




langchain을 이용한 chat client를 만들다보면, 이 두개 함수의 차이를 크게 느끼는데, 똑같은 로직에서 함수만 다르게 쓰는데도 응답 품질에 큰 차이가 발생됩니다.
지금부터 이 두개 함수의 차이에 대한 포스팅을 하겠습니다.
ainvoke()와 astream()은 LangChain 라이브러리에서 사용되는 두 가지 주요 비동기 실행 함수입니다. 이 둘의 가장 큰 차이점은 결과를 반환하는 방식에 있습니다.
ainvoke()
ainvoke()는 단일 결과를 비동기적으로 반환합니다.
- 동작 방식: 체인(Chain)이나 모델을 호출하면, 모든 처리가 완료될 때까지 기다렸다가 최종 결과물을 한 번에 받습니다.
- 반환 타입: 일반적으로 AIMessage 객체나 문자열과 같은 단일 완성형 응답입니다.
- 주요 사용 사례:
- 최종 결과만 필요한 경우 (예: 텍스트 요약, 번역, 분류)
- 대화형 챗봇에서 사용자의 단일 질문에 대한 완전한 답변을 생성할 때
astream()
astream()은 스트리밍 형태로 여러 개의 부분적인 결과를 비동기적으로 반환합니다.
- 동작 방식: 모델이 결과를 생성하는 즉시, 작은 조각(chunk) 단위로 나누어 실시간으로 전달받습니다. 모든 조각을 합치면 ainvoke()의 결과와 동일해집니다.
- 반환 타입: 비동기 이터레이터(Async Iterator)이며, 각 항목은 응답의 일부인 ‘청크(chunk)’입니다.
- 주요 사용 사례:
- ChatGPT와 같이 타이핑하는 것처럼 실시간으로 답변을 보여주고 싶을 때
- 긴 텍스트를 생성할 때 사용자 경험(UX)을 향상시키고 싶을 때
- 생성 과정의 중간 결과나 진행 상황을 확인해야 할 때
차이를 구분할 수 있는 예제 코드
import asyncio
import time
class FakeStreamingLLM:
"""
LLM의 동작을 흉내 내는 가짜 클래스입니다.
ainvoke와 astream의 차이를 보여주기 위해 사용됩니다.
"""
async def _generate_chunks(self, prompt: str):
"""응답을 단어 단위로 생성하는 것을 시뮬레이션합니다."""
response_sentence = f"'{prompt}'라는 질문에 대한 답변입니다. 이 문장은 스트리밍으로 생성됩니다."
words = response_sentence.split()
for word in words:
# 각 단어를 생성하는 데 0.3초가 걸린다고 가정합니다.
await asyncio.sleep(0.3)
yield f"{word} "
async def ainvoke(self, prompt: str) -> str:
"""모든 응답이 생성될 때까지 기다린 후 전체 문장을 반환합니다."""
print(f"\n[ainvoke 시작] '{prompt}'에 대한 답변 생성을 시작합니다... (전체 응답을 기다리는 중)")
start_time = time.time()
# 스트리밍 결과를 모두 모아서 하나의 문자열로 만듭니다.
final_result = "".join([chunk async for chunk in self._generate_chunks(prompt)])
end_time = time.time()
print(f"[ainvoke 종료] 총 소요 시간: {end_time - start_time:.2f}초")
return final_result
async def astream(self, prompt: str):
"""응답의 각 부분이 생성될 때마다 즉시 반환(yield)합니다."""
print(f"\n[astream 시작] '{prompt}'에 대한 답변을 스트리밍으로 받습니다...")
