만 보기 때문에 과적합 위험이 낮기 때문입니다.
2. 위치 인코딩의 혁신: RoPE
절대 위치 임베딩을 사용했던 GPT-2와 달리, GPT-OSS는 RoPE(Rotary Position Embedding)를 채택했습니다. RoPE는 위치 정보를 별도의 임베딩으로 추가하는 대신, 쿼리와 키 벡터를 토큰의 위치에 따라 회전시키는 방식으로 위치 정보를 인코딩합니다.
3. 활성화 함수의 변화: GELU에서 SwiGLU로
GPT-OSS는 GELU 대신 SwiGLU를 사용합니다. 이는 단순히 활성화 함수를 바꾼 것이 아니라, 피드포워드 모듈을 게이트드 선형 유닛(GLU) 구조로 교체한 것입니다. SwiGLU는 계산 비용이 더 저렴하면서도 추가적인 곱셈 상호작용을 제공하여 모델의 표현력을 향상시킵니다.
4. Mixture-of-Experts(MoE)의 도입
GPT-OSS의 가장 중요한 혁신 중 하나는 단일 피드포워드 모듈을 여러 전문가(experts)로 구성된 MoE 모듈로 교체한 것입니다. 각 토큰 생성 시 모든 전문가를 사용하지 않고 라우터가 선택한 일부 전문가만을 활성화하여, 전체 파라미터 수는 늘리면서도 추론 효율성을 유지합니다.
GPT-OSS vs Qwen3: 상세한 아키텍처 비교
1. 폭(Width) vs 깊이(Depth)의 전략적 차이
GPT-OSS와 Qwen3의 가장 흥미로운 차이점은 모델 확장 전략에 있습니다.
GPT-OSS-20B의 특징:
- 24개의 트랜스포머 블록 (상대적으로 얕음)
- 임베딩 차원: 2,880 (매우 넓음)
- 중간 전문가 투영 차원: 5,760
- 32개의 전문가, 토큰당 4개 활성화
Qwen3-30B-A3B의 특징:
- 48개의 트랜스포머 블록 (GPT-OSS의 2배 깊이)
- 임베딩 차원: 2,048 (상대적으로 좁음)
- 중간 전문가 투영 차원: 768
- 128개의 전문가, 토큰당 8개 활성화
이러한 차이는 두 가지 다른 설계 철학을 보여줍니다:
- 깊은 모델(Qwen3): 더 많은 표현력을 제공하지만 훈련이 어렵고 추론 시 순차 처리로 인해 속도가 느릴 수 있습니다.
- 넓은 모델(GPT-OSS): 병렬화에 유리하여 추론 속도가 빠르지만 메모리 사용량이 큽니다.
Gemma 2 논문의 연구에 따르면, 9B 파라미터 규모에서는 넓은 설정이 깊은 설정보다 약간 우수한 성능을 보였습니다 (52.0 vs 50.8).
2. 전문가(Experts) 구성의 상반된 접근
GPT-OSS와 Qwen3는 MoE 설계에서 정반대의 접근을 취했습니다:
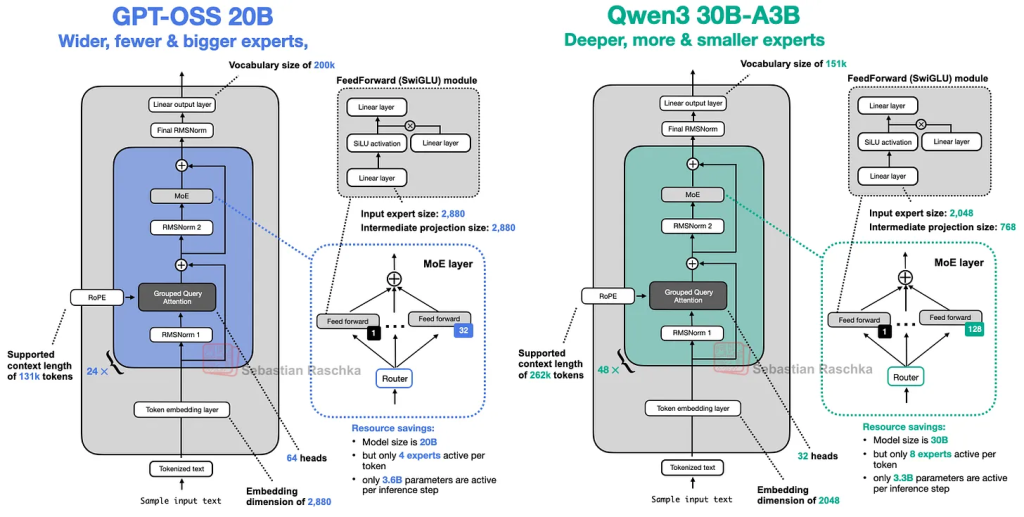
GPT-OSS: 적은 수의 큰 전문가
- 32개의 전문가
- 토큰당 4개 활성화
- 각 전문가가 더 큰 용량
Qwen3: 많은 수의 작은 전문가
- 128개의 전문가
- 토큰당 8개 활성화
- 각 전문가가 더 작은 용량
최근 DeepSeekMoE 등의 연구에서는 “더 많은 작은 전문가”가 더 나은 전문화를 가능하게 한다고 제시했지만, GPT-OSS는 이러한 트렌드에 역행하는 선택을 했습니다. 이는 모델 크기 제약이나 다른 최적화 목표가 있었을 가능성을 시사합니다.
