




웹 크롤링과 스크래핑은 데이터 수집에 있어 필수적인 기술입니다. 특히 AI와 LLM(Large Language Model) 시대에 접어들면서 이러한 기술의 중요성은 더욱 커지고 있습니다. 이런 상황에서 Crawl4AI는 AI 친화적인 웹 크롤링 솔루션으로 주목받고 있습니다.
Crawl4AI(https://docs.crawl4ai.com/)는 GitHub(https://github.com/unclecode/crawl4ai)에서 가장 트렌디한 리포지토리 중 하나로, 활발한 커뮤니티에 의해 지속적으로 관리되고 있습니다. 이 도구는 대규모 언어 모델, AI 에이전트 및 데이터 파이프라인을 위해 특별히 설계된 초고속 웹 크롤링 기능을 제공합니다.
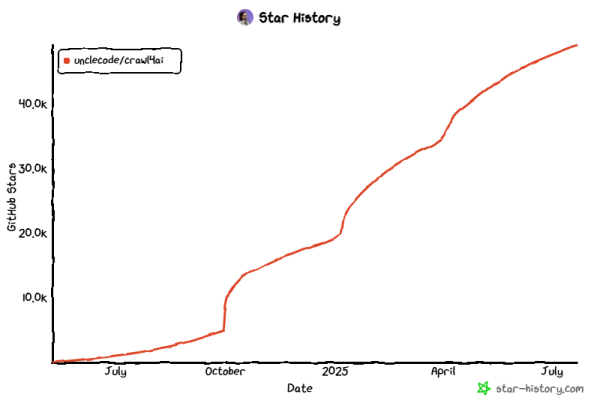
최근 RAG 시스템 구현을 위해서 웹사이트의 정보 또한 RAG 에 Ingest해서 결과를 확인해보는 작업을 진행하였는데, 웹사이트 크롤러를 통해서 사이트의 뎁스를 넘어, 정해진 범위의 페이지들을 스크랩하는 라이브러리로써 결과는 매우 만족스러웠으며, 오픈소스라는 장점도 Plus 하는 것 같습니다.
Crawl4AI의 주요 특징
- 깔끔한 마크다운 생성: RAG 파이프라인이나 LLM 직접 입력에 완벽한 형태로 데이터 제공
- 구조화된 추출: CSS, XPath 또는 LLM 기반 추출을 통한 반복 패턴 파싱
- 고급 브라우저 제어: 훅, 프록시, 스텔스 모드, 세션 재사용 등 세밀한 제어 가능
- 고성능: 병렬 크롤링, 청크 기반 추출로 실시간 사용 사례 지원
- 오픈 소스: API 키나 유료 장벽 없이 누구나 데이터에 접근 가능
최신 기능: 적응형 웹 크롤링
Crawl4AI는 이제 언제 중지해야 할지 알 수 있는 지능형 적응 크롤링 기능을 제공합니다. 고급 정보 수집 알고리즘을 사용하여 쿼리에 답변하기에 충분한 정보가 수집되었는지 판단합니다.
기본 설치
Crawl4AI의 설치는 pip를 통해 간단하게 할 수 있습니다:
pip install crawl4ai
이 명령어는 Crawl4AI의 핵심 라이브러리와 필수 의존성을 설치합니다. 이 단계에서는 transformers나 PyTorch와 같은 고급 기능은 포함되지 않습니다.
초기 설정
설정 명령어 실행
설치 후, 다음 명령어를 실행하여 초기 설정을 완료합니다:
crawl4ai-setup
이 명령어는 다음과 같은 작업을 수행합니다:
- 필요한 Playwright 브라우저(Chromium, Firefox 등) 설치 또는 업데이트
- OS 레벨 검사(예: Linux에서 누락된 라이브러리 확인)
- 크롤링을 위한 환경 준비 상태 확인
진단 실행
선택적으로 진단 명령어를 실행하여 모든 것이 제대로 작동하는지 확인할 수 있습니다:
crawl4ai-doctor
이 명령어는 다음을 확인합니다:
- Python 버전 호환성 검사
- Playwright 설치 확인
- 환경 변수 또는 라이브러리 충돌 검사
문제가 발생하면 제안된 해결책(예: 추가 시스템 패키지 설치)을 따른 후 crawl4ai-setup을 다시 실행하세요.
고급 설치 (선택사항)
주의: 정말 필요한 경우에만 이러한 기능을 설치하세요. 대용량 모델을 포함한 더 큰 의존성이 추가되어 디스크 사용량과 메모리 로드가 크게 증가할 수 있습니다.
Torch, Transformers 또는 모든 기능
텍스트 클러스터링(Torch):
pip install crawl4ai[torch]
crawl4ai-setup
PyTorch 기반 기능(예: 코사인 유사도 또는 고급 의미론적 청킹)을 설치합니다.
