




데이터 분석 과정에서 시각화는 단순한 부가 기능이 아닌 필수적인 요소입니다. 복잡한 수치 데이터를 그래프나 차트로 표현하면 패턴, 추세, 이상치 등을 직관적으로 파악할 수 있습니다. Python과 Pandas는 강력한 데이터 시각화 도구를 제공하며, 이를 통해 전문적인 수준의 데이터 시각화가 가능합니다.
1. Matplotlib: 시각화의 기본기
Matplotlib은 Python에서 가장 기본적이고 널리 사용되는 시각화 라이브러리입니다. 다양한 그래프와 차트를 생성할 수 있으며, 세부적인 커스터마이징이 가능합니다.
참고로 Matplotlib 의 경우, 한글이 지원되지 않아 폰트를 지정해주는 것이 필요합니다. 윈도우에서는 “malgun.ttf” 혹은 “NanumBarunGothic.ttf” 등을 사용할 수 있습니다. 맥에서는 “AppleGothic.ttf” 등을 사용할 수 있습니다 .
plt.rcParams['font.family'] ='AppleGothic'
plt.rcParams['axes.unicode_minus'] =False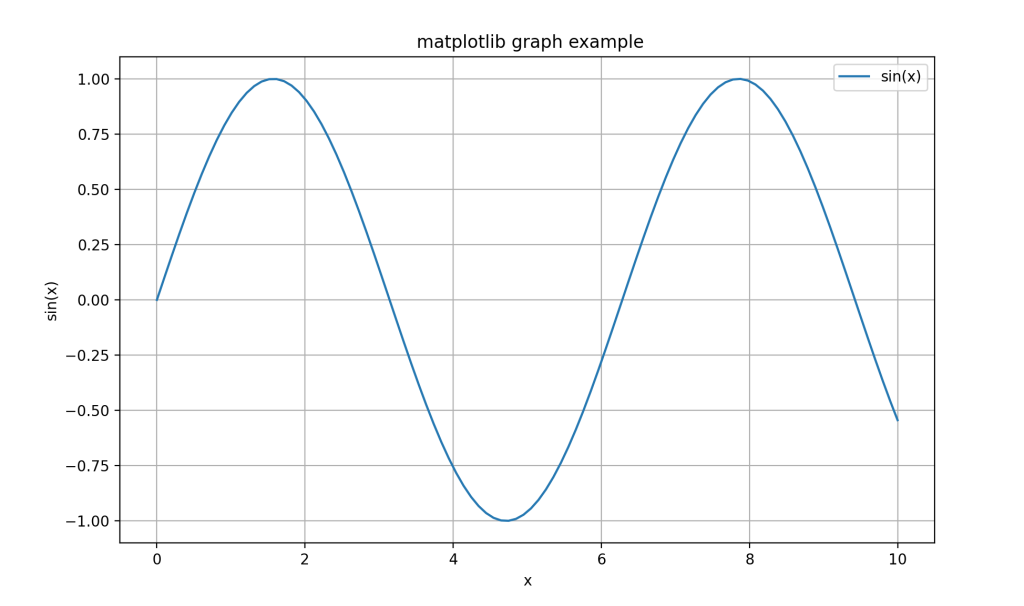
기본 사용법
import matplotlib.pyplot as plt
import numpy as np
# 데이터 준비
x = np.linspace(0, 10, 100)
y = np.sin(x)
# 그래프 생성
plt.figure(figsize=(10, 6))
plt.plot(x, y, label='sin(x)')
plt.title('사인 함수 그래프')
plt.xlabel('x')
plt.ylabel('sin(x)')
plt.legend()
plt.grid(True)
plt.show()
Pandas와 함께 사용하기
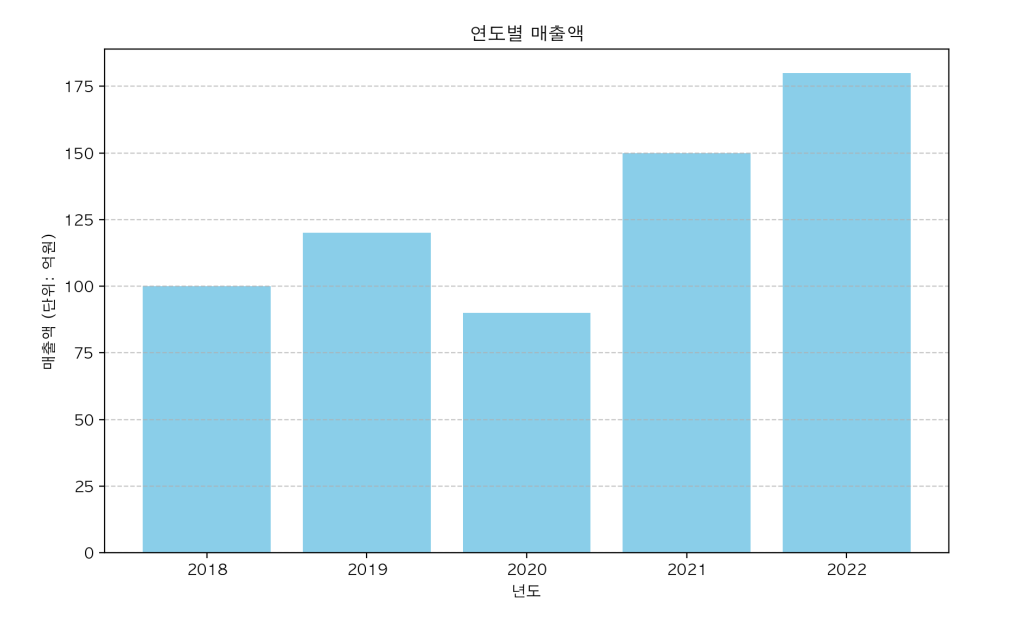
import pandas as pd
import matplotlib.pyplot as plt