start_time = time.time()
async for chunk in self._generate_chunks(prompt):
yield chunk
end_time = time.time()
# 스트리밍이 모두 끝난 후 총 시간을 출력합니다.
# 하지만 사용자는 이 시간 이전에 이미 결과를 보고 있습니다.
print(f"\n[astream 종료] 총 소-요 시간: {end_time - start_time:.2f}초")
async def main():
"""ainvoke와 astream의 동작을 비교하는 메인 함수"""
llm = FakeStreamingLLM()
my_prompt = "날씨가 어떤가요"
# 1. ainvoke() 사용 예제
# ------------------------------------
full_response = await llm.ainvoke(my_prompt)
print("\n--- ainvoke 결과 ---")
print(f"최종 응답 (한 번에 받음):\n{full_response}")
print("--------------------")
print("\n" + "="*50 + "\n") # 구분선
# 2. astream() 사용 예제
# ------------------------------------
print("\n--- astream 결과 ---")
print("부분 응답 (실시간으로 받음):")
# async for 루프를 사용하여 스트리밍 데이터를 실시간으로 처리합니다.
async for partial_response in llm.astream(my_prompt):
print(partial_response, end="", flush=True) # end=""와 flush=True로 타이핑 효과를 냅니다.
print("\n--------------------")
if __name__ == "__main__":
asyncio.run(main())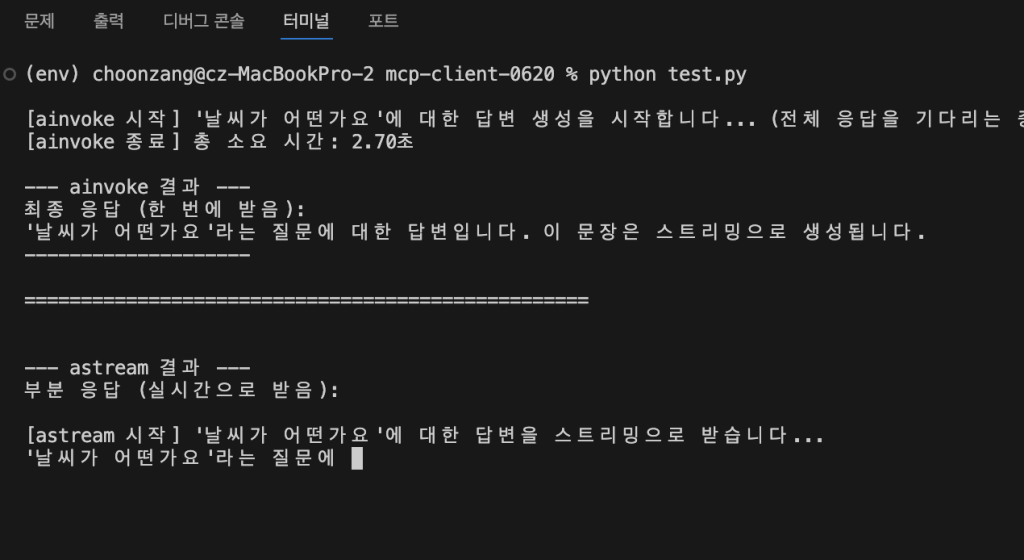
핵심 차이점 요약
| 구분 | ainvoke() | astream() |
| 반환 방식 | 모든 처리가 끝난 후 단일 결과를 한 번에 반환 | 처리 과정에서 생성되는 **부분적인 결과(청크)**를 실시간으로 스트리밍 |
| 반환 타입 | 단일 객체 (예: AIMessage) | 비동기 이터레이터 (Async Iterator) |
| 사용자 경험 | 응답을 받기까지 대기 시간이 있음 | 즉각적인 피드백으로 대기 시간이 짧게 느껴짐 (UX 향상) |
| 주요 용도 | 최종 결과만 필요한 작업 | 실시간 응답 표시, 긴 텍스트 생성 |
간단히 말해, 완성된 하나의 답변이 필요하면 ainvoke()를, 답변이 생성되는 과정을 실시간으로 보여주고 싶다면 astream()을 사용하면 됩니다.
MCP(Model Context Protocol) 서버의 도구와 연결했을 때 ainvoke()와 astream()의 결과가 다르게 나타나는 것은, 두 함수가 서버의 도구를 호출하고 응답을 처리하는 내부적인 실행 경로(Execution Path)가 다르기 때문입니다.
이는 LangChain 자체의 문제라기보다는 MCP 서버의 도구가 각 호출 방식에 어떻게 반응하도록 설계되었는지에 따라 발생하는 현상입니다. 주요 원인은 다음과 같습니다.