Transformers:
pip install crawl4ai[transformer]
crawl4ai-setup\
Hugging Face 기반 요약 또는 생성 전략을 추가합니다.
모든 기능:
pip install crawl4ai[all]
crawl4ai-setup
모델 사전 다운로드 (선택사항)
crawl4ai-download-models
이 단계는 필요한 경우 대형 모델을 로컬에 캐시합니다. 워크플로우에 필요한 경우에만 수행하세요.
Docker
Crawl4AI는 테스트를 위한 임시 Docker 접근 방식을 제공합니다. 이는 안정적이지 않으며 향후 릴리스에서 변경될 수 있습니다. 2025년 1분기에 주요 Docker 개편이 계획되어 있습니다. 그래도 시도해보고 싶다면:
docker pull unclecode/crawl4ai:basic
docker run -p 11235:11235 unclecode/crawl4ai:basic
그런 다음 http://localhost:11235/crawl로 POST 요청을 보내 크롤링을 수행할 수 있습니다. 새로운 Docker 접근 방식이 준비될 때까지(2025년 1월 또는 2월 예정) 프로덕션 사용은 권장되지 않습니다.
로컬 서버 모드 (레거시)
일부 이전 문서에서는 Crawl4AI를 로컬 서버로 실행하는 방법을 언급합니다. 이 접근 방식은 새로운 Docker 기반 프로토타입과 향후 안정적인 서버 릴리스로 부분적으로 대체되었습니다. 실험은 가능하지만 주요 변경 사항이 예상됩니다. 공식 로컬 서버 지침은 새로운 Docker 아키텍처가 완성되면 제공될 예정입니다.
주요 함수 및 사용 방법
AsyncWebCrawler()
AsyncWebCrawler는 Crawl4AI의 핵심 클래스로, 비동기 방식으로 웹 크롤링을 수행합니다.
from crawl4ai import AsyncWebCrawler
# 기본 사용법
async with AsyncWebCrawler() as crawler:
# 크롤러 인스턴스를 사용하여 작업 수행
result = await crawler.arun(url="https://example.com")
# 고급 설정으로 초기화
async with AsyncWebCrawler(
browser_config=BrowserConfig(
headless=True,
stealth_mode=True,
timeout=30
)
) as crawler:
# 크롤링 수행
result = await crawler.arun(url="https://example.com")
arun()
arun() 메서드는 비동기적으로 웹 크롤링을 실행하고 결과를 반환합니다.
async def main():
async with AsyncWebCrawler() as crawler:
# 기본 사용법
result = await crawler.arun(url="https://example.com")
# 고급 옵션 사용
result = await crawler.arun(
url="https://example.com",
max_pages=5, # 최대 크롤링할 페이지 수
follow_links=True, # 링크 따라가기 활성화
extract_images=True, # 이미지 추출 활성화
wait_for_selector=".content", # 특정 요소가 로드될 때까지 대기
scroll_to_bottom=True # 페이지 하단까지 스크롤
)
# 결과 활용
print(result.markdown) # 마크다운 형식의 결과
print(result.html) # HTML 형식의 결과
print(result.text) # 일반 텍스트 형식의 결과
print(result.metadata) # 메타데이터
import asyncio
asyncio.run(main())
BrowserConfig()
BrowserConfig는 브라우저의 동작을 세밀하게 제어할 수 있는 설정 클래스입니다.
class BrowserConfig:
def __init__(
browser_type="chromium",
headless=True,
proxy_config=None,
viewport_width=1080,
viewport_height=600,
verbose=True,
use_persistent_context=False,
user_data_dir=None,
cookies=None,
headers=None,
user_agent=None,
text_mode=False,
light_mode=False,
extra_args=None,
# ... other advanced parameters omitted here
):
...
from crawl4ai import AsyncWebCrawler, BrowserConfig
async def main():
# 브라우저 설정 구성
browser_config = BrowserConfig(
headless=True, # 헤드리스 모드 (UI 없음)
stealth_mode=True, # 스텔스 모드 (봇 감지 방지)
timeout=30, # 타임아웃 (초)
user_agent="Custom User Agent", # 사용자 정의 User-Agent
viewport={"width": 1920, "height": 1080}, # 뷰포트 크기
proxy="http://user:pass@proxy.example.com:8080", # 프록시 설정
cookies=[{"name": "session", "value": "abc123", "domain": "example.com"}] # 쿠키 설정
)
# 설정된 브라우저 구성으로 크롤러 초기화
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
result = await crawler.arun(url="https://example.com")
print(result.markdown)
asyncio.run(main())
CrawlResult Class
CrawlResult는 크롤링 결과를 다양한 형식으로 제공하는 클래스입니다.