# 샘플 데이터프레임 생성
df = pd.DataFrame({
'년도': [2018, 2019, 2020, 2021, 2022],
'매출액': [100, 120, 90, 150, 180]
})
# 막대 그래프 생성
plt.figure(figsize=(10, 6))
plt.bar(df['년도'], df['매출액'], color='skyblue')
plt.title('연도별 매출액')
plt.xlabel('년도')
plt.ylabel('매출액 (단위: 억원)')
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()
서브플롯 활용하기
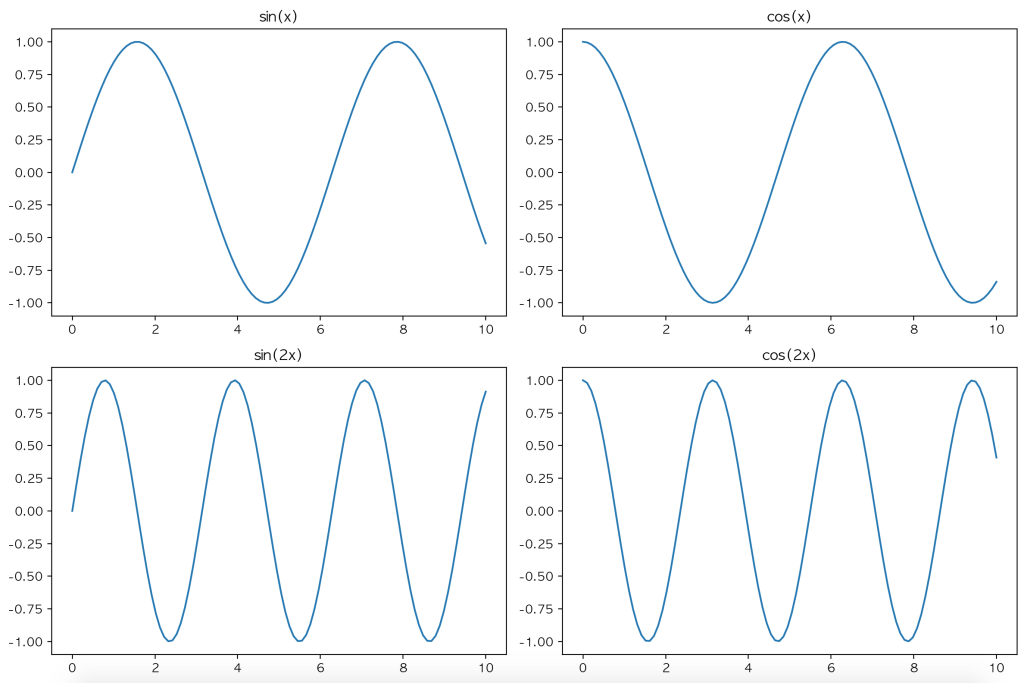
# 여러 그래프를 하나의 그림에 표시
plt.figure(figsize=(12, 8))
plt.subplot(2, 2, 1) # 2x2 그리드의 첫 번째 위치
plt.plot(x, np.sin(x))
plt.title('sin(x)')
plt.subplot(2, 2, 2) # 2x2 그리드의 두 번째 위치
plt.plot(x, np.cos(x))
plt.title('cos(x)')
plt.subplot(2, 2, 3) # 2x2 그리드의 세 번째 위치
plt.plot(x, np.sin(2*x))
plt.title('sin(2x)')
plt.subplot(2, 2, 4) # 2x2 그리드의 네 번째 위치
plt.plot(x, np.cos(2*x))
plt.title('cos(2x)')
plt.tight_layout() # 그래프 간 간격 자동 조정
plt.show()
2. Seaborn: 통계 데이터 시각화의 강자
Seaborn은 통계적 시각화에 특화된 라이브러리로, Matplotlib을 기반으로 하지만 더 높은 수준의 인터페이스를 제공합니다. 특히 복잡한 데이터셋의 분포와 관계를 시각화하는 데 탁월합니다.
