




웹 스크래핑은 데이터 분석, 마케팅 리서치, 가격 모니터링 등 다양한 분야에서 필수적인 작업입니다. 때문에 요즘 오픈소스 스크래퍼 또는 크롤링 도구들이 많이 요구 됩니다. 오늘 소개할 어플리케이션도 이 웹스크래핑을 위한 셀프호스트 기반의 웹스크래퍼 인 Scraperr에 대한 포스트를 하려고 합니다.
RAG 시스템에 웹사이트의 컨텐츠를 Ingest하기 위해서는 웹사이트의 데이터 스크래핑이 반드시 요구 됩니다. 그 과정에서 여러 크롤러 또는 스크래퍼들을 찾아보다가 직접 만들어보기도 했습니다. 웹 페이지의 특정 요소를 정교하게 스크래핑을 하거나, 또는 URL의 수집 범위 , 제외 범위 등의 정교한 설정에 어려움이 많았습니다. 또한 백그라운드 실행을 하다가 중간에 멈췄을 때 이어서 스크래핑을 하는 방법 등 미리 고려해야할 것들이 많습니다.
이러한 고민들이 한꺼번에 반영된 도구라 할 수 있을것 같습니다.
Scraperr란?

Scraperr는 셀프 호스팅 방식의 웹 스크래핑 서비스로, 복잡한 코딩 없이도 웹사이트에서 데이터를 추출하고 데이터베이스에 저장할 수 있게 해줍니다. MIT 라이선스로 오픈소스로 공개되어 있으며, Docker를 통해 손쉽게 배포할 수 있습니다.
Scraperr의 가장 큰 장점은 사용자 친화적인 웹 인터페이스입니다. 프론트엔드가 API와 분리되어 있어, 웹 UI를 통해 사용할 수도 있고, 다른 애플리케이션에서 API를 직접 호출할 수도 있습니다.
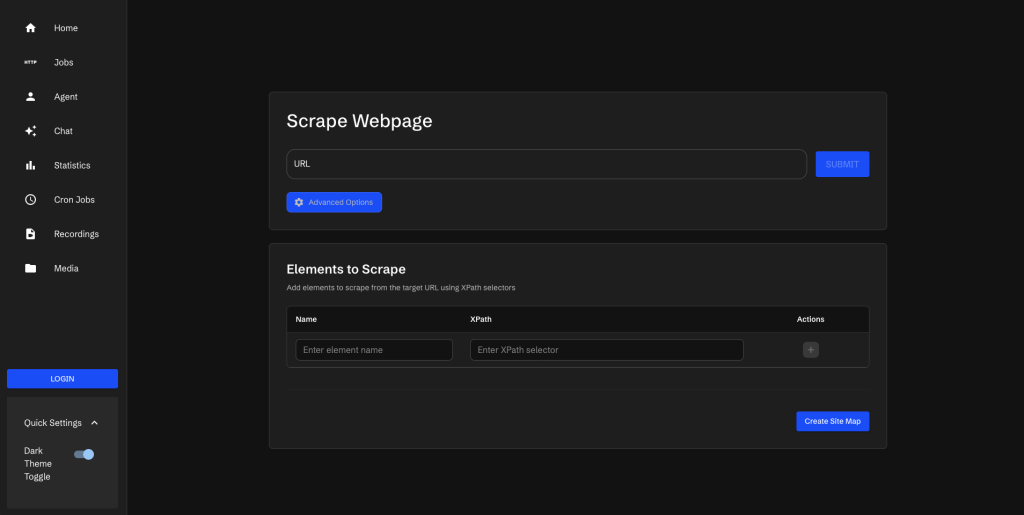
주요 기능
1. XPath 기반 정밀 추출
XPath 선택자를 사용하여 원하는 페이지 요소를 정확하게 타겟팅할 수 있습니다. 복잡한 HTML 구조에서도 정확히 필요한 데이터만 추출할 수 있죠.
2. 작업 큐 관리
여러 개의 스크래핑 작업을 큐에 제출하고 관리할 수 있습니다. 작업 테이블에서는 모든 스크래핑 작업의 상태를 실시간으로 확인할 수 있으며, ID, URL, 상태별로 필터링하여 검색할 수 있습니다. 중요한 작업은 즐겨찾기로 표시하여 나중에 쉽게 찾을 수 있습니다.
