




자연어 처리(NLP)는 컴퓨터가 인간의 언어를 이해하고 처리할 수 있게 하는 인공지능의 한 분야입니다. 파이썬에서는 NLTK(Natural Language Toolkit)라는 강력한 라이브러리를 통해 다양한 자연어 처리 작업을 수행할 수 있습니다. 이 글에서는 NLTK의 주요 기능과 실제 활용 사례에 대해 알아보겠습니다.
NLTK란?
NLTK는 2001년 펜실베니아 대학교에서 교육 목적으로 개발된 오픈 소스 파이썬 라이브러리입니다. 텍스트 처리를 위한 50개 이상의 말뭉치(corpus)와 어휘 자원을 제공하며, 분류, 토큰화, 형태소 분석, 태깅, 구문 분석 등 다양한 자연어 처리 기능을 지원합니다.
NLTK 설치하기
NLTK는 pip를 통해 쉽게 설치할 수 있습니다:
pip install nltk
설치 후에는 필요한 데이터를 다운로드해야 합니다:
import nltk
nltk.download('popular') # 인기 있는 패키지들을 다운로드
NLTK의 주요 기능
1. 토큰화(Tokenization)
토큰화는 텍스트를 작은 단위(토큰)로 나누는 과정입니다. NLTK는 문장 토큰화와 단어 토큰화를 모두 지원합니다.
import nltk
from nltk.tokenize import sent_tokenize, word_tokenize
text = "NLTK는 자연어 처리를 위한 파이썬 라이브러리입니다. 다양한 기능을 제공합니다."
# 문장 토큰화
sentences = sent_tokenize(text)
print(sentences)
# ['NLTK는 자연어 처리를 위한 파이썬 라이브러리입니다.', '다양한 기능을 제공합니다.']
# 단어 토큰화
words = word_tokenize(sentences[0])
print(words)
# ['NLTK는', '자연어', '처리를', '위한', '파이썬', '라이브러리입니다', '.']
2. 불용어 제거(Stopwords Removal)
불용어는 분석에 큰 의미가 없는 일반적인 단어들(예: ‘the’, ‘a’, ‘an’ 등)입니다. NLTK는 여러 언어의 불용어 목록을 제공합니다.
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
text = "This is an example showing the removal of stopwords"
words = word_tokenize(text)
filtered_words = [word for word in words if word.lower() not in stop_words]
print(filtered_words)
# ['This', 'example', 'showing', 'removal', 'stopwords']
3. 어간 추출(Stemming)과 표제어 추출(Lemmatization)
어간 추출은 단어의 접미사를 제거하여 어간을 찾는 과정이고, 표제어 추출은 단어의 기본형을 찾는 과정입니다.
from nltk.stem import PorterStemmer, WordNetLemmatizer
nltk.download('wordnet')
# 어간 추출
stemmer = PorterStemmer()
print(stemmer.stem('running')) # 'run'
print(stemmer.stem('better')) # 'better'
# 표제어 추출
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('running', pos='v')) # 'run'
print(lemmatizer.lemmatize('better', pos='a')) # 'good'
4. 품사 태깅(POS Tagging)
품사 태깅은 문장 내 각 단어의 품사(명사, 동사, 형용사 등)를 식별하는 과정입니다.
import nltk
from nltk import pos_tag
from nltk.tokenize import word_tokenize
nltk.download('averaged_perceptron_tagger')
text = "NLTK is a powerful Python library for NLP"
tokens = word_tokenize(text)
tagged = pos_tag(tokens)
print(tagged)
# [('NLTK', 'NNP'), ('is', 'VBZ'), ('a', 'DT'), ('powerful', 'JJ'),
# ('Python', 'NNP'), ('library', 'NN'), ('for', 'IN'), ('NLP', 'NNP')]
5. 개체명 인식(Named Entity Recognition)
개체명 인식은 텍스트에서 인물, 조직, 장소 등과 같은 개체를 식별하는 과정입니다.
import nltk
from nltk import ne_chunk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
nltk.download('maxent_ne_chunker')
nltk.download('words')
text = "Apple is looking at buying U.K. startup for $1 billion"
tokens = word_tokenize(text)
tagged = pos_tag(tokens)
entities = ne_chunk(tagged)
print(entities)
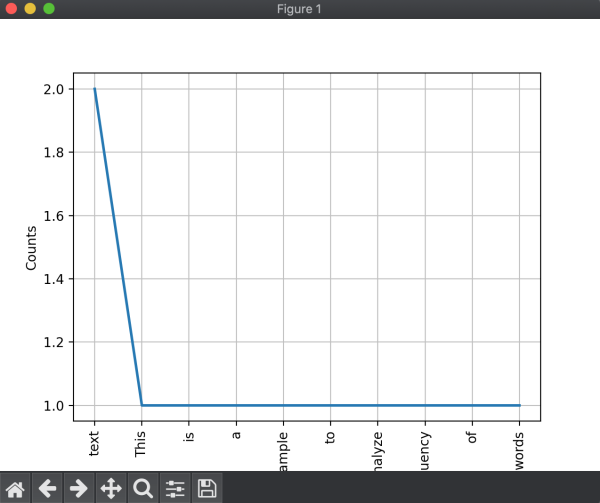
6. 빈도 분석(Frequency Analysis)
NLTK는 텍스트 내 단어 빈도를 분석하는 도구를 제공합니다.
from nltk.probability import FreqDist
from nltk.tokenize import word_tokenize
text = "This is a sample text to analyze frequency of words in this text"
words = word_tokenize(text)
fdist = FreqDist(words)
print(fdist.most_common(3)) # [('text', 2), ('this', 2), ('is', 1)]
# 빈도 분포 시각화
import matplotlib.pyplot as plt
fdist.plot(10, cumulative=False)
plt.show()
NLTK의 실제 활용 사례
1. 감정 분석(Sentiment Analysis)
영화 리뷰나 제품 리뷰의 감정(긍정/부정)을 분석하는 데 NLTK를 활용할 수 있습니다.