참고로 load_dataset()으로 내장 데이터셋을 불러올 때, Python의 내장 루트에 SSL 인증서가 필요합니다. 아래 링크의 내용을 참고 바랍니다.
파이썬 내장루트 SSL 인증서 발행 : https://blog.choonzang.com/it/python/2456/
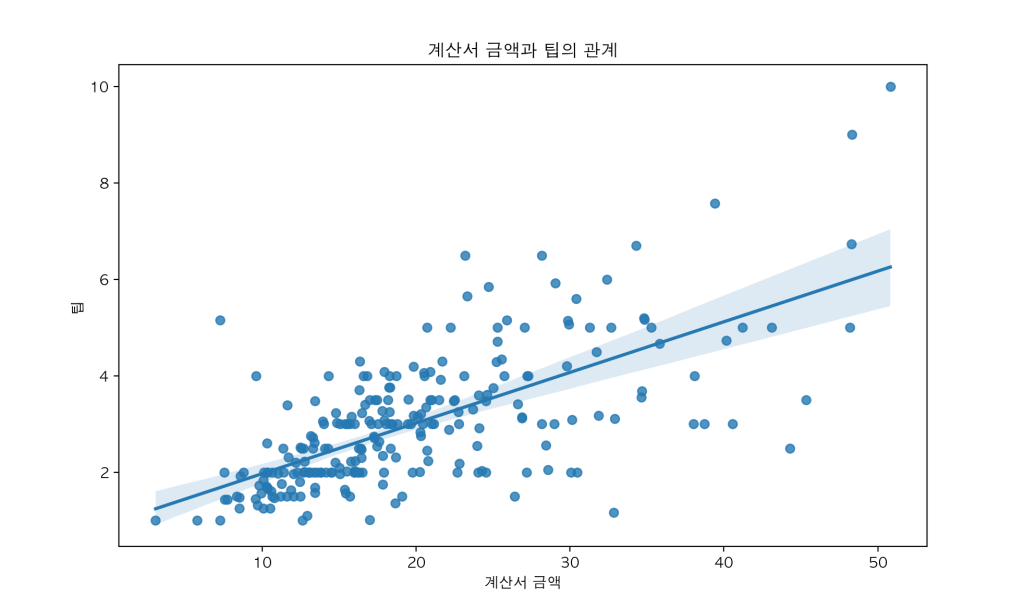
기본 사용법
import seaborn as sns
import matplotlib.pyplot as plt
# 내장 데이터셋 불러오기
tips = sns.load_dataset('tips')
# 산점도와 회귀선
plt.figure(figsize=(10, 6))
sns.regplot(x='total_bill', y='tip', data=tips)
plt.title('계산서 금액과 팁의 관계')
plt.xlabel('계산서 금액')
plt.ylabel('팁')
plt.show()
고급 시각화: 페어플롯
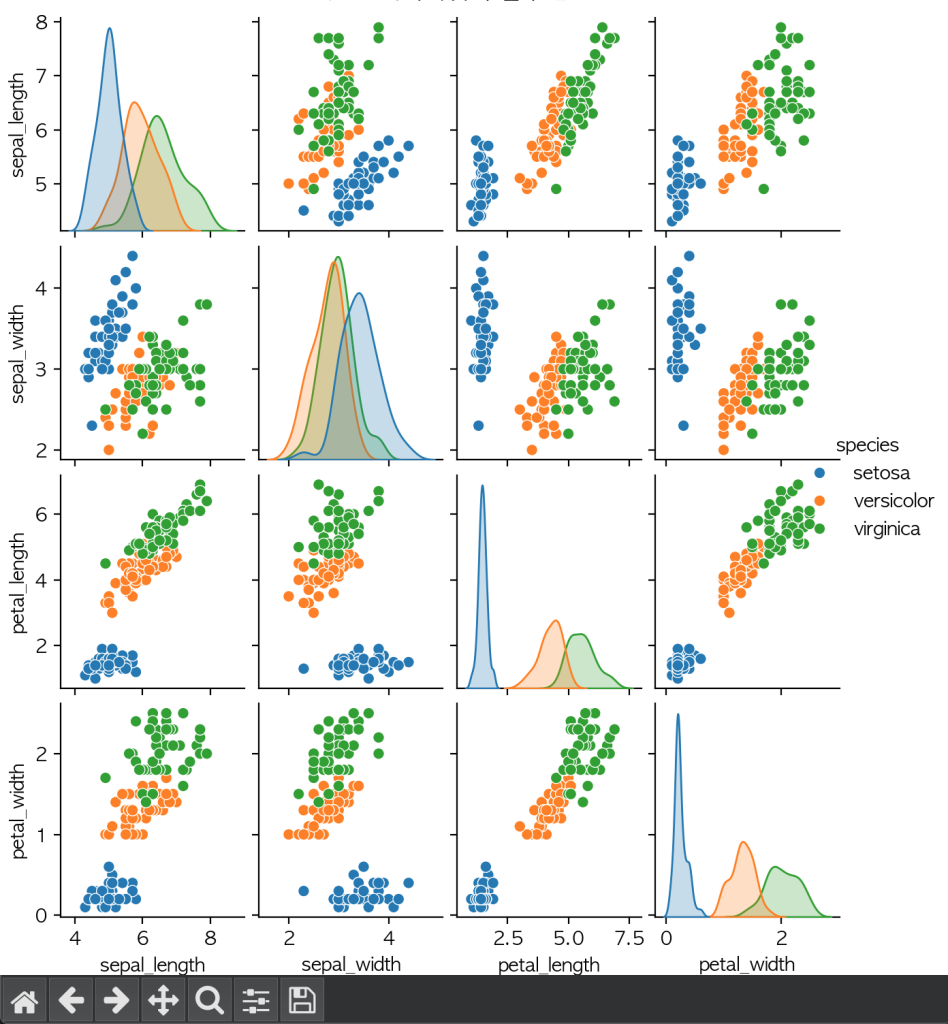
# 여러 변수 간의 관계를 한 번에 시각화
iris = sns.load_dataset('iris')
sns.pairplot(iris, hue='species')
plt.suptitle('붓꽃 데이터셋의 변수 간 관계', y=1.02)
plt.show()
히트맵으로 상관관계 표현하기
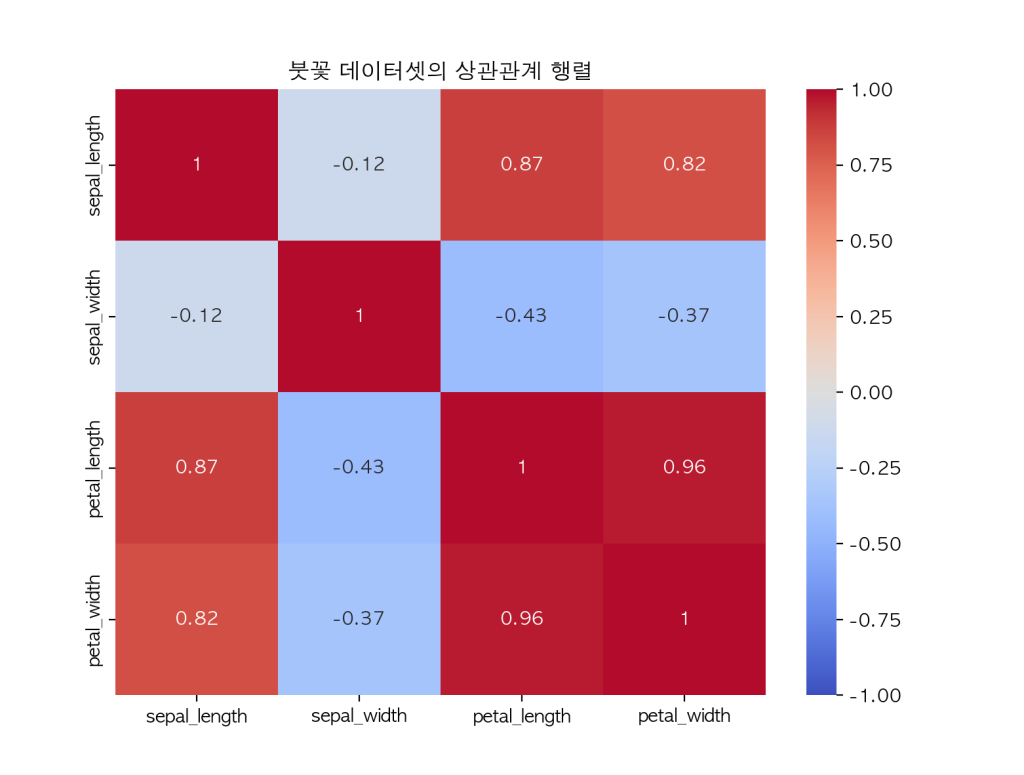
# 상관관계 계산 및 히트맵 생성
corr = iris.drop('species', axis=1).corr()
plt.figure(figsize=(8, 6))
sns.heatmap(corr, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('붓꽃 데이터셋의 상관관계 행렬')
plt.show()
3. Pandas 내장 시각화 기능
Pandas는 Matplotlib을 기반으로 한 간편한 시각화 기능을 내장하고 있어, 별도의 라이브러리 없이도 기본적인 시각화가 가능합니다.