3. 도메인 스파이더링
동일 도메인 내의 모든 페이지를 자동으로 크롤링하는 멀티 페이지 스크래핑 기능을 제공합니다. 여러 페이지에 걸쳐 있는 데이터를 한 번에 수집할 수 있습니다.
4. 사이트 맵핑 (Site Mapping)
웹사이트를 스크래핑할 때 일련의 액션을 자동화할 수 있는 강력한 기능입니다. 예를 들어:
- “다음” 버튼을 클릭하여 여러 페이지 탐색
- 입력 필드에 데이터 입력
- 특정 요소 클릭하여 숨겨진 콘텐츠 표시
각 액션은 XPath 선택자를 사용하여 정의하며, “한 번만 실행” 옵션을 통해 첫 페이지에서만 실행되도록 설정할 수도 있습니다.
5. 미디어 자동 다운로드
스크래핑 과정에서 발견된 이미지, 비디오, 문서 등 모든 미디어 파일을 자동으로 다운로드합니다. 원본 파일명과 형식을 유지하며 구조화된 디렉토리에 정리됩니다.
6. AI 통합
OpenAI GPT 모델이나 Ollama를 연결하여 수집된 데이터에 대해 자연어로 질문할 수 있습니다. 각 작업별로 채팅이 저장되어, 스크래핑한 데이터를 더 효과적으로 분석하고 인사이트를 얻을 수 있습니다.
7. 고급 설정 옵션
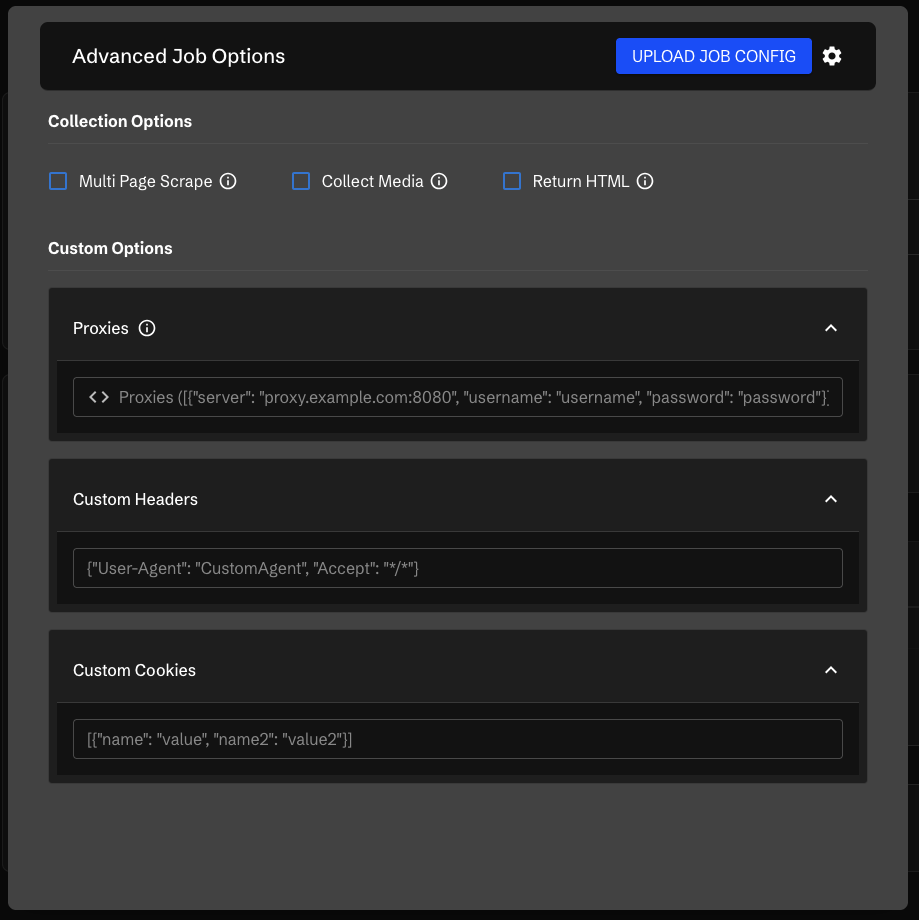
커스텀 헤더: JSON 형식으로 커스텀 헤더를 추가하여 User-Agent 설정, 인증 헤더 추가 등이 가능합니다.
쿠키 관리: 인증이 필요한 콘텐츠에 접근하거나 세션을 유지해야 할 때 커스텀 쿠키를 JSON 형식으로 제공할 수 있습니다.