3. 어텐션 메커니즘의 세부적 차이
두 모델 모두 GQA(Grouped Query Attention)를 사용하지만, GPT-OSS만의 독특한 특징들이 있습니다:
슬라이딩 윈도우 어텐션: GPT-OSS는 매 두 번째 레이어에서 128토큰으로 제한된 슬라이딩 윈도우 어텐션을 적용합니다. 이는 메모리 사용량과 계산 비용을 크게 줄이면서도 성능에 미미한 영향만 미칩니다.
어텐션 바이어스: GPT-2 시절 이후 거의 사용되지 않던 어텐션 바이어스를 GPT-OSS에서 다시 도입했습니다. 이론적으로는 중복적이지만 실제 성능에는 큰 차이가 없는 것으로 알려져 있습니다.
어텐션 싱크: GPT-OSS는 입력 시퀀스에 실제 토큰을 추가하는 대신, 학습 가능한 헤드별 바이어스 로짓을 어텐션 스코어에 추가하는 방식으로 어텐션 싱크를 구현했습니다.
4. 정규화 기법: RMSNorm vs LayerNorm
두 모델 모두 RMSNorm을 사용합니다. LayerNorm과 비교했을 때 RMSNorm은:
- 평균을 빼는 연산을 생략하여 계산 비용 절감
- 바이어스 항이 없어 파라미터 수 감소
- GPU에서 통신 오버헤드 감소로 훈련 효율성 향상
혁신적인 추론 시간 확장
GPT-OSS의 가장 주목할 만한 특징 중 하나는 “추론 노력도”를 사용자가 제어할 수 있다는 점입니다. 시스템 프롬프트에 “Reasoning effort: low/medium/high”를 포함하여 응답의 길이와 정확도를 조절할 수 있습니다.
이는 다음과 같은 장점을 제공합니다:
- 간단한 작업에서는 불필요한 추론 과정을 생략하여 비용과 시간 절약
- 복잡한 문제에서는 심도 있는 추론으로 정확도 향상
- 사용 사례에 따른 유연한 성능-비용 트레이드오프
MXFP4 최적화: 접근성의 혁신
GPT-OSS는 MoE 전문가에 MXFP4 양자화를 적용하여 단일 GPU에서 실행을 가능하게 했습니다:
- GPT-OSS-120B: 80GB H100 GPU 하나에서 실행 가능
- GPT-OSS-20B: 16GB VRAM (RTX 50시리즈 이상)에서 실행 가능
이는 MXFP4 지원 없이는 각각 240GB, 48GB가 필요한 것과 비교하면 혁신적인 개선입니다.
성능과 현실적 한계
현재까지의 벤치마크 결과를 보면, GPT-OSS는 상당히 인상적인 성능을 보여줍니다. 특히 GPT-OSS-120B는 Qwen3 A235B-A22B보다 거의 절반 크기임에도 불구하고 경쟁력 있는 성능을 달성했습니다.
하지만 몇 가지 한계점도 확인됩니다:
- 상대적으로 높은 환각(hallucination) 경향
- 수학, 퍼즐, 코딩에 특화된 훈련으로 인한 일반 지식의 일부 손실
이러한 특성은 도구 사용과 연계했을 때 장점이 될 수 있습니다. 사실적 질문에 대해서는 검색 엔진 등 외부 소스를 참조하고, 추론 능력이 필요한 문제에서는 모델의 강점을 활용하는 방식입니다.
결론
GPT-OSS와 Qwen3의 비교는 현재 AI 개발의 다양한 접근 방식을 잘 보여줍니다. GPT-OSS는 “넓고 얕은” 아키텍처와 효율적인 양자화를 통해 접근성을 높였고, Qwen3는 “깊고 좁은” 설계로 표현력을 극대화했습니다.
두 모델 모두 Apache 2.0 라이선스로 공개되어 상업적 활용이 자유롭고, 각각의 설계 철학에 따른 뚜렷한 장단점을 가지고 있습니다. 특히 GPT-OSS의 추론 시간 확장 기능과 단일 GPU 실행 가능성은 오픈 소스 AI 생태계에 새로운 가능성을 제시합니다.
앞으로 도구 통합이 성숙해지면서 추론 능력에 특화된 모델들이 더욱 실용적인 가치를 발휘할 것으로 예상됩니다. 마치 인간 학습에서 암기보다 문제 해결 능력이 중요한 것처럼, AI 모델도 지식 저장보다는 추론 능력이 더 중요해질 수 있습니다.
답글 남기기