




LangFlow 소개
LangFlow는 AI 애플리케이션을 시각적 인터페이스로 빠르게 프로토타이핑하고 구축할 수 있는 강력한 로우코드 플랫폼입니다. 특히 에이전트(Agent) 기반 시스템과 RAG(Retrieval-Augmented Generation) 애플리케이션 개발에 특화되어 있습니다.
주요 특징
- 시각적 워크플로우 빌더: 드래그 앤 드롭으로 AI 파이프라인 구성
- 광범위한 호환성: 모든 주요 LLM 및 벡터 데이터베이스 지원
- 내장 API 서버: 모든 워크플로우를 API로 자동 변환
- MCP(Model Context Protocol) 지원: 에이전트 기능 강화
- Python 커스터마이징: 필요시 Python 코드로 확장 가능
- 오픈소스: 완전한 오픈소스 프로젝트
설치 환경 및 요구사항
시스템 요구사항
- Python: 3.10 이상
- 운영체제: Windows, macOS, Linux
- 메모리: 최소 4GB RAM 권장
- 디스크 공간: 2GB 이상 여유 공간
선택적 도구
- Docker: 컨테이너 기반 배포 시
- Kubernetes: 프로덕션 환경 배포 시
- Git: 소스코드 관리 시
설치 방법
1. pip를 이용한 설치 (권장)
가장 간단한 설치 방법입니다:
# 기본 설치 pip install langflow # 특정 버전 설치 pip install langflow==1.4.22 # 의존성 포함 완전 재설치 pip install langflow --force-reinstall # 최신 버전으로 업그레이드 pip install langflow --upgrade
2. UV를 이용한 설치 (빠른 패키지 관리)
# UV 설치 (아직 설치하지 않은 경우) curl -LsSf https://astral.sh/uv/install.sh | sh # LangFlow 설치 uv pip install langflow # 특정 버전 설치 uv pip install langflow==1.4.22
3. Docker를 이용한 설치
컨테이너 환경에서 실행하고 싶은 경우:
# 공식 Docker 이미지 실행
docker run -it -p 7860:7860 langflowai/langflow:latest
# 볼륨 마운트로 데이터 영구 저장
docker run -it -p 7860:7860 -v $(pwd)/langflow_data:/app/data langflowai/langflow:latest
4. GitHub에서 소스코드 설치
개발자용 설치:
# 저장소 클론
git clone https://github.com/langflow-ai/langflow.git
cd langflow