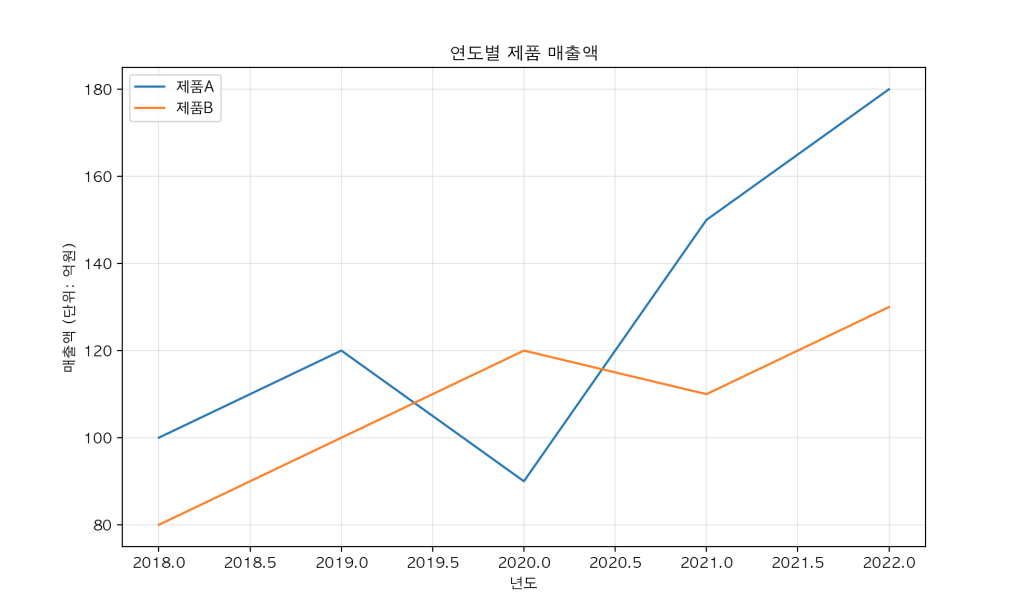
기본 그래프 그리기
# 데이터프레임으로부터 직접 선 그래프 생성
df = pd.DataFrame({
'년도': [2018, 2019, 2020, 2021, 2022],
'제품A': [100, 120, 90, 150, 180],
'제품B': [80, 100, 120, 110, 130]
}).set_index('년도')
df.plot(figsize=(10, 6), title='연도별 제품 매출액')
plt.ylabel('매출액 (단위: 억원)')
plt.grid(True, alpha=0.3)
plt.show()
다양한 그래프 유형
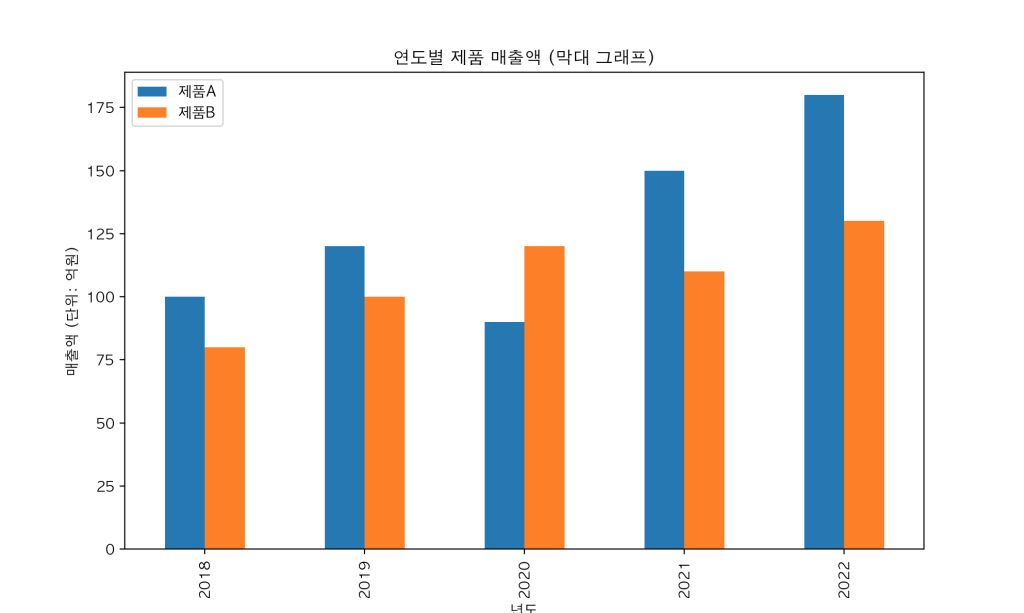
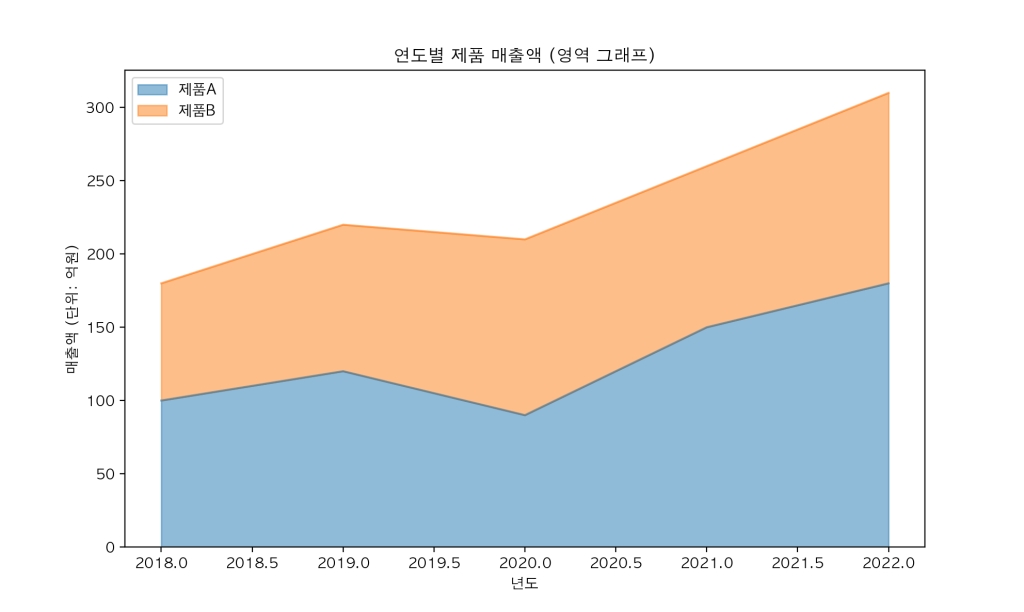
# 막대 그래프
df.plot(kind='bar', figsize=(10, 6), title='연도별 제품 매출액 (막대 그래프)')