프록시 지원: 쉼표로 구분된 프록시 목록을 제공하여 속도 제한 회피, 지역 제한 콘텐츠 접근, 여러 IP로 요청 분산이 가능합니다.
8. 데이터 내보내기
수집된 데이터는 CSV나 Markdown 형식으로 내보낼 수 있어, 스프레드시트나 다른 분석 도구에서 바로 활용할 수 있습니다.
9. 알림 채널
작업 완료 시 Discord 웹훅이나 SMTP 이메일을 통해 알림을 받을 수 있습니다. 장시간 실행되는 스크래핑 작업도 안심하고 맡길 수 있습니다.
빠른 시작
Scraperr를 시작하는 것은 매우 간단합니다:
# 1. 저장소 클론 및 이동
git clone https://github.com/jaypyles/Scraperr.git
cd Scraperr
# 2. docker-compose.yml에서 환경 변수 설정 (선택사항)
# 3. Docker 컨테이너 실행
make up
이제 http://localhost로 접속하면 Scraperr 웹 인터페이스가 나타납니다.
첫 스크래핑 작업 제출하기
- URL 입력: 스크래핑하고 싶은 웹사이트의 URL을 입력합니다.
- 요소 선택: 테이블이 나타나면 추출하려는 데이터의 이름과 XPath 선택자를 입력합니다.
- 고급 옵션 설정: 필요하다면 사이트 맵핑, 커스텀 헤더, 프록시 등을 설정합니다.
- 제출: 작업이 큐에 추가되고 작업 테이블로 이동합니다.
- 결과 다운로드: 작업이 완료되면 “Download” 버튼을 클릭하여 CSV 파일로 결과를 받습니다.
선택적 구성
Scraperr는 다양한 환경에 맞게 커스터마이징할 수 있습니다:
사용자 등록 비활성화: REGISTRATION_ENABLED=False로 설정하여 관리자만 접근하도록 제한할 수 있습니다.
데이터베이스 선택: 기본 SQLite 외에도 PostgreSQL, MySQL을 지원합니다.
녹화 비활성화: 스크래핑 과정의 비디오 녹화를 끌 수 있습니다.
VNC 연결: 5900 포트를 노출하여 VNC 뷰어로 브라우저 세션을 직접 모니터링할 수 있습니다.
Helm 배포
Kubernetes 환경에서 운영하고 싶다면 Helm 차트를 사용하여 쉽게 배포할 수 있습니다. 자세한 내용은 공식 문서를 참고하세요.
윤리적 웹 스크래핑을 위한 주의사항
Scraperr는 강력한 도구이지만, 책임감 있게 사용해야 합니다:
- robots.txt 존중: 항상 웹사이트의
robots.txt파일을 확인하여 스크래핑이 허용되는지 확인하세요. - 서비스 약관 준수: 각 웹사이트의 서비스 약관을 준수하세요.
- 속도 제한: 요청 간 적절한 지연을 두어 서버에 과부하를 주지 않도록 하세요.
Scraperr는 명시적으로 스크래핑을 허용하는 웹사이트에서만 사용하도록 설계되었습니다.
마치며
Scraperr는 웹 스크래핑의 진입 장벽을 크게 낮춘 혁신적인 도구입니다. 코딩 지식 없이도 강력한 데이터 수집 파이프라인을 구축할 수 있으며, AI 통합을 통해 수집한 데이터를 즉시 분석할 수 있습니다.
셀프 호스팅 방식이라 데이터 프라이버시도 보장되며, API를 통해 다른 애플리케이션과 통합하기도 쉽습니다. 데이터 분석가, 마케터, 연구자, 개발자 모두에게 유용한 도구가 될 것입니다.
특히, 섬세한 지정영역 의 수집이라거나, 입력 이벤트를 고려한 수집에 특화되어 보이고, Cron tab 설정으로 정기적인 수집에는 매우 편리한 도구가 될것 같습니다.
다소 아쉬운 부분은 다음과 같습니다.
- 진행에 대한 상태를 알수가 없기 때문에 프로세스가 종료될 때까지 기다려야 합니다.
- 동일 도메인 내에서 세부 분리된 설정이 불가능합니다. 특정 디렉토리를 제외한다거나, 특정 유형의 페이지를 제외할수 없습니다.
- 수집간 실패 시 원인을 찾아 대처하기 어렵습니다.
- 통계의 반영이 즉각적으로 이루어지지 않습니다.
좀 더 자세한 내용은 GitHub를 참고해보세요!
참고 자료
답글 남기기