# 개발 환경 설정
pip install -e .
# 의존성 설치
pip install -r requirements.txt
기본 사용방법
LangFlow 실행
설치 완료 후 다음 명령으로 실행:
# 기본 실행 langflow run # 특정 포트로 실행 langflow run --port 8080 # 외부 접근 허용 langflow run --host 0.0.0.0 # 백그라운드 실행 nohup langflow run &
실행 후 브라우저에서 http://localhost:7860으로 접속합니다.
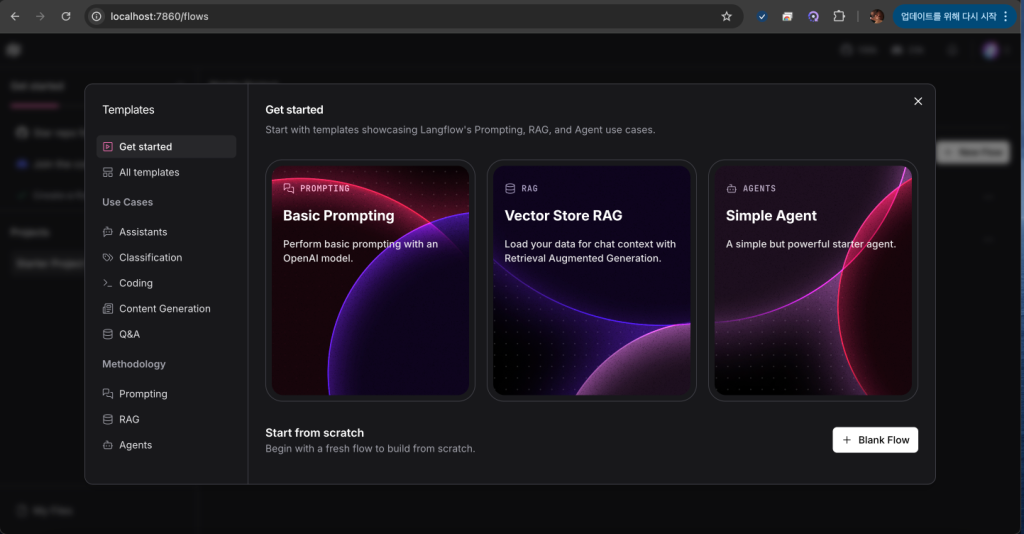
첫 번째 플로우 생성
- 새 프로젝트 생성: “New Project” 클릭
- 빈 플로우 선택: “Blank Flow” 선택
- 컴포넌트 추가: 왼쪽 사이드바에서 원하는 컴포넌트를 드래그
- 연결: 컴포넌트들을 선으로 연결
- 설정: 각 컴포넌트의 파라미터 설정
- 실행: 플레이 버튼으로 테스트
인터페이스 구조
- 컴포넌트 패널: 왼쪽에 사용 가능한 모든 컴포넌트
- 캔버스: 중앙의 워크플로우 설계 영역
- 설정 패널: 오른쪽에 선택된 컴포넌트 설정
- 실행 패널: 하단에 실행 결과 및 로그
실습 예제
예제 1: 간단한 챗봇 만들기
기본적인 OpenAI 기반 챗봇을 만들어보겠습니다:
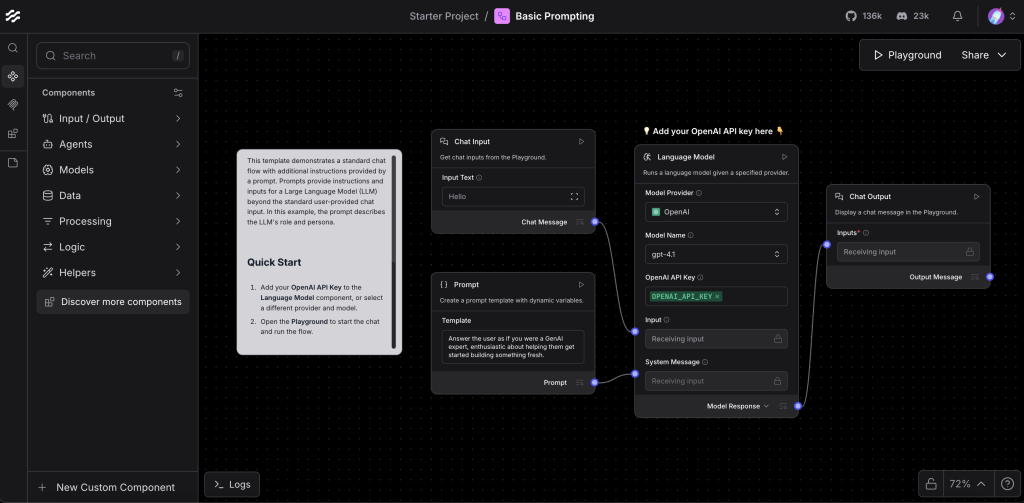
# 필요한 컴포넌트 구성:
# 1. Chat Input (사용자 입력)
# 2. OpenAI (LLM 모델)
# 3. Chat Output (결과 출력)
단계별 구성:
- Chat Input 컴포넌트 추가
- 왼쪽 패널에서 “Chat Input” 선택
- 캔버스에 드래그 앤 드롭
- OpenAI 컴포넌트 추가
- “LLMs” 섹션에서 “OpenAI” 선택
- API Key 설정 필요
- Chat Output 컴포넌트 추가
- “Outputs” 섹션에서 “Chat Output” 선택
- 연결
- Chat Input → OpenAI → Chat Output 순서로 연결
예제 2: RAG 시스템 구축
문서 기반 질의응답 시스템:’
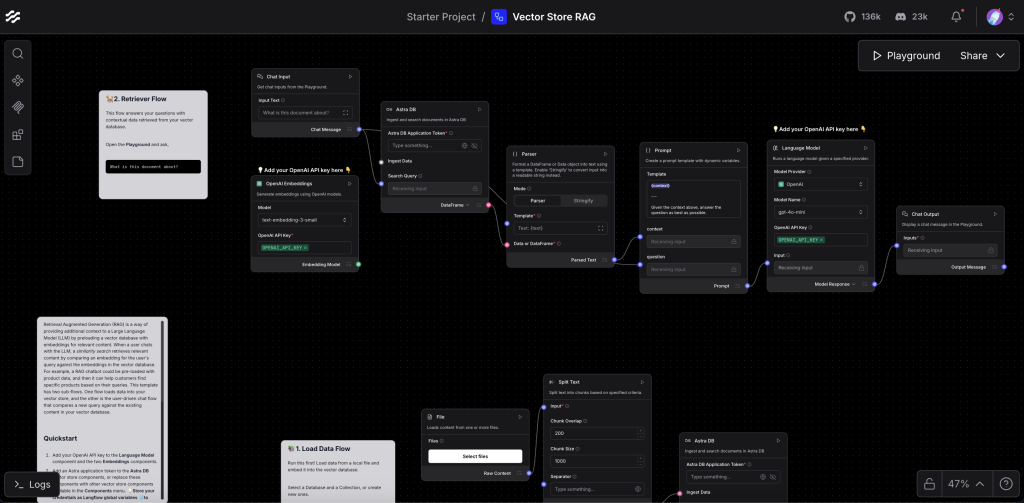
# 컴포넌트 구성:
# 1. File (문서 업로드)
# 2. Text Splitter (텍스트 분할)
# 3. Embeddings (임베딩 생성)
# 4. Vector Store (벡터 저장)
# 5. Retriever (문서 검색)
# 6. Prompt Template (프롬프트)
# 7. LLM (언어 모델)
구성 단계:
- 문서 처리 파이프라인