plt.ylabel('매출액 (단위: 억원)')
plt.show()
# 누적 영역 그래프
df.plot(kind='area', alpha=0.5, figsize=(10, 6), title='연도별 제품 매출액 (영역 그래프)')
plt.ylabel('매출액 (단위: 억원)')
plt.show()
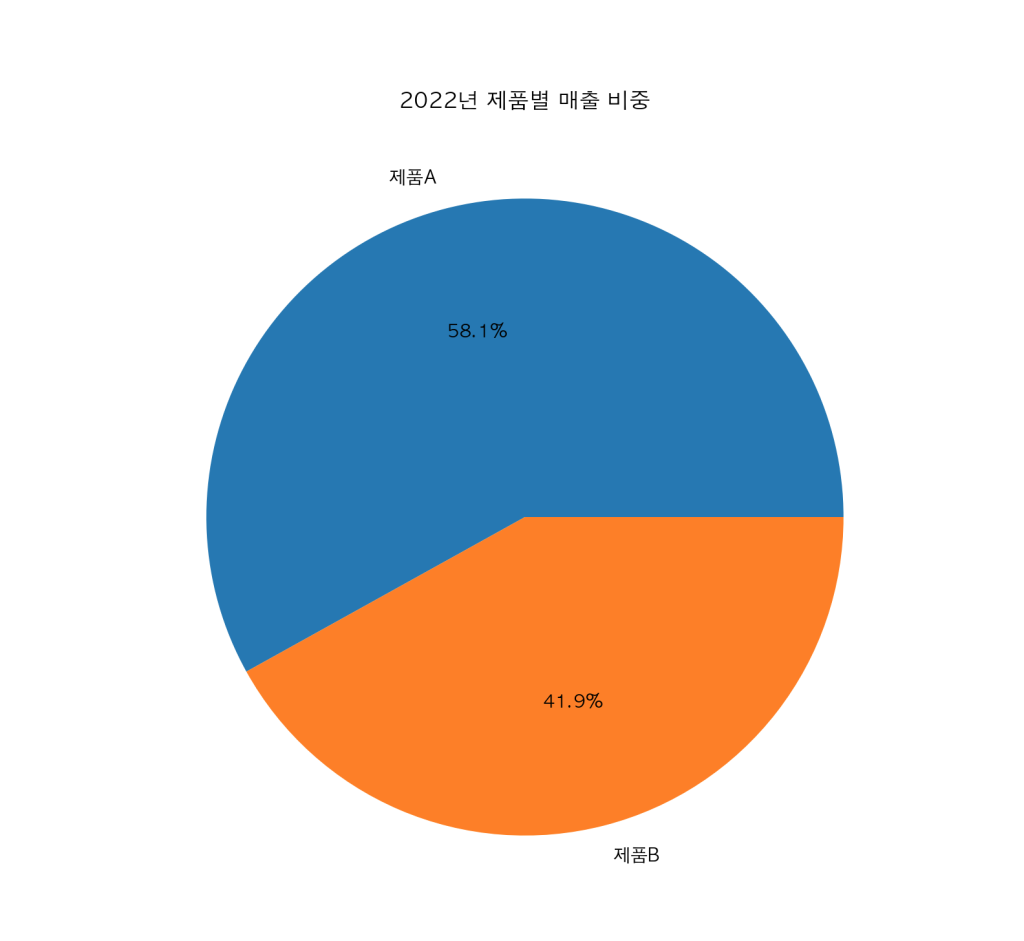
# 파이 차트 (2022년 데이터만 사용)
df.loc[2022].plot(kind='pie', figsize=(8, 8), autopct='%.1f%%', title='2022년 제품별 매출 비중')
plt.ylabel('')
plt.show()
4. Plotly: 인터랙티브 시각화의 혁명
Plotly는 인터랙티브한 시각화를 제공하는 라이브러리로, 웹 브라우저 기반 시각화에 적합합니다. 확대/축소, 호버 정보, 애니메이션 등 다양한 인터랙티브 기능을 지원합니다.