1. 도구의 내부 로직 및 상태 관리 차이
가장 큰 이유입니다. 도구(Tool)가 단일 응답을 생성하는 로직과 스트리밍 응답을 생성하는 로직을 다르게 구현했을 수 있습니다.
- ainvoke() (단일 호출): “이 요청을 처리해서 최종 결과물 하나를 만들어 줘” 라는 단일 작업으로 처리됩니다. 도구는 모든 계산과 처리를 완료한 후, 완결된 하나의 결과물을 반환합니다.
- astream() (스트리밍 호출): “결과가 생성되는 대로 즉시 보내줘” 라는 요청으로 처리됩니다. 도구는 최종 결과물을 만들기 위한 중간 단계의 결과물들을 실시간으로 생성하여 조각(chunk)으로 보냅니다.
이 과정에서 다음과 같은 차이가 발생할 수 있습니다.
- 상태 비저장 vs. 상태 저장: ainvoke는 한 번의 실행으로 끝나 상태를 유지할 필요가 없지만, astream은 스트림을 유지하는 동안 특정 상태(예: “지금까지 어떤 내용을 전송했는가?”)를 관리해야 할 수 있습니다. 이 상태 관리 로직의 차이가 최종 결과의 미묘한 차이를 만들 수 있습니다.
- 최종 결과 필터링/후처리: ainvoke는 완성된 전체 결과물을 놓고 최종적으로 검토하거나 수정하는 후처리(post-processing) 단계를 거칠 수 있습니다. 반면 astream은 각 조각을 즉시 전송해야 하므로 이러한 전체적인 후처리 단계가 생략되거나 다르게 적용될 수 있습니다.
2. 서버 측의 최적화 및 정책 차이
MCP 서버는 요청의 종류에 따라 다른 처리 방식을 사용할 수 있습니다.
- 다른 모델 또는 엔드포인트 사용: 서버는 일반 요청(ainvoke)과 스트리밍 요청(astream)을 처리하기 위해 내부적으로 다른 모델이나 API 엔드포인트를 호출할 수 있습니다. 스트리밍용 모델은 속도에 최적화되어 있어 일반 모델과 결과가 약간 다를 수 있습니다.
- 캐싱 전략: ainvoke의 최종 결과는 캐싱하기 용이하지만, astream의 각 조각은 캐싱 정책이 다를 수 있어 결과에 영향을 줄 수 있습니다.
3. 비결정성(Non-determinism)
만약 MCP 서버의 도구가 내부적으로 LLM(거대 언어 모델)을 사용한다면, 모델 자체의 비결정성이 원인일 수 있습니다.
- LLM은 temperature와 같은 파라미터 때문에 동일한 입력에 대해서도 호출할 때마다 약간씩 다른 결과를 생성할 수 있습니다. ainvoke()와 astream()은 서버 입장에서 별개의 호출로 인식될 수 있으므로, 각각의 호출에서 모델이 다른 결과물을 생성했을 가능성이 있습니다.
결론 및 확인 방법
결론적으로, ainvoke()와 astream()의 결과 차이는 두 호출 방식에 대응하는 MCP 서버 도구의 구현 방식 차이에서 비롯됩니다.
디버깅 및 확인 방법:
- MCP 서버/도구 문서 확인: 가장 먼저 해당 도구의 공식 문서에서 ainvoke와 astream (또는 일반/스트리밍 API) 호출 시 동작 차이에 대한 설명이 있는지 확인해야 합니다.
- 결과물 상세 비교: astream으로 받은 모든 조각(chunk)을 합친 최종 결과물과 ainvoke의 결과물을 텍스트 비교 도구를 사용해 정확히 어떤 부분이 다른지 분석해 보세요. (공백, 줄바꿈, 특정 단어 등)
- 가장 단순한 입력으로 테스트: 가장 간단하고 예측 가능한 입력값으로 두 함수를 각각 호출하여 결과 차이가 여전히 발생하는지 확인합니다. 이를 통해 문제의 원인이 복잡한 입력값 때문인지, 근본적인 처리 방식의 차이 때문인지 좁힐 수 있습니다.
답글 남기기