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
nltk.download('vader_lexicon')
sia = SentimentIntensityAnalyzer()
reviews = [
"This movie was absolutely amazing!",
"The product quality was terrible.",
"I feel neutral about this experience."
]
for review in reviews:
sentiment = sia.polarity_scores(review)
print(f"Review: {review}")
print(f"Sentiment: {sentiment}")
if sentiment['compound'] >= 0.05:
print("Positive review")
elif sentiment['compound'] <= -0.05:
print("Negative review")
else:
print("Neutral review")
print()
2. 텍스트 요약(Text Summarization)
NLTK를 사용하여 긴 문서의 추출적 요약(extractive summarization)을 구현할 수 있습니다.
import nltk
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
from nltk.probability import FreqDist
from heapq import nlargest
def summarize(text, n=3):
sentences = sent_tokenize(text)
# 불용어 제거
stop_words = set(stopwords.words('english'))
words = word_tokenize(text.lower())
words = [word for word in words if word.isalnum() and word not in stop_words]
# 단어 빈도 계산
freq = FreqDist(words)
# 문장 점수 계산
ranking = {}
for i, sentence in enumerate(sentences):
for word in word_tokenize(sentence.lower()):
if word in freq:
if i in ranking:
ranking[i] += freq[word]
else:
ranking[i] = freq[word]
# 상위 n개 문장 선택
indexes = nlargest(n, ranking, key=ranking.get)
return [sentences[i] for i in sorted(indexes)]
text = """Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. The goal is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves."""
summary = summarize(text, 2)
print("\n".join(summary))
3. 텍스트 분류(Text Classification)
NLTK를 사용하여 스팸 메일 분류와 같은 텍스트 분류 작업을 수행할 수 있습니다.
import nltk
from nltk.corpus import movie_reviews
from nltk.classify import NaiveBayesClassifier
from nltk.classify.util import accuracy
nltk.download('movie_reviews')
# 특성 추출 함수
def extract_features(words):
return dict([(word, True) for word in words])
# 데이터 준비
positive_ids = movie_reviews.fileids('pos')
negative_ids = movie_reviews.fileids('neg')
positive_features = [(extract_features(movie_reviews.words(fileids=[id])), 'pos') for id in positive_ids]
negative_features = [(extract_features(movie_reviews.words(fileids=[id])), 'neg') for id in negative_ids]
# 학습 데이터와 테스트 데이터 분리
train_set = positive_features[:800] + negative_features[:800]
test_set = positive_features[800:] + negative_features[800:]
# 분류기 학습
classifier = NaiveBayesClassifier.train(train_set)
# 정확도 평가
print("Accuracy:", accuracy(classifier, test_set))
# 가장 중요한 특성 확인
classifier.show_most_informative_features(10)
import nltk
from nltk.corpus import movie_reviews
from nltk.classify import NaiveBayesClassifier
from nltk.classify.util import accuracy
nltk.download('movie_reviews')
# 특성 추출 함수
def extract_features(words):
return dict([(word, True) for word in words])
# 데이터 준비
positive_ids = movie_reviews.fileids('pos')
negative_ids = movie_reviews.fileids('neg')
positive_features = [(extract_features(movie_reviews.words(fileids=[id])), 'pos') for id in positive_ids]
negative_features = [(extract_features(movie_reviews.words(fileids=[id])), 'neg') for id in negative_ids]
# 학습 데이터와 테스트 데이터 분리
train_set = positive_features[:800] + negative_features[:800]
test_set = positive_features[800:] + negative_features[800:]
# 분류기 학습
classifier = NaiveBayesClassifier.train(train_set)
# 정확도 평가
print("Accuracy:", accuracy(classifier, test_set))
# 가장 중요한 특성 확인
classifier.show_most_informative_features(10)
결론
NLTK는 자연어 처리를 위한 강력하고 다양한 도구를 제공하는 파이썬 라이브러리입니다. 토큰화, 품사 태깅, 개체명 인식 등의 기본 기능부터 감정 분석, 텍스트 요약, 텍스트 분류와 같은 고급 응용까지 폭넓은 NLP 작업을 수행할 수 있습니다.
초보자부터 전문가까지 쉽게 사용할 수 있는 인터페이스와 풍부한 문서화, 그리고 활발한 커뮤니티 지원으로 NLTK는 자연어 처리를 배우고 실제 프로젝트에 적용하기에 최적의 도구입니다. 특히 교육 및 연구 목적으로 설계되었기 때문에, NLP의 개념을 이해하고 실험하기에 매우 적합합니다.
다만, 대규모 프로덕션 환경에서는 처리 속도 측면에서 spaCy나 Transformers와 같은 다른 라이브러리가 더 효율적일 수 있습니다. 그럼에도 NLTK는 자연어 처리의 기초를 배우고 다양한 NLP 기법을 실험하는 데 있어 여전히 최고의 선택 중 하나입니다.
답글 남기기