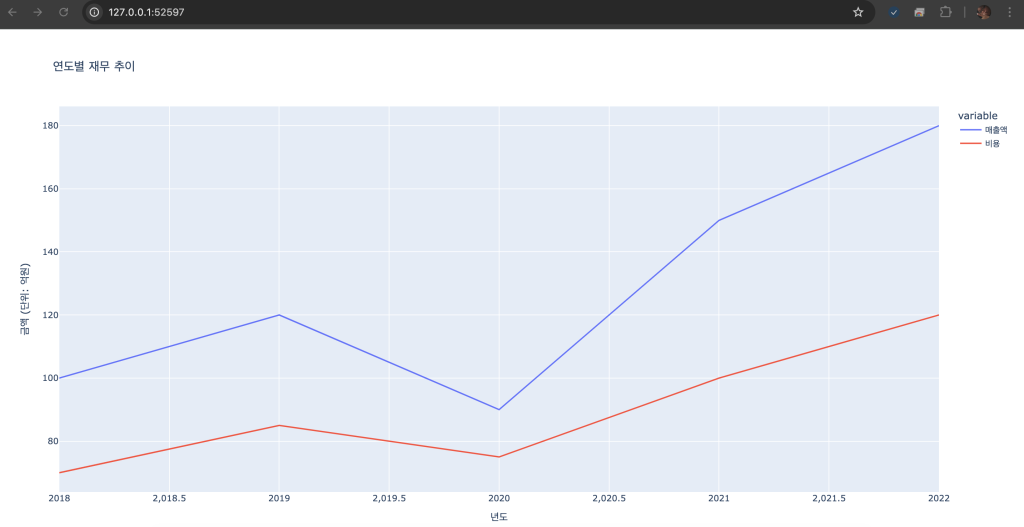
기본 사용법
import plotly.express as px
# 샘플 데이터프레임 생성
df = pd.DataFrame({
'년도': [2018, 2019, 2020, 2021, 2022],
'매출액': [100, 120, 90, 150, 180],
'비용': [70, 85, 75, 100, 120]
})
# 인터랙티브 선 그래프
fig = px.line(df, x='년도', y=['매출액', '비용'], title='연도별 재무 추이')
fig.update_layout(yaxis_title='금액 (단위: 억원)')
fig.show()
인터랙티브 산점도
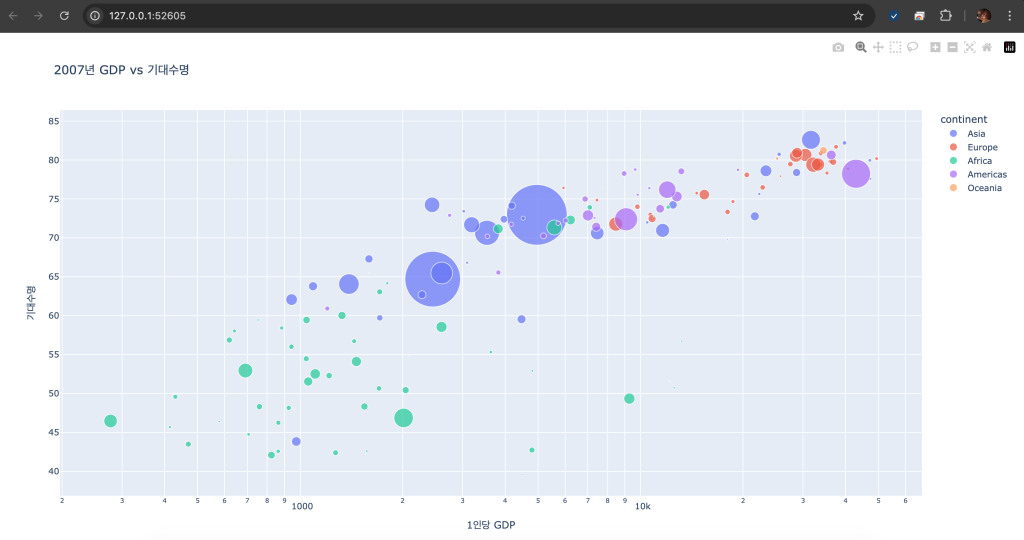
# 인터랙티브 산점도 (기포 차트)
gapminder = px.data.gapminder().query("year == 2007")
fig = px.scatter(gapminder, x='gdpPercap', y='lifeExp', size='pop', color='continent',
hover_name='country', log_x=True, size_max=60,
title='2007년 GDP vs 기대수명')
fig.update_layout(xaxis_title='1인당 GDP', yaxis_title='기대수명')
fig.show()
애니메이션 그래프
# 연도별 변화를 애니메이션으로 표현
gapminder = px.data.gapminder()
fig = px.scatter(gapminder, x='gdpPercap', y='lifeExp', size='pop', color='continent',
hover_name='country', log_x=True, size_max=60,
animation_frame='year', animation_group='country',
title='연도별 GDP vs 기대수명 변화')
fig.update_layout(xaxis_title='1인당 GDP', yaxis_title='기대수명')
fig.show()
5. Bokeh: 대용량 데이터 시각화
Bokeh는 대용량 데이터셋을 브라우저에서 효과적으로 렌더링할 수 있는 라이브러리입니다. 인터랙티브한 대시보드 구축에 적합합니다.