File → Text Splitter → Embeddings → Vector Store - 검색 및 생성 파이프라인
Query Input → Retriever → Prompt Template → LLM → Output
예제 3: 에이전트 시스템
도구를 사용하는 AI 에이전트:
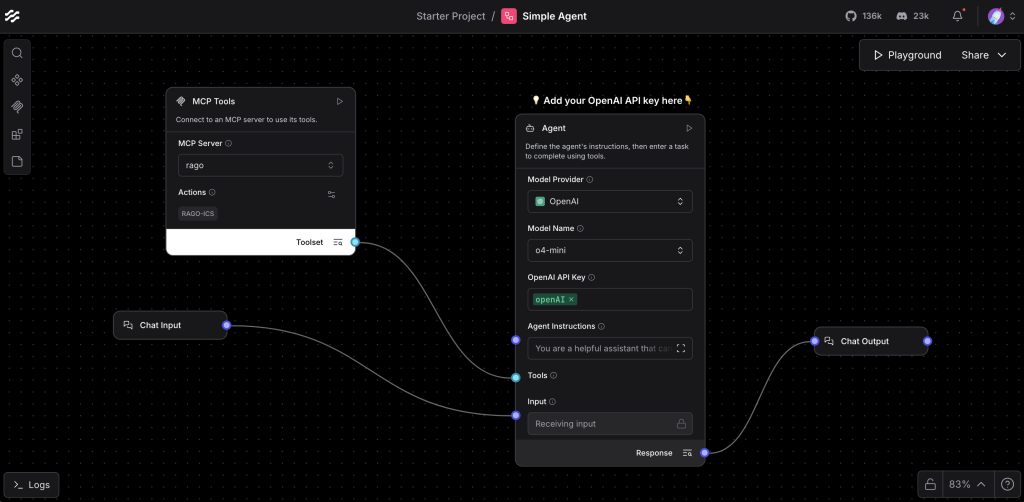
# 컴포넌트:
# 1. Agent (에이전트 컴포넌트)
# 2. Tools (사용할 도구들)
# 3. Memory (대화 기억)
# 4. LLM (언어 모델)
주요 컴포넌트 소개
1. 입력/출력 컴포넌트
Chat Input
- 사용자로부터 텍스트 입력 받기
- 세션 관리 기능 포함
Chat Output
- 결과를 사용자에게 출력
- 스트리밍 응답 지원
File Input
- 다양한 파일 형식 지원 (PDF, TXT, DOCX 등)
- 자동 텍스트 추출
2. 언어 모델 (LLMs)
OpenAI
- GPT-3.5, GPT-4 시리즈 지원
- API 키 설정 필요
- Temperature, Max Tokens 등 설정 가능
Anthropic Claude
- Claude 시리즈 모델 지원
- 긴 컨텍스트 처리 특화
Local Models
- Ollama 연동 지원
- 로컬 모델 실행 가능
3. 임베딩 모델
OpenAI Embeddings
- text-embedding-ada-002 등 지원
- 벡터 차원: 1536
HuggingFace Embeddings
- 다양한 오픈소스 모델 지원
- 한국어 특화 모델 사용 가능
4. 벡터 데이터베이스
Chroma
- 경량 벡터 DB
- 로컬 및 클라우드 지원
Pinecone
- 확장 가능한 클라우드 벡터 DB
- 실시간 업데이트 지원
Weaviate
- GraphQL 지원
- 하이브리드 검색 가능
5. 텍스트 처리
Text Splitter
- 다양한 분할 전략 지원
- 청크 크기 및 겹침 설정
Document Loader
- 웹페이지, 데이터베이스 등 연동
- 실시간 데이터 수집
6. 메모리 컴포넌트
Conversation Buffer Memory
- 대화 히스토리 저장
- 토큰 수 기반 관리
Vector Store Memory
- 임베딩 기반 기억
- 의미적 유사성으로 검색
7. 도구 (Tools)
Calculator
- 수학 계산 수행
- Python 표현식 지원
Search Tool
- 웹 검색 기능
- Google, DuckDuckGo 등 지원
API Tool
- REST API 호출
- 커스텀 API 연동
API 활용 방법
REST API 기본 사용법
LangFlow는 자동으로 각 플로우를 API 엔드포인트로 변환합니다.