class CrawlResult(BaseModel):
url: str
html: str
success: bool
cleaned_html: Optional[str] = None
fit_html: Optional[str] = None # Preprocessed HTML optimized for extraction
media: Dict[str, List[Dict]] = {}
links: Dict[str, List[Dict]] = {}
downloaded_files: Optional[List[str]] = None
screenshot: Optional[str] = None
pdf : Optional[bytes] = None
mhtml: Optional[str] = None
markdown: Optional[Union[str, MarkdownGenerationResult]] = None
extracted_content: Optional[str] = None
metadata: Optional[dict] = None
error_message: Optional[str] = None
session_id: Optional[str] = None
response_headers: Optional[dict] = None
status_code: Optional[int] = None
ssl_certificate: Optional[SSLCertificate] = None
dispatch_result: Optional[DispatchResult] = None
...
추출한 HTML을 원하는 정보로 제출받기 위해 위 클래스를 이용하여 사전에 정의된 데이터들을 가져올 수 있게 됩니다.
실용적인 예제: 뉴스 기사 크롤링
다음은 뉴스 웹사이트에서 기사를 크롤링하고 마크다운 형식으로 저장하는 실제 예제입니다.
import asyncio
import os
from crawl4ai import AsyncWebCrawler, BrowserConfig
async def crawl_news_articles(urls):
# 브라우저 설정 - 스텔스 모드 활성화
config = BrowserConfig(
headless=True,
stealth_mode=True,
timeout=60
)
# 결과 저장할 디렉토리 생성
os.makedirs("news_articles", exist_ok=True)
async with AsyncWebCrawler(browser_config=config) as crawler:
for i, url in enumerate(urls):
try:
print(f"크롤링 중: {url}")
# 기사 크롤링 - 이미지 포함
result = await crawler.arun(
url=url,
extract_images=True,
wait_for_selector="article, .article, .content", # 일반적인 뉴스 기사 선택자
scroll_to_bottom=True
)
# 파일명 생성 (URL에서 유효한 파일명 추출)
filename = f"news_articles/article_{i+1}.md"
# 마크다운 파일로 저장
with open(filename, "w", encoding="utf-8") as f:
# 제목 추가
if result.metadata.get("title"):
f.write(f"# {result.metadata.get('title')}\n\n")
# 출처 URL 추가
f.write(f"출처: {url}\n\n")
# 본문 내용 저장
f.write(result.markdown)
print(f"저장 완료: {filename}")
except Exception as e:
print(f"크롤링 실패 ({url}): {str(e)}")
# 크롤링할 뉴스 URL 목록
news_urls = [
"https://example-news.com/article1",
"https://example-news.com/article2",
"https://example-news.com/article3"
]
# 실행
asyncio.run(crawl_news_articles(news_urls))
적응형 크롤링 예제
Crawl4AI의 최신 기능인 적응형 크롤링을 활용하는 예제입니다.
import asyncio
from crawl4ai import AsyncWebCrawler
async def adaptive_crawl_example():
async with AsyncWebCrawler() as crawler:
# 적응형 크롤링 활성화
result = await crawler.arun(
url="https://example.com",
follow_links=True,
adaptive_crawling=True,
query="이 웹사이트의 주요 제품과 가격은 무엇인가요?",
max_pages=20 # 최대 페이지 수 제한 (선택 사항)
)
print("크롤링된 페이지 수:", len(result.crawled_pages))
print("수집된 정보:")
print(result.markdown)
asyncio.run(adaptive_crawl_example())
결론
Crawl4AI는 AI 시대에 맞춰 설계된 강력한 웹 크롤링 도구입니다. 특히 LLM과의 통합을 염두에 두고 개발되어, 데이터 수집부터 AI 모델 입력까지의 과정을 매끄럽게 연결해줍니다.
오픈소스로 제공되며 다양한 설정 옵션과 고급 기능을 통해 사용자의 필요에 맞게 유연하게 조정할 수 있습니다. AsyncWebCrawler, arun(), BrowserConfig, CrawlResult 등의 핵심 함수와 클래스를 활용하면 복잡한 웹 크롤링 작업도 효율적으로 수행할 수 있습니다.
복잡한 웹페이지의 모든 소스를 가져와서, 필요한 형태(링크, 미디어, markdown, html 외 기타의 메타데이터들)들을 가져와서 원하는 요소들만 추출하여, python을 통해 제어할수 있는 매우 매력적인 class의 function들로 인해서, 시간을 가지고 한번 들여다보면, 충분한 매력을 느낄만한 라이브러리라는 말씀 드릴수 있습니다.
최근 이 라이브러리를 활용해서 크롤러를 만들어보았는데, 기회가 되면 한번 정리해서 포스팅해보도록 하겠습니다.
답글 남기기