기본 사용법
from bokeh.plotting import figure, show
from bokeh.io import output_notebook
# 주피터 노트북에서 출력하기 위한 설정
output_notebook()
# 그래프 생성
p = figure(title="기본 선 그래프", x_axis_label='x', y_axis_label='y')
x = np.linspace(0, 4*np.pi, 100)
y = np.sin(x)
p.line(x, y, legend_label="sin(x)", line_width=2)
show(p)
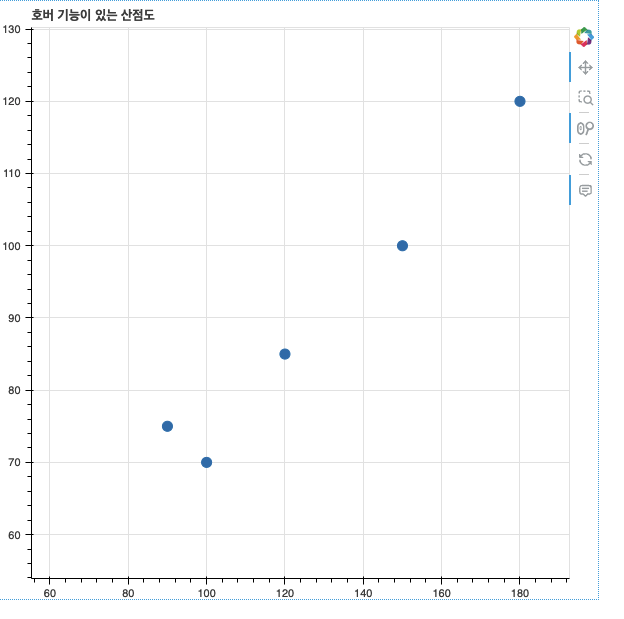
인터랙티브 요소 추가
from bokeh.models import HoverTool
# 호버 도구 추가
p = figure(title="호버 기능이 있는 산점도", tools="pan,wheel_zoom,box_zoom,reset")
p.scatter(df['매출액'], df['비용'], size=10)
hover = HoverTool()
hover.tooltips = [
("매출액", "@x억원"),
("비용", "@y억원")
]
p.add_tools(hover)
show(p)
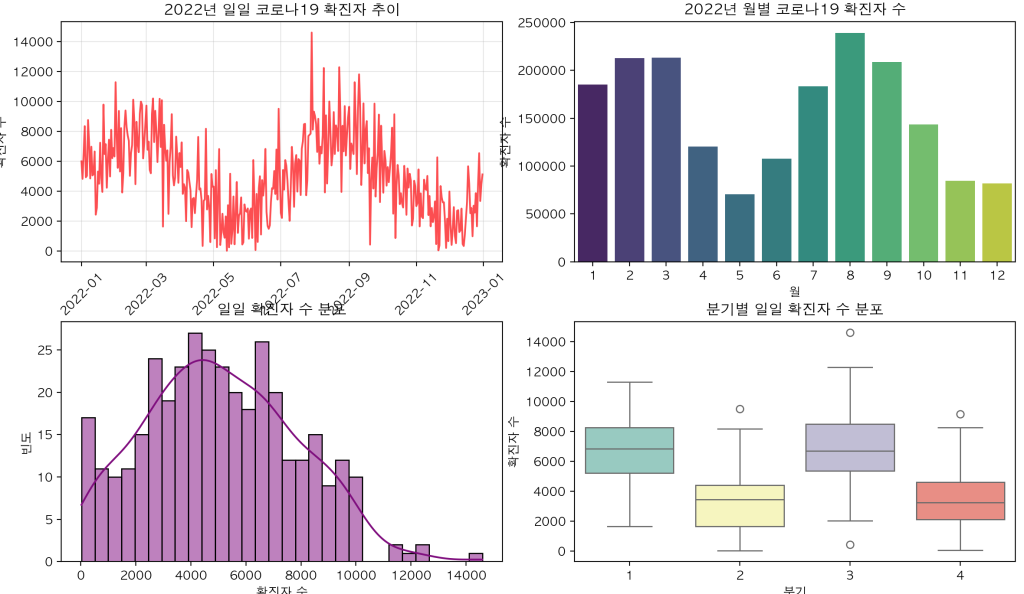
6. 실전 예제: 코로나19 데이터 시각화
이제 실제 데이터를 활용한 종합적인 시각화 예제를 살펴보겠습니다. 코로나19 확진자 데이터를 다양한 방법으로 시각화해 보겠습니다.
# 가상의 코로나19 일일 확진자 데이터 생성
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 생성
np.random.seed(42)
dates = pd.date_range(start='2022-01-01', end='2022-12-31')
daily_cases = np.random.normal(loc=5000, scale=2000, size=len(dates))
daily_cases = np.abs(daily_cases + np.sin(np.arange(len(dates)) / 30) * 3000)
daily_cases = daily_cases.astype(int)
covid_df = pd.DataFrame({
'날짜': dates,
'일일확진자': daily_cases
})
# 월별 데이터 추출
covid_df['월'] = covid_df['날짜'].dt.month
monthly_cases = covid_df.groupby('월')['일일확진자'].sum().reset_index()
# 종합 시각화
plt.figure(figsize=(15, 10))
# 1. 일일 확진자 추이
plt.subplot(2, 2, 1)
plt.plot(covid_df['날짜'], covid_df['일일확진자'], color='red', alpha=0.7)
plt.title('2022년 일일 코로나19 확진자 추이')
plt.ylabel('확진자 수')
plt.grid(True, alpha=0.3)
plt.xticks(rotation=45)
# 2. 월별 총 확진자 수
plt.subplot(2, 2, 2)
sns.barplot(x='월', y='일일확진자', data=monthly_cases, palette='viridis')
plt.title('2022년 월별 코로나19 확진자 수')
plt.xlabel('월')
plt.ylabel('확진자 수')
# 3. 일일 확진자 분포
plt.subplot(2, 2, 3)
sns.histplot(covid_df['일일확진자'], kde=True, bins=30, color='purple')
plt.title('일일 확진자 수 분포')
plt.xlabel('확진자 수')
plt.ylabel('빈도')
# 4. 박스플롯
plt.subplot(2, 2, 4)
covid_df['분기'] = (covid_df['월'] - 1) // 3 + 1
sns.boxplot(x='분기', y='일일확진자', data=covid_df, palette='Set3')
plt.title('분기별 일일 확진자 수 분포')
plt.xlabel('분기')
plt.ylabel('확진자 수')
plt.tight_layout()
plt.show()
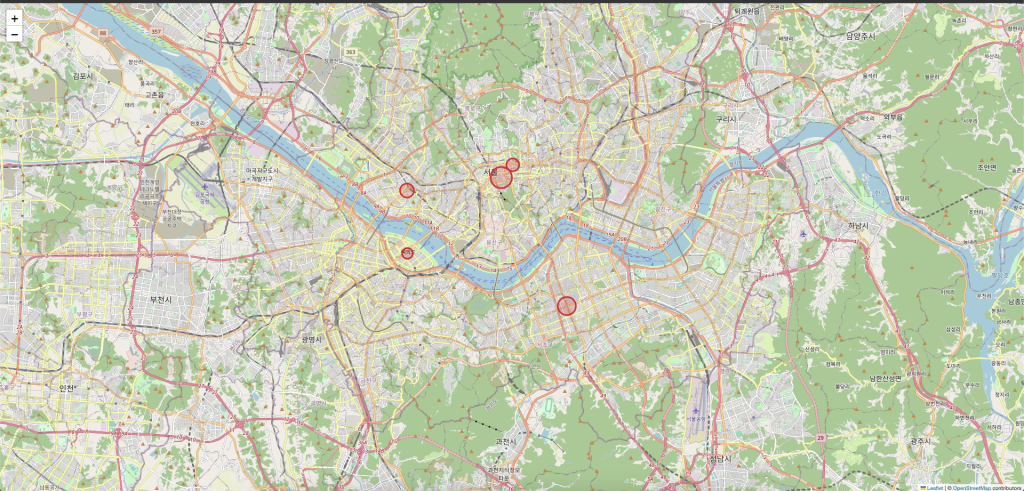
7. 고급 기법: 지리적 데이터 시각화
지리적 데이터의 시각화는 특히 강력한 인사이트를 제공할 수 있습니다. 여기서는 Folium을 사용한 지도 시각화 방법을 알아보겠습니다.