플로우 실행 API
import requests
# 기본 API 호출
url = "http://localhost:7860/api/v1/run/{FLOW_ID}"
payload = {
"input_value": "안녕하세요!",
"output_type": "chat",
"input_type": "chat"
}
headers = {
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
result = response.json()
cURL 예제
curl -X POST "http://localhost:7860/api/v1/run/{FLOW_ID}" \
-H "Content-Type: application/json" \
-d '{
"input_value": "안녕하세요!",
"output_type": "chat",
"input_type": "chat"
}'
Python SDK 사용법
from langflow import LangflowClient
# 클라이언트 초기화
client = LangflowClient(
base_url="http://localhost:7860",
api_key="your_api_key" # 필요시
)
# 플로우 실행
result = client.run_flow(
flow_id="your_flow_id",
inputs={"message": "안녕하세요!"}
)
print(result)
스트리밍 API
실시간 응답을 위한 스트리밍:
import requests
import json
def stream_response(flow_id, message):
url = f"http://localhost:7860/api/v1/run/{flow_id}/stream"
payload = {
"input_value": message,
"stream": True
}
with requests.post(url, json=payload, stream=True) as response:
for line in response.iter_lines():
if line:
data = json.loads(line.decode('utf-8'))
yield data
Webhook 설정
외부 시스템에서 트리거:
# Webhook URL: http://localhost:7860/api/v1/webhook/{FLOW_ID}
# 웹훅 페이로드 예제
webhook_payload = {
"event": "message_received",
"data": {
"user_id": "user123",
"message": "도움이 필요합니다"
}
}
프로덕션 배포
1. Docker 컨테이너 배포
Dockerfile 생성
FROM langflowai/langflow:latest
# 환경 변수 설정
ENV LANGFLOW_HOST=0.0.0.0
ENV LANGFLOW_PORT=7860
# 사용자 정의 설정
COPY langflow.toml /app/
COPY flows/ /app/flows/
EXPOSE 7860
CMD ["langflow", "run", "--host", "0.0.0.0", "--port", "7860"]
Docker Compose 설정
version: '3.8'
services:
langflow:
image: langflowai/langflow:latest
ports:
- "7860:7860"
environment:
- LANGFLOW_DATABASE_URL=postgresql://user:pass@db:5432/langflow
volumes:
- ./flows:/app/flows
- ./data:/app/data
depends_on:
- db
- redis
db:
image: postgres:13
environment:
- POSTGRES_DB=langflow
- POSTGRES_USER=user
- POSTGRES_PASSWORD=pass
volumes:
- postgres_data:/var/lib/postgresql/data
redis:
image: redis:6-alpine
volumes:
postgres_data:
2. Kubernetes 배포
Helm Chart 사용
# Helm 저장소 추가 helm repo add langflow https://langflow-ai.github.io/langflow-helm # 값 파일 생성 (values.yaml) replicaCount: 3 image: repository: langflowai/langflow tag: latest pullPolicy: IfNotPresent service: type: LoadBalancer port: 7860 ingress: enabled: true host: langflow.yourdomain.com autoscaling: enabled: true minReplicas: 2 maxReplicas: 10 targetCPUUtilizationPercentage: 70 # 배포 실행 helm install langflow langflow/langflow -f values.yaml
직접 YAML 작성
apiVersion: apps/v1
kind: Deployment
metadata:
name: langflow-deployment
spec:
replicas: 3
selector:
matchLabels:
app: langflow
template:
metadata:
labels:
app: langflow
spec:
containers:
- name: langflow
image: langflowai/langflow:latest
ports:
- containerPort: 7860
env:
- name: LANGFLOW_HOST
value: "0.0.0.0"
- name: LANGFLOW_DATABASE_URL
valueFrom:
secretKeyRef:
name: langflow-secrets
key: database-url