이것은 최종 결과 파일을 html로 생성 및 저장하도록 하고 있습니다.
import folium
# 서울시 중심 좌표
seoul_center = [37.5665, 126.9780]
# 기본 지도 생성
m = folium.Map(location=seoul_center, zoom_start=11)
# 가상의 데이터: 서울시 주요 지역별 방문자 수
locations = [
{'name': '강남역', 'lat': 37.4980, 'lon': 127.0273, 'visitors': 15000},
{'name': '홍대입구역', 'lat': 37.5570, 'lon': 126.9244, 'visitors': 12000},
{'name': '명동', 'lat': 37.5636, 'lon': 126.9851, 'visitors': 18000},
{'name': '여의도', 'lat': 37.5249, 'lon': 126.9247, 'visitors': 9000},
{'name': '종로', 'lat': 37.5701, 'lon': 126.9925, 'visitors': 11000}
]
# 방문자 수에 따라 원의 크기와 색상 조정
for loc in locations:
folium.Circle(
location=[loc['lat'], loc['lon']],
radius=loc['visitors'] / 30, # 방문자 수에 비례하는 원 크기
popup=f"{loc['name']}: {loc['visitors']}명",
color='crimson',
fill=True,
fill_color='crimson'
).add_to(m)
# 지도를 HTML 파일로 저장
m.save('seoul_visitors_map.html')
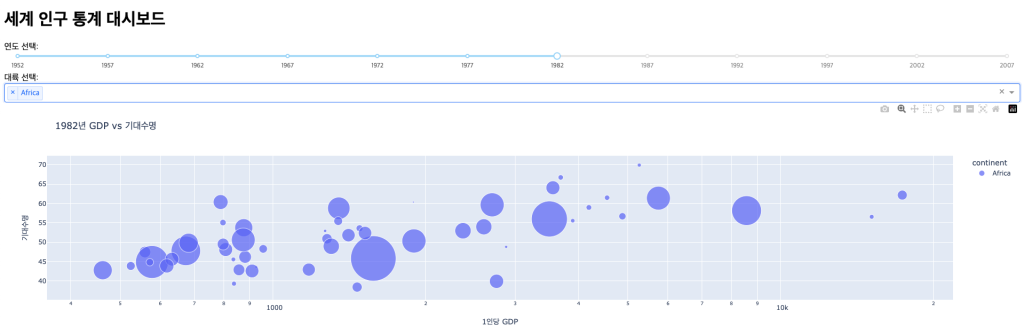
8. 대시보드 구축: Dash로 인터랙티브 앱 만들기
마지막으로, Dash를 사용하여 인터랙티브한 데이터 대시보드를 구축하는 방법을 알아보겠습니다.
from dash import Dash, dcc, html, Input, Output
import plotly.express as px
# 샘플 데이터
df = px.data.gapminder()
# Dash 앱 초기화
app = Dash(__name__)
# 레이아웃 정의
app.layout = html.Div([
html.H1("세계 인구 통계 대시보드"),
html.Div([
html.Label("연도 선택:"),
dcc.Slider(
id='year-slider',
min=df['year'].min(),
max=df['year'].max(),
step=5,
value=df['year'].min(),
marks={str(year): str(year) for year in df['year'].unique()}
),
]),
html.Div([
html.Label("대륙 선택:"),
dcc.Dropdown(
id='continent-dropdown',
options=[{'label': i, 'value': i} for i in df['continent'].unique()],
value=None,
multi=True
),
]),
dcc.Graph(id='gdp-life-scatter')
])
# 콜백 정의
@app.callback(
Output('gdp-life-scatter', 'figure'),
[Input('year-slider', 'value'),
Input('continent-dropdown', 'value')]
)
def update_graph(selected_year, selected_continents):
filtered_df = df[df.year == selected_year]
if selected_continents:
filtered_df = filtered_df[filtered_df.continent.isin(selected_continents)]
fig = px.scatter(
filtered_df,
x="gdpPercap",
y="lifeExp",
size="pop",
color="continent",
hover_name="country",
log_x=True,
size_max=60,
title=f"{selected_year}년 GDP vs 기대수명"
)
fig.update_layout(
xaxis_title="1인당 GDP",
yaxis_title="기대수명"
)
return fig
# 서버 실행
if __name__ == '__main__':
app.run_server(debug=True)
마치며
Python과 Pandas를 활용한 데이터 시각화는 단순한 차트 생성을 넘어 데이터에 숨겨진 가치 있는 인사이트를 발견하는 강력한 도구입니다. 이 글에서 소개한 다양한 라이브러리와 기법을 활용하여 여러분의 데이터를 더욱 효과적으로 분석하고 시각화해보세요.
시각화는 데이터 과학의 여정에서 필수적인 단계이며, 적절한 시각화는 복잡한 분석 결과를 누구나 이해할 수 있는 스토리로 변환하는 마법과 같습니다. 다양한 시각화 방법을 실험하고 자신만의 데이터 시각화 스타일을 개발해 나가길 바랍니다.
이후에 파이썬을 이용한 데이터 분석 케이스가 있다면, 활용 도구로 언급한 포스트를 추가하도록 하겠습니다.
답글 남기기