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "2Gi"
cpu: "1000m"
---
apiVersion: v1
kind: Service
metadata:
name: langflow-service
spec:
selector:
app: langflow
ports:
- protocol: TCP
port: 80
targetPort: 7860
type: LoadBalancer
3. 클라우드 배포
AWS ECS/Fargate
{
"family": "langflow-task",
"networkMode": "awsvpc",
"requiresCompatibilities": ["FARGATE"],
"cpu": "1024",
"memory": "2048",
"executionRoleArn": "arn:aws:iam::account:role/ecsTaskExecutionRole",
"containerDefinitions": [
{
"name": "langflow",
"image": "langflowai/langflow:latest",
"portMappings": [
{
"containerPort": 7860,
"protocol": "tcp"
}
],
"environment": [
{
"name": "LANGFLOW_HOST",
"value": "0.0.0.0"
}
],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/langflow",
"awslogs-region": "us-west-2",
"awslogs-stream-prefix": "ecs"
}
}
}
]
}
Google Cloud Run
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: langflow-service
annotations:
run.googleapis.com/ingress: all
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/maxScale: "10"
run.googleapis.com/cpu-throttling: "false"
spec:
containerConcurrency: 1000
containers:
- image: gcr.io/PROJECT_ID/langflow
ports:
- containerPort: 7860
env:
- name: LANGFLOW_HOST
value: "0.0.0.0"
resources:
limits:
cpu: "2"
memory: "4Gi"
4. 환경 설정 및 보안
환경 변수 설정
# 데이터베이스 설정 export LANGFLOW_DATABASE_URL="postgresql://user:pass@localhost:5432/langflow" # 캐시 설정 export LANGFLOW_CACHE_TYPE="redis" export LANGFLOW_REDIS_URL="redis://localhost:6379/0" # 보안 설정 export LANGFLOW_SECRET_KEY="your-secret-key" export LANGFLOW_JWT_SECRET="your-jwt-secret" # 로깅 설정 export LANGFLOW_LOG_LEVEL="INFO" export LANGFLOW_LOG_FILE="langflow.log"
보안 모범 사례
# langflow_config.py
from langflow.settings import Settings
class ProductionSettings(Settings):
# HTTPS 강제
FORCE_SSL = True
# CORS 설정
ALLOW_ORIGINS = ["https://yourdomain.com"]
# API 키 인증 필수
REQUIRE_API_KEY = True
# 요청 제한
RATE_LIMIT = "100/minute"
# 데이터베이스 연결 풀
DATABASE_POOL_SIZE = 20
DATABASE_MAX_OVERFLOW = 30
모범 사례 및 팁
1. 성능 최적화
캐싱 전략
# Redis 캐싱 설정
LANGFLOW_CACHE_CONFIG = {
"type": "redis",
"url": "redis://localhost:6379/0",
"expire": 3600, # 1시간
"key_prefix": "langflow:"
}
비동기 처리
# 비동기 워크플로우 설정
from langflow.components.async_component import AsyncComponent
class AsyncRAGComponent(AsyncComponent):
async def run(self, inputs):
# 비동기 문서 검색
documents = await self.async_retrieve(inputs["query"])
# 병렬 임베딩 생성
embeddings = await self.parallel_embed(documents)
return {"documents": documents, "embeddings": embeddings}
2. 모니터링 및 로깅
로그 설정
import logging
from langflow.logging import setup_logging
# 구조화된 로깅
setup_logging(
level=logging.INFO,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
handlers=[
logging.FileHandler("langflow.log"),
logging.StreamHandler()
]
)
메트릭 수집
from prometheus_client import Counter, Histogram, start_http_server
# 메트릭 정의
REQUEST_COUNT = Counter('langflow_requests_total', 'Total requests')
REQUEST_DURATION = Histogram('langflow_request_duration_seconds', 'Request duration')
# 메트릭 서버 시작
start_http_server(8000)
3. 테스트 전략
단위 테스트
import pytest
from langflow.components import OpenAIComponent
class TestOpenAIComponent:
def setup_method(self):
self.component = OpenAIComponent()
def test_basic_completion(self):
result = self.component.run({
"input": "Hello, world!",
"model": "gpt-3.5-turbo"
})
assert "output" in result
assert len(result["output"]) > 0
@pytest.mark.asyncio
async def test_async_completion(self):
result = await self.component.async_run({
"input": "Hello, world!",
"model": "gpt-3.5-turbo"
})
assert result is not None
통합 테스트
from langflow.testing import FlowTester
def test_rag_pipeline():
tester = FlowTester("rag_flow.json")
# 테스트 데이터 준비
test_documents = ["문서1 내용", "문서2 내용"]
test_query = "테스트 질문"
# 플로우 실행
result = tester.run({
"documents": test_documents,
"query": test_query
})
# 결과 검증
assert "answer" in result
assert result["confidence"] > 0.5
4. 버전 관리 및 배포
Git 워크플로우
# 플로우 버전 관리
git add flows/
git commit -m "feat: RAG 플로우 성능 개선"
# 태그 생성
git tag -a v1.2.0 -m "Release v1.2.0"
git push origin v1.2.0
CI/CD 파이프라인
# .github/workflows/deploy.yml
name: Deploy LangFlow
on:
push:
tags:
- 'v*'
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Build Docker image
run: |
docker build -t langflow:${{ github.ref_name }} .
- name: Deploy to Kubernetes
run: |
kubectl set image deployment/langflow langflow=langflow:${{ github.ref_name }}
kubectl rollout status deployment/langflow
5. 문제 해결
일반적인 오류
메모리 부족 오류
# 배치 처리로 해결
def process_large_dataset(data, batch_size=100):
for i in range(0, len(data), batch_size):
batch = data[i:i+batch_size]
yield process_batch(batch)
API 호출 제한
import time
from functools import wraps
def rate_limit(calls_per_second=1):
def decorator(func):
last_called = [0.0]
@wraps(func)
def wrapper(*args, **kwargs):
elapsed = time.time() - last_called[0]
left_to_wait = 1.0 / calls_per_second - elapsed
if left_to_wait > 0:
time.sleep(left_to_wait)
ret = func(*args, **kwargs)
last_called[0] = time.time()
return ret
return wrapper
return decorator
연결 타임아웃
import httpx
# 타임아웃 설정
client = httpx.AsyncClient(
timeout=httpx.Timeout(30.0, connect=5.0)
)
결론
LangFlow는 AI 애플리케이션 개발의 진입 장벽을 크게 낮춰주는 강력한 도구입니다. 시각적 인터페이스를 통해 복잡한 AI 워크플로우를 쉽게 구성할 수 있으며, 필요에 따라 Python 코드로 확장할 수 있는 유연성을 제공합니다.
특히 RAG 시스템, 챗봇, AI 에이전트 등의 구축에 특화되어 있어, 빠른 프로토타이핑부터 프로덕션 배포까지 전체 개발 사이클을 지원합니다. 오픈소스라는 장점을 활용하여 커뮤니티의 다양한 컴포넌트와 템플릿을 활용할 수 있습니다.
앞으로 AI 기술이 더욱 발전함에 따라 LangFlow와 같은 로우코드 플랫폼의 중요성은 더욱 커질 것으로 예상됩니다. 이 가이드를 통해 LangFlow를 효과적으로 활용하여 혁신적인 AI 애플리케이션을 구축하시기 바랍니다.
추가로 n8n에 비교하지 않을 순 없는데, 미려한 UI 뒤에 순차적인 흐름을 한눈에 보는데는 다소 복잡해 보이는 부분이 있습니다. 그리고, 실행 과정의 절차를 실시간으로 볼수 없는 아쉬움도 있습니다. 그러나, 각 노드별 입력값 설정은 비교적 단순하여 설정의 용이한 부분은 있습니다.
프로덕션 레벨에서는 안정적인 환경 구성을 위해 기능 구성에 좀더 많은 테스트가 필요할순 있을것 같습니다.
참고링크
- 공식 문서: https://docs.langflow.org/
- GitHub 저장소: https://github.com/langflow-ai/langflow
이 포스트가 LangFlow 학습과 활용에 도움이 되기를 바랍니다!
답